 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuildMamba: A Visual State-Space Based Model for Multi-Task Building Segmentation and Height Estimation from Satellite Images
Mar 09, 2026Accurate building segmentation and height estimation from single-view RGB satellite imagery are fundamental for urban analytics, yet remain ill-posed due to structural variability and the high computational cost of global context modeling. While current approaches typically adapt monocular depth architectures, they often suffer from boundary bleeding and systematic underestimation of high-rise structures. To address these limitations, we propose BuildMamba, a unified multi-task framework designed to exploit the linear-time global modeling of visual state-space models. Motivated by the need for stronger structural coupling and computational efficiency, we introduce three modules: a Mamba Attention Module for dynamic spatial recalibration, a Spatial-Aware Mamba-FPN for multi-scale feature aggregation via gated state-space scans, and a Mask-Aware Height Refinement module using semantic priors to suppress height artifacts. Extensive experiments demonstrate that BuildMamba establishes a new performance upper bound across three benchmarks. Specifically, it achieves an IoU of 0.93 and RMSE of 1.77~m on DFC23 benchmark, surpassing state-of-the-art by 0.82~m in height estimation. Simulation results confirm the model's superior robustness and scalability for large-scale 3D urban reconstruction.
XPoint: A Self-Supervised Visual-State-Space based Architecture for Multispectral Image Registration
Nov 11, 2024



Accurate multispectral image matching presents significant challenges due to non-linear intensity variations across spectral modalities, extreme viewpoint changes, and the scarcity of labeled datasets. Current state-of-the-art methods are typically specialized for a single spectral difference, such as visibleinfrared, and struggle to adapt to other modalities due to their reliance on expensive supervision, such as depth maps or camera poses. To address the need for rapid adaptation across modalities, we introduce XPoint, a self-supervised, modular image-matching framework designed for adaptive training and fine-tuning on aligned multispectral datasets, allowing users to customize key components based on their specific tasks. XPoint employs modularity and self-supervision to allow for the adjustment of elements such as the base detector, which generates pseudoground truth keypoints invariant to viewpoint and spectrum variations. The framework integrates a VMamba encoder, pretrained on segmentation tasks, for robust feature extraction, and includes three joint decoder heads: two are dedicated to interest point and descriptor extraction; and a task-specific homography regression head imposes geometric constraints for superior performance in tasks like image registration. This flexible architecture enables quick adaptation to a wide range of modalities, demonstrated by training on Optical-Thermal data and fine-tuning on settings such as visual-near infrared, visual-infrared, visual-longwave infrared, and visual-synthetic aperture radar. Experimental results show that XPoint consistently outperforms or matches state-ofthe-art methods in feature matching and image registration tasks across five distinct multispectral datasets. Our source code is available at https://github.com/canyagmur/XPoint.
Deep learning-based blind image super-resolution with iterative kernel reconstruction and noise estimation
Apr 25, 2024



Blind single image super-resolution (SISR) is a challenging task in image processing due to the ill-posed nature of the inverse problem. Complex degradations present in real life images make it difficult to solve this problem using na\"ive deep learning approaches, where models are often trained on synthetically generated image pairs. Most of the effort so far has been focused on solving the inverse problem under some constraints, such as for a limited space of blur kernels and/or assuming noise-free input images. Yet, there is a gap in the literature to provide a well-generalized deep learning-based solution that performs well on images with unknown and highly complex degradations. In this paper, we propose IKR-Net (Iterative Kernel Reconstruction Network) for blind SISR. In the proposed approach, kernel and noise estimation and high-resolution image reconstruction are carried out iteratively using dedicated deep models. The iterative refinement provides significant improvement in both the reconstructed image and the estimated blur kernel even for noisy inputs. IKR-Net provides a generalized solution that can handle any type of blur and level of noise in the input low-resolution image. IKR-Net achieves state-of-the-art results in blind SISR, especially for noisy images with motion blur.
* 17 pages, 13 figures. The code of this paper is available in github: https://github.com/hfates/IKR-Net
HSTR-Net: Reference Based Video Super-resolution for Aerial Surveillance with Dual Cameras
Oct 18, 2023Aerial surveillance requires high spatio-temporal resolution (HSTR) video for more accurate detection and tracking of objects. This is especially true for wide-area surveillance (WAS), where the surveyed region is large and the objects of interest are small. This paper proposes a dual camera system for the generation of HSTR video using reference-based super-resolution (RefSR). One camera captures high spatial resolution low frame rate (HSLF) video while the other captures low spatial resolution high frame rate (LSHF) video simultaneously for the same scene. A novel deep learning architecture is proposed to fuse HSLF and LSHF video feeds and synthesize HSTR video frames at the output. The proposed model combines optical flow estimation and (channel-wise and spatial) attention mechanisms to capture the fine motion and intricate dependencies between frames of the two video feeds. Simulations show that the proposed model provides significant improvement over existing reference-based SR techniques in terms of PSNR and SSIM metrics. The method also exhibits sufficient frames per second (FPS) for WAS when deployed on a power-constrained drone equipped with dual cameras.
HSTR-Net: High Spatio-Temporal Resolution Video Generation For Wide Area Surveillance
Apr 09, 2022

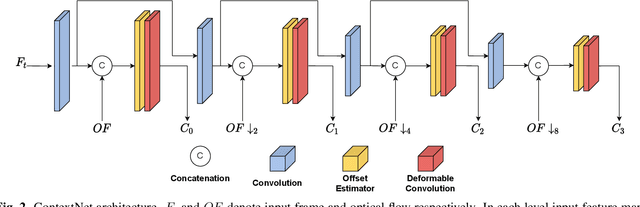
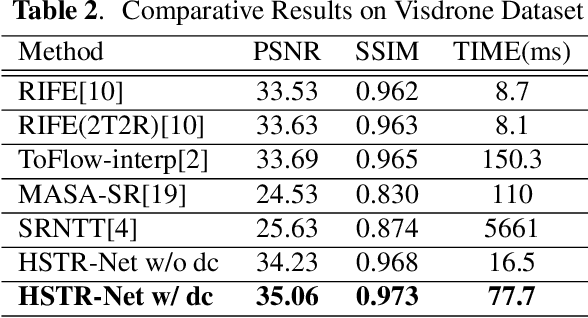
Wide area surveillance has many applications and tracking of objects under observation is an important task, which often needs high spatio-temporal resolution (HSTR) video for better precision. This paper presents the usage of multiple video feeds for the generation of HSTR video as an extension of reference based super resolution (RefSR). One feed captures video at high spatial resolution with low frame rate (HSLF) while the other captures low spatial resolution and high frame rate (LSHF) video simultaneously for the same scene. The main purpose is to create an HSTR video from the fusion of HSLF and LSHF videos. In this paper we propose an end-to-end trainable deep network that performs optical flow estimation and frame reconstruction by combining inputs from both video feeds. The proposed architecture provides significant improvement over existing video frame interpolation and RefSR techniques in terms of objective PSNR and SSIM metrics.
Altitude Optimization of UAV Base Stations from Satellite Images Using Deep Neural Network
Dec 29, 2021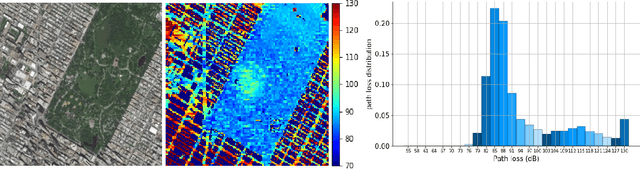
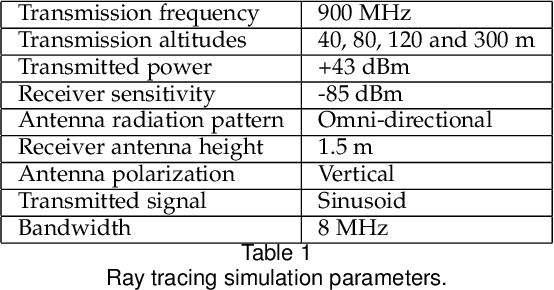
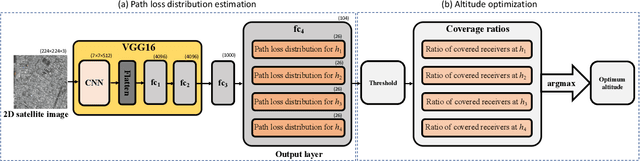
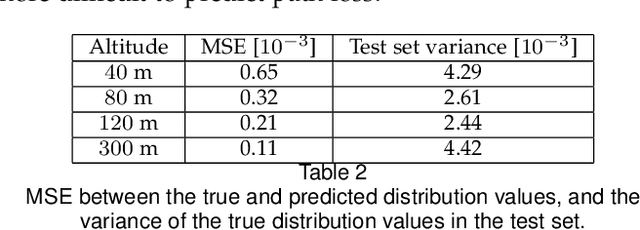
It is expected that unmanned aerial vehicles (UAVs) will play a vital role in future communication systems. Optimum positioning of UAVs, serving as base stations, can be done through extensive field measurements or ray tracing simulations when the 3D model of the region of interest is available. In this paper, we present an alternative approach to optimize UAV base station altitude for a region. The approach is based on deep learning; specifically, a 2D satellite image of the target region is input to a deep neural network to predict path loss distributions for different UAV altitudes. The predicted path distributions are used to calculate the coverage in the region; and the optimum altitude, maximizing the coverage, is determined. The neural network is designed and trained to produce multiple path loss distributions in a single inference; thus, it is not necessary to train a separate network for each altitude.
Light field super resolution through controlled micro-shifts of light field sensor
Jun 10, 2018


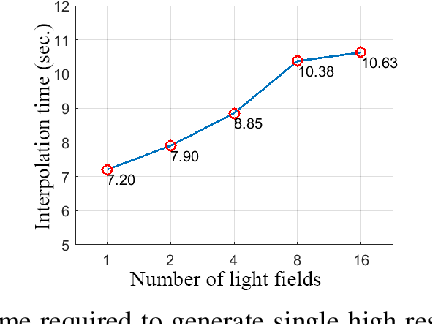
Light field cameras enable new capabilities, such as post-capture refocusing and aperture control, through capturing directional and spatial distribution of light rays in space. Micro-lens array based light field camera design is often preferred due to its light transmission efficiency, cost-effectiveness and compactness. One drawback of the micro-lens array based light field cameras is low spatial resolution due to the fact that a single sensor is shared to capture both spatial and angular information. To address the low spatial resolution issue, we present a light field imaging approach, where multiple light fields are captured and fused to improve the spatial resolution. For each capture, the light field sensor is shifted by a pre-determined fraction of a micro-lens size using an XY translation stage for optimal performance.
Extracting Sub-Exposure Images from a Single Capture Through Fourier-based Optical Modulation
Feb 13, 2018

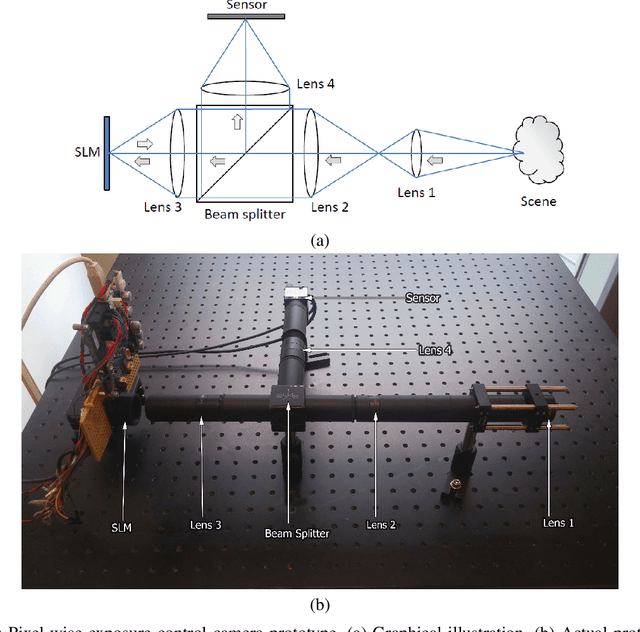

Through pixel-wise optical coding of images during exposure time, it is possible to extract sub-exposure images from a single capture. Such a capability can be used for different purposes, including high-speed imaging, high-dynamic-range imaging and compressed sensing. In this paper, we demonstrate a sub-exposure image extraction method, where the exposure coding pattern is inspired from frequency division multiplexing idea of communication systems. The coding masks modulate sub-exposure images in such a way that they are placed in non-overlapping regions in Fourier domain. The sub-exposure image extraction process involves digital filtering of the captured signal with proper band-pass filters. The prototype imaging system incorporates a Liquid Crystal over Silicon (LCoS) based spatial light modulator synchronized with a camera for pixel-wise exposure coding.
Spatial and Angular Resolution Enhancement of Light Fields Using Convolutional Neural Networks
Feb 13, 2018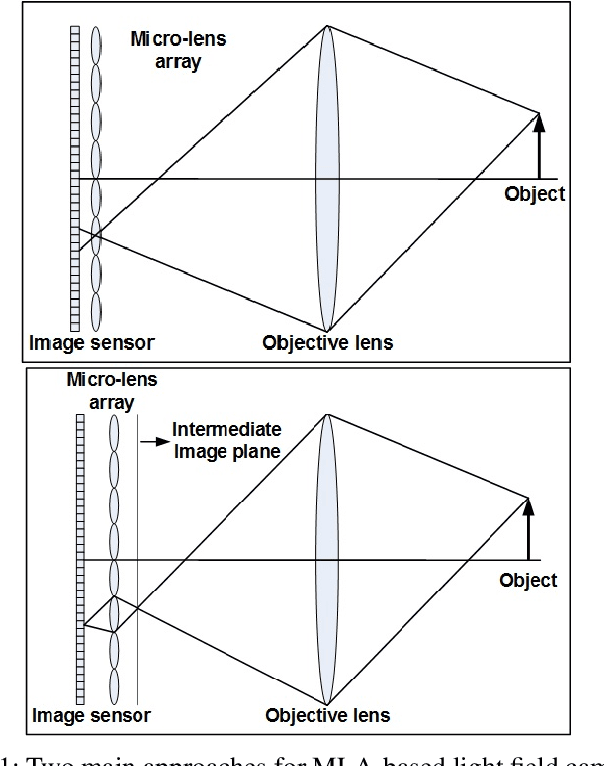



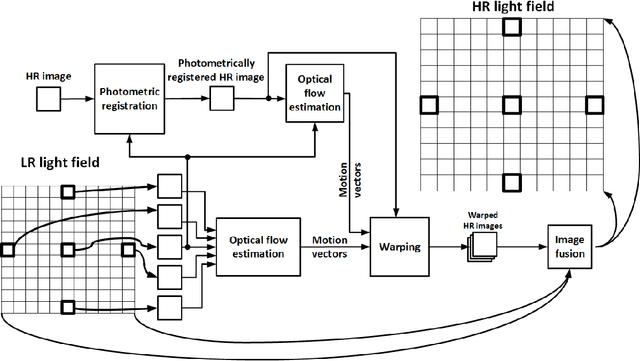
Light field imaging extends the traditional photography by capturing both spatial and angular distribution of light, which enables new capabilities, including post-capture refocusing, post-capture aperture control, and depth estimation from a single shot. Micro-lens array (MLA) based light field cameras offer a cost-effective approach to capture light field. A major drawback of MLA based light field cameras is low spatial resolution, which is due to the fact that a single image sensor is shared to capture both spatial and angular information. In this paper, we present a learning based light field enhancement approach. Both spatial and angular resolution of captured light field is enhanced using convolutional neural networks. The proposed method is tested with real light field data captured with a Lytro light field camera, clearly demonstrating spatial and angular resolution improvement.
Hybrid Light Field Imaging for Improved Spatial Resolution and Depth Range
Jul 31, 2017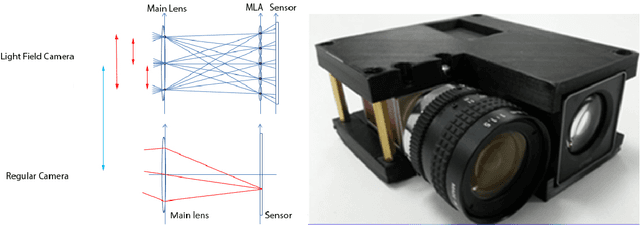

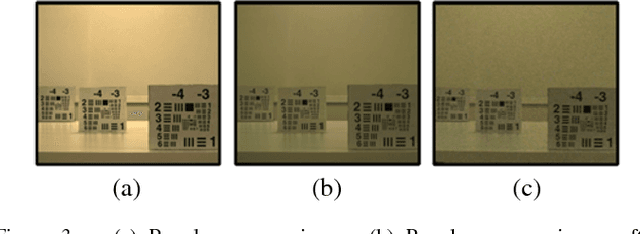
Light field imaging involves capturing both angular and spatial distribution of light; it enables new capabilities, such as post-capture digital refocusing, camera aperture adjustment, perspective shift, and depth estimation. Micro-lens array (MLA) based light field cameras provide a cost-effective approach to light field imaging. There are two main limitations of MLA-based light field cameras: low spatial resolution and narrow baseline. While low spatial resolution limits the general purpose use and applicability of light field cameras, narrow baseline limits the depth estimation range and accuracy. In this paper, we present a hybrid stereo imaging system that includes a light field camera and a regular camera. The hybrid system addresses both spatial resolution and narrow baseline issues of the MLA-based light field cameras while preserving light field imaging capabilities.