 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianOcc3D: A Gaussian-Based Adaptive Multi-modal 3D Occupancy Prediction
Jan 30, 20263D semantic occupancy prediction is a pivotal task in autonomous driving, providing a dense and fine-grained understanding of the surrounding environment, yet single-modality methods face trade-offs between camera semantics and LiDAR geometry. Existing multi-modal frameworks often struggle with modality heterogeneity, spatial misalignment, and the representation crisis--where voxels are computationally heavy and BEV alternatives are lossy. We present GaussianOcc3D, a multi-modal framework bridging camera and LiDAR through a memory-efficient, continuous 3D Gaussian representation. We introduce four modules: (1) LiDAR Depth Feature Aggregation (LDFA), using depth-wise deformable sampling to lift sparse signals onto Gaussian primitives; (2) Entropy-Based Feature Smoothing (EBFS) to mitigate domain noise; (3) Adaptive Camera-LiDAR Fusion (ACLF) with uncertainty-aware reweighting for sensor reliability; and (4) a Gauss-Mamba Head leveraging Selective State Space Models for global context with linear complexity. Evaluations on Occ3D, SurroundOcc, and SemanticKITTI benchmarks demonstrate state-of-the-art performance, achieving mIoU scores of 49.4%, 28.9%, and 25.2% respectively. GaussianOcc3D exhibits superior robustness across challenging rainy and nighttime conditions.
X2BR: High-Fidelity 3D Bone Reconstruction from a Planar X-Ray Image with Hybrid Neural Implicit Methods
Apr 11, 2025



Accurate 3D bone reconstruction from a single planar X-ray remains a challenge due to anatomical complexity and limited input data. We propose X2BR, a hybrid neural implicit framework that combines continuous volumetric reconstruction with template-guided non-rigid registration. The core network, X2B, employs a ConvNeXt-based encoder to extract spatial features from X-rays and predict high-fidelity 3D bone occupancy fields without relying on statistical shape models. To further refine anatomical accuracy, X2BR integrates a patient-specific template mesh, constructed using YOLOv9-based detection and the SKEL biomechanical skeleton model. The coarse reconstruction is aligned to the template using geodesic-based coherent point drift, enabling anatomically consistent 3D bone volumes. Experimental results on a clinical dataset show that X2B achieves the highest numerical accuracy, with an IoU of 0.952 and Chamfer-L1 distance of 0.005, outperforming recent baselines including X2V and D2IM-Net. Building on this, X2BR incorporates anatomical priors via YOLOv9-based bone detection and biomechanical template alignment, leading to reconstructions that, while slightly lower in IoU (0.875), offer superior anatomical realism, especially in rib curvature and vertebral alignment. This numerical accuracy vs. visual consistency trade-off between X2B and X2BR highlights the value of hybrid frameworks for clinically relevant 3D reconstructions.
TransAdapter: Vision Transformer for Feature-Centric Unsupervised Domain Adaptation
Dec 05, 2024



Unsupervised Domain Adaptation (UDA) aims to utilize labeled data from a source domain to solve tasks in an unlabeled target domain, often hindered by significant domain gaps. Traditional CNN-based methods struggle to fully capture complex domain relationships, motivating the shift to vision transformers like the Swin Transformer, which excel in modeling both local and global dependencies. In this work, we propose a novel UDA approach leveraging the Swin Transformer with three key modules. A Graph Domain Discriminator enhances domain alignment by capturing inter-pixel correlations through graph convolutions and entropy-based attention differentiation. An Adaptive Double Attention module combines Windows and Shifted Windows attention with dynamic reweighting to align long-range and local features effectively. Finally, a Cross-Feature Transform modifies Swin Transformer blocks to improve generalization across domains. Extensive benchmarks confirm the state-of-the-art performance of our versatile method, which requires no task-specific alignment modules, establishing its adaptability to diverse applications.
XPoint: A Self-Supervised Visual-State-Space based Architecture for Multispectral Image Registration
Nov 11, 2024



Accurate multispectral image matching presents significant challenges due to non-linear intensity variations across spectral modalities, extreme viewpoint changes, and the scarcity of labeled datasets. Current state-of-the-art methods are typically specialized for a single spectral difference, such as visibleinfrared, and struggle to adapt to other modalities due to their reliance on expensive supervision, such as depth maps or camera poses. To address the need for rapid adaptation across modalities, we introduce XPoint, a self-supervised, modular image-matching framework designed for adaptive training and fine-tuning on aligned multispectral datasets, allowing users to customize key components based on their specific tasks. XPoint employs modularity and self-supervision to allow for the adjustment of elements such as the base detector, which generates pseudoground truth keypoints invariant to viewpoint and spectrum variations. The framework integrates a VMamba encoder, pretrained on segmentation tasks, for robust feature extraction, and includes three joint decoder heads: two are dedicated to interest point and descriptor extraction; and a task-specific homography regression head imposes geometric constraints for superior performance in tasks like image registration. This flexible architecture enables quick adaptation to a wide range of modalities, demonstrated by training on Optical-Thermal data and fine-tuning on settings such as visual-near infrared, visual-infrared, visual-longwave infrared, and visual-synthetic aperture radar. Experimental results show that XPoint consistently outperforms or matches state-ofthe-art methods in feature matching and image registration tasks across five distinct multispectral datasets. Our source code is available at https://github.com/canyagmur/XPoint.
Deep learning-based blind image super-resolution with iterative kernel reconstruction and noise estimation
Apr 25, 2024



Blind single image super-resolution (SISR) is a challenging task in image processing due to the ill-posed nature of the inverse problem. Complex degradations present in real life images make it difficult to solve this problem using na\"ive deep learning approaches, where models are often trained on synthetically generated image pairs. Most of the effort so far has been focused on solving the inverse problem under some constraints, such as for a limited space of blur kernels and/or assuming noise-free input images. Yet, there is a gap in the literature to provide a well-generalized deep learning-based solution that performs well on images with unknown and highly complex degradations. In this paper, we propose IKR-Net (Iterative Kernel Reconstruction Network) for blind SISR. In the proposed approach, kernel and noise estimation and high-resolution image reconstruction are carried out iteratively using dedicated deep models. The iterative refinement provides significant improvement in both the reconstructed image and the estimated blur kernel even for noisy inputs. IKR-Net provides a generalized solution that can handle any type of blur and level of noise in the input low-resolution image. IKR-Net achieves state-of-the-art results in blind SISR, especially for noisy images with motion blur.
* 17 pages, 13 figures. The code of this paper is available in github: https://github.com/hfates/IKR-Net
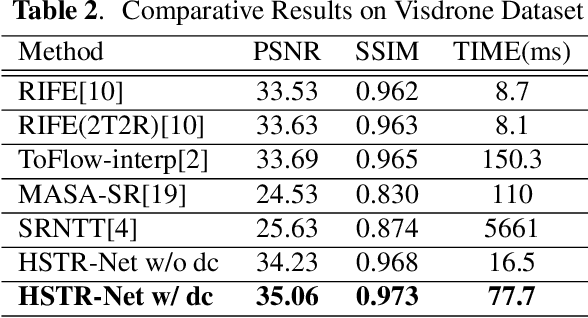
HSTR-Net: Reference Based Video Super-resolution for Aerial Surveillance with Dual Cameras
Oct 18, 2023Aerial surveillance requires high spatio-temporal resolution (HSTR) video for more accurate detection and tracking of objects. This is especially true for wide-area surveillance (WAS), where the surveyed region is large and the objects of interest are small. This paper proposes a dual camera system for the generation of HSTR video using reference-based super-resolution (RefSR). One camera captures high spatial resolution low frame rate (HSLF) video while the other captures low spatial resolution high frame rate (LSHF) video simultaneously for the same scene. A novel deep learning architecture is proposed to fuse HSLF and LSHF video feeds and synthesize HSTR video frames at the output. The proposed model combines optical flow estimation and (channel-wise and spatial) attention mechanisms to capture the fine motion and intricate dependencies between frames of the two video feeds. Simulations show that the proposed model provides significant improvement over existing reference-based SR techniques in terms of PSNR and SSIM metrics. The method also exhibits sufficient frames per second (FPS) for WAS when deployed on a power-constrained drone equipped with dual cameras.
HSTR-Net: High Spatio-Temporal Resolution Video Generation For Wide Area Surveillance
Apr 09, 2022

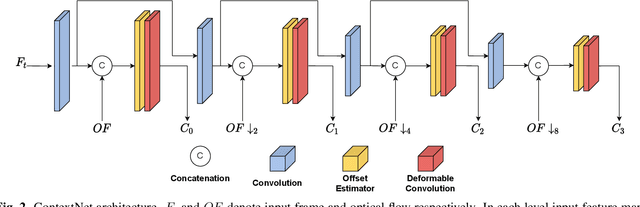
Wide area surveillance has many applications and tracking of objects under observation is an important task, which often needs high spatio-temporal resolution (HSTR) video for better precision. This paper presents the usage of multiple video feeds for the generation of HSTR video as an extension of reference based super resolution (RefSR). One feed captures video at high spatial resolution with low frame rate (HSLF) while the other captures low spatial resolution and high frame rate (LSHF) video simultaneously for the same scene. The main purpose is to create an HSTR video from the fusion of HSLF and LSHF videos. In this paper we propose an end-to-end trainable deep network that performs optical flow estimation and frame reconstruction by combining inputs from both video feeds. The proposed architecture provides significant improvement over existing video frame interpolation and RefSR techniques in terms of objective PSNR and SSIM metrics.
Altitude Optimization of UAV Base Stations from Satellite Images Using Deep Neural Network
Dec 29, 2021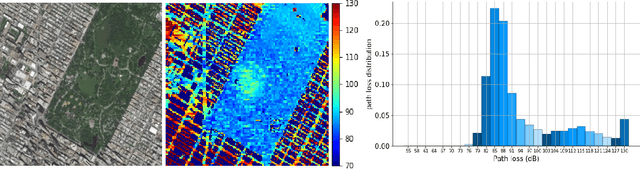
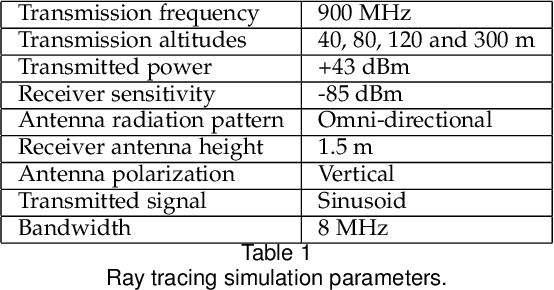
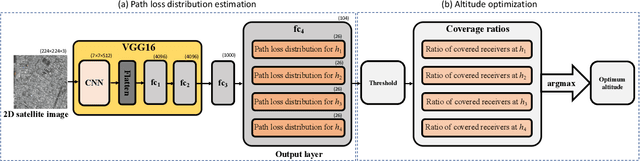
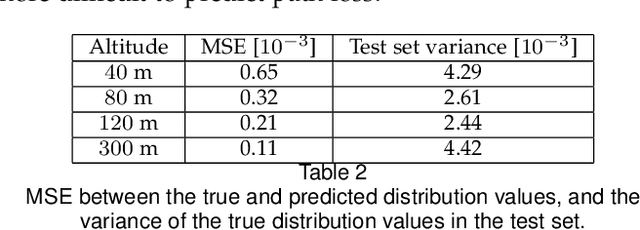
It is expected that unmanned aerial vehicles (UAVs) will play a vital role in future communication systems. Optimum positioning of UAVs, serving as base stations, can be done through extensive field measurements or ray tracing simulations when the 3D model of the region of interest is available. In this paper, we present an alternative approach to optimize UAV base station altitude for a region. The approach is based on deep learning; specifically, a 2D satellite image of the target region is input to a deep neural network to predict path loss distributions for different UAV altitudes. The predicted path distributions are used to calculate the coverage in the region; and the optimum altitude, maximizing the coverage, is determined. The neural network is designed and trained to produce multiple path loss distributions in a single inference; thus, it is not necessary to train a separate network for each altitude.
HM-Net: A Regression Network for Object Center Detection and Tracking on Wide Area Motion Imagery
Oct 19, 2021



Wide Area Motion Imagery (WAMI) yields high resolution images with a large number of extremely small objects. Target objects have large spatial displacements throughout consecutive frames. This nature of WAMI images makes object tracking and detection challenging. In this paper, we present our deep neural network-based combined object detection and tracking model, namely, Heat Map Network (HM-Net). HM-Net is significantly faster than state-of-the-art frame differencing and background subtraction-based methods, without compromising detection and tracking performances. HM-Net follows object center-based joint detection and tracking paradigm. Simple heat map-based predictions support unlimited number of simultaneous detections. The proposed method uses two consecutive frames and the object detection heat map obtained from the previous frame as input, which helps HM-Net monitor spatio-temporal changes between frames and keeps track of previously predicted objects. Although reuse of prior object detection heat map acts as a vital feedback-based memory element, it can lead to unintended surge of false positive detections. To increase robustness of the method against false positives and to eliminate low confidence detections, HM-Net employs novel feedback filters and advanced data augmentations. HM-Net outperforms state-of-the-art WAMI moving object detection and tracking methods on WPAFB dataset with its 96.2% F1 and 94.4% mAP detection scores, while achieving a 61.8% mAP tracking score on the same dataset.
Multi-hypothesis contextual modeling for semantic segmentation
Dec 14, 2018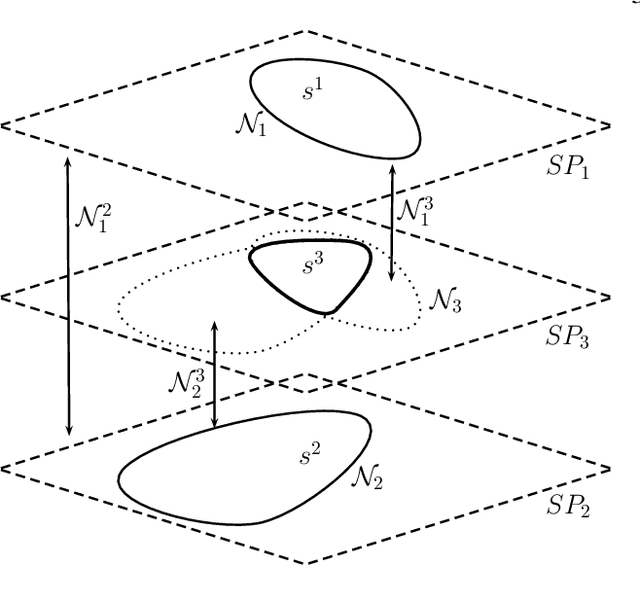
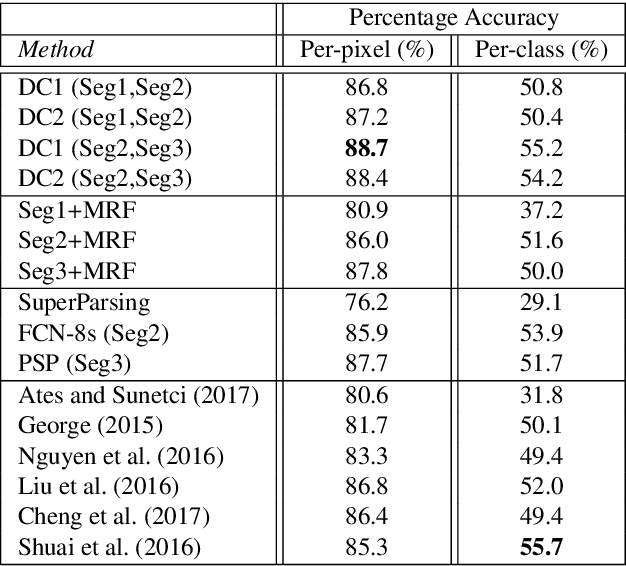
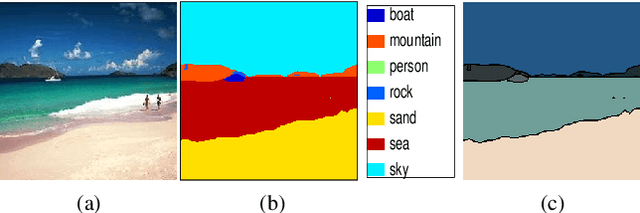
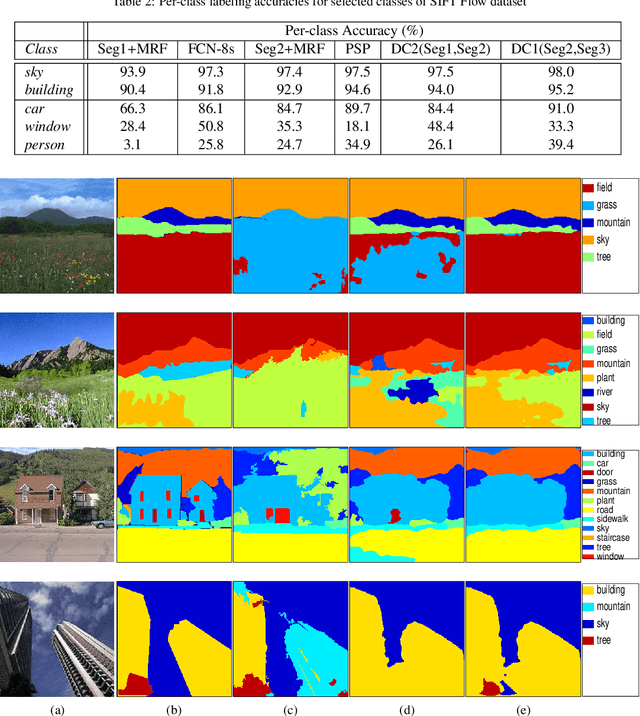
Semantic segmentation (i.e. image parsing) aims to annotate each image pixel with its corresponding semantic class label. Spatially consistent labeling of the image requires an accurate description and modeling of the local contextual information. Segmentation result is typically improved by Markov Random Field (MRF) optimization on the initial labels. However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we develop generalized and flexible contextual models for segmentation neighborhoods in order to improve parsing accuracy. Instead of using a fixed segmentation and neighborhood definition, we explore various contextual models for fusion of complementary information available in alternative segmentations of the same image. In other words, we propose a novel MRF framework that describes and optimizes the contextual dependencies between multiple segmentations. Simulation results on two common datasets demonstrate significant improvement in parsing accuracy over the baseline approaches.