 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multisensory Learning Architecture for Rotation-invariant Object Recognition
Paper and Code
Sep 14, 2020
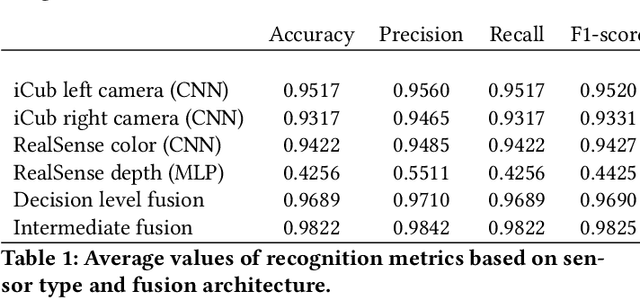


This study presents a multisensory machine learning architecture for object recognition by employing a novel dataset that was constructed with the iCub robot, which is equipped with three cameras and a depth sensor. The proposed architecture combines convolutional neural networks to form representations (i.e., features) for grayscaled color images and a multi-layer perceptron algorithm to process depth data. To this end, we aimed to learn joint representations of different modalities (e.g., color and depth) and employ them for recognizing objects. We evaluate the performance of the proposed architecture by benchmarking the results obtained with the models trained separately with the input of different sensors and a state-of-the-art data fusion technique, namely decision level fusion. The results show that our architecture improves the recognition accuracy compared with the models that use inputs from a single modality and decision level multimodal fusion method.