 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation of human motion achieves natural head movements for humanoid robots in an active-speaker detection task
Jul 16, 2024Head movements are crucial for social human-human interaction. They can transmit important cues (e.g., joint attention, speaker detection) that cannot be achieved with verbal interaction alone. This advantage also holds for human-robot interaction. Even though modeling human motions through generative AI models has become an active research area within robotics in recent years, the use of these methods for producing head movements in human-robot interaction remains underexplored. In this work, we employed a generative AI pipeline to produce human-like head movements for a Nao humanoid robot. In addition, we tested the system on a real-time active-speaker tracking task in a group conversation setting. Overall, the results show that the Nao robot successfully imitates human head movements in a natural manner while actively tracking the speakers during the conversation. Code and data from this study are available at https://github.com/dingdingding60/Humanoids2024HRI
Learning secondary tool affordances of human partners using iCub robot's egocentric data
Jul 16, 2024



Objects, in particular tools, provide several action possibilities to the agents that can act on them, which are generally associated with the term of affordances. A tool is typically designed for a specific purpose, such as driving a nail in the case of a hammer, which we call as the primary affordance. A tool can also be used beyond its primary purpose, in which case we can associate this auxiliary use with the term secondary affordance. Previous work on affordance perception and learning has been mostly focused on primary affordances. Here, we address the less explored problem of learning the secondary tool affordances of human partners. To do this, we use the iCub robot to observe human partners with three cameras while they perform actions on twenty objects using four different tools. In our experiments, human partners utilize tools to perform actions that do not correspond to their primary affordances. For example, the iCub robot observes a human partner using a ruler for pushing, pulling, and moving objects instead of measuring their lengths. In this setting, we constructed a dataset by taking images of objects before and after each action is executed. We then model learning secondary affordances by training three neural networks (ResNet-18, ResNet-50, and ResNet-101) each on three tasks, using raw images showing the `initial' and `final' position of objects as input: (1) predicting the tool used to move an object, (2) predicting the tool used with an additional categorical input that encoded the action performed, and (3) joint prediction of both tool used and action performed. Our results indicate that deep learning architectures enable the iCub robot to predict secondary tool affordances, thereby paving the road for human-robot collaborative object manipulation involving complex affordances.
From Human to Robot Interactions: A Circular Approach towards Trustworthy Social Robots
Nov 14, 2023Human trust research uncovered important catalysts for trust building between interaction partners such as appearance or cognitive factors. The introduction of robots into social interactions calls for a reevaluation of these findings and also brings new challenges and opportunities. In this paper, we suggest approaching trust research in a circular way by drawing from human trust findings, validating them and conceptualizing them for robots, and finally using the precise manipulability of robots to explore previously less-explored areas of trust formation to generate new hypotheses for trust building between agents.
Challenges in Designing Teacher Robots with Motivation Based Gestures
Feb 08, 2023

Humanoid robots are increasingly being integrated into learning contexts to assist teaching and learning. However, challenges remain how to design and incorporate such robots in an educational context. As an important part of teaching includes monitoring the motivational and emotional state of the learner and adapting the interaction style and learning content accordingly, in this paper, we discuss the role of gestures displayed by a humanoid robot (i.e., Pepper robot) in a learning and teaching context and present our ongoing research on designing and developing a teacher robot.
iCub! Do you recognize what I am doing?: multimodal human action recognition on multisensory-enabled iCub robot
Dec 17, 2022



This study uses multisensory data (i.e., color and depth) to recognize human actions in the context of multimodal human-robot interaction. Here we employed the iCub robot to observe the predefined actions of the human partners by using four different tools on 20 objects. We show that the proposed multimodal ensemble learning leverages complementary characteristics of three color cameras and one depth sensor that improves, in most cases, recognition accuracy compared to the models trained with a single modality. The results indicate that the proposed models can be deployed on the iCub robot that requires multimodal action recognition, including social tasks such as partner-specific adaptation, and contextual behavior understanding, to mention a few.
A Multisensory Learning Architecture for Rotation-invariant Object Recognition
Sep 14, 2020
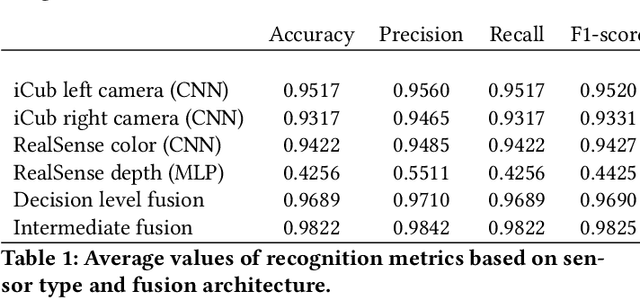


This study presents a multisensory machine learning architecture for object recognition by employing a novel dataset that was constructed with the iCub robot, which is equipped with three cameras and a depth sensor. The proposed architecture combines convolutional neural networks to form representations (i.e., features) for grayscaled color images and a multi-layer perceptron algorithm to process depth data. To this end, we aimed to learn joint representations of different modalities (e.g., color and depth) and employ them for recognizing objects. We evaluate the performance of the proposed architecture by benchmarking the results obtained with the models trained separately with the input of different sensors and a state-of-the-art data fusion technique, namely decision level fusion. The results show that our architecture improves the recognition accuracy compared with the models that use inputs from a single modality and decision level multimodal fusion method.
The iCub multisensor datasets for robot and computer vision applications
Mar 04, 2020



This document presents novel datasets, constructed by employing the iCub robot equipped with an additional depth sensor and color camera. We used the robot to acquire color and depth information for 210 objects in different acquisition scenarios. At this end, the results were large scale datasets for robot and computer vision applications: object representation, object recognition and classification, and action recognition.