 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-hypothesis contextual modeling for semantic segmentation
Dec 14, 2018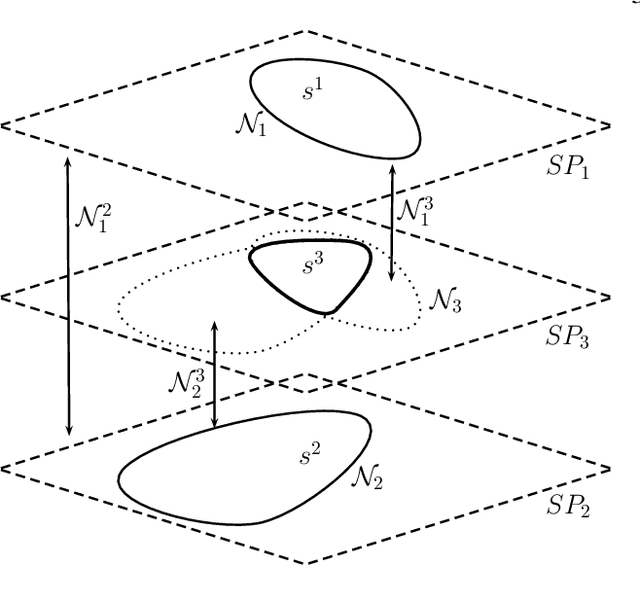
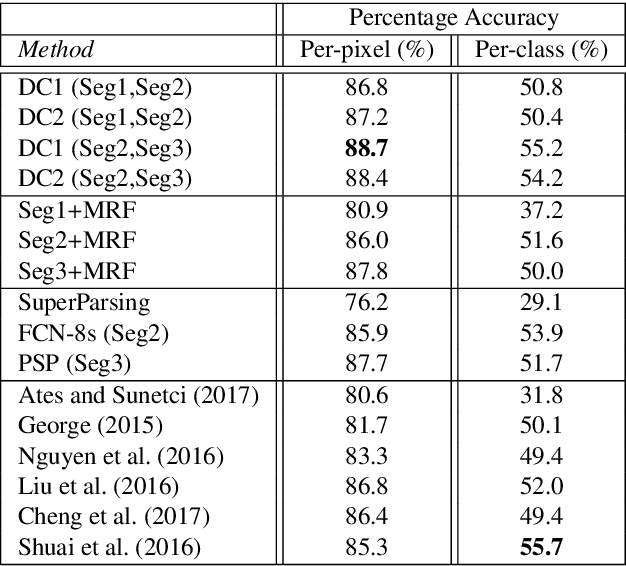
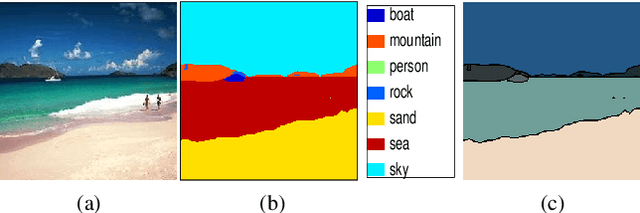
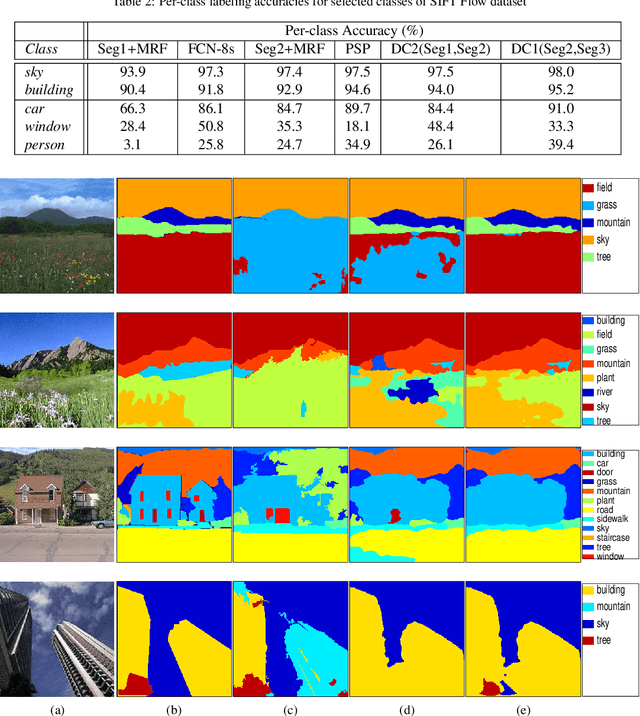
Semantic segmentation (i.e. image parsing) aims to annotate each image pixel with its corresponding semantic class label. Spatially consistent labeling of the image requires an accurate description and modeling of the local contextual information. Segmentation result is typically improved by Markov Random Field (MRF) optimization on the initial labels. However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we develop generalized and flexible contextual models for segmentation neighborhoods in order to improve parsing accuracy. Instead of using a fixed segmentation and neighborhood definition, we explore various contextual models for fusion of complementary information available in alternative segmentations of the same image. In other words, we propose a novel MRF framework that describes and optimizes the contextual dependencies between multiple segmentations. Simulation results on two common datasets demonstrate significant improvement in parsing accuracy over the baseline approaches.