 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Annotation Consensus for Continuous Emotion Recognition
May 27, 2025In affective computing, datasets often contain multiple annotations from different annotators, which may lack full agreement. Typically, these annotations are merged into a single gold standard label, potentially losing valuable inter-rater variability. We propose a multi-annotator training approach for continuous emotion recognition (CER) that seeks a consensus across all annotators rather than relying on a single reference label. Our method employs a consensus network to aggregate annotations into a unified representation, guiding the main arousal-valence predictor to better reflect collective inputs. Tested on the RECOLA and COGNIMUSE datasets, our approach outperforms traditional methods that unify annotations into a single label. This underscores the benefits of fully leveraging multi-annotator data in emotion recognition and highlights its applicability across various fields where annotations are abundant yet inconsistent.
Role of Audio in Audio-Visual Video Summarization
Dec 02, 2022



Video summarization attracts attention for efficient video representation, retrieval, and browsing to ease volume and traffic surge problems. Although video summarization mostly uses the visual channel for compaction, the benefits of audio-visual modeling appeared in recent literature. The information coming from the audio channel can be a result of audio-visual correlation in the video content. In this study, we propose a new audio-visual video summarization framework integrating four ways of audio-visual information fusion with GRU-based and attention-based networks. Furthermore, we investigate a new explainability methodology using audio-visual canonical correlation analysis (CCA) to better understand and explain the role of audio in the video summarization task. Experimental evaluations on the TVSum dataset attain F1 score and Kendall-tau score improvements for the audio-visual video summarization. Furthermore, splitting video content on TVSum and COGNIMUSE datasets based on audio-visual CCA as positively and negatively correlated videos yields a strong performance improvement over the positively correlated videos for audio-only and audio-visual video summarization.
Altitude Optimization of UAV Base Stations from Satellite Images Using Deep Neural Network
Dec 29, 2021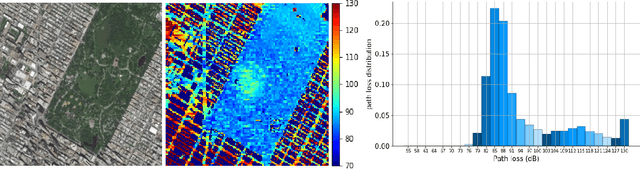
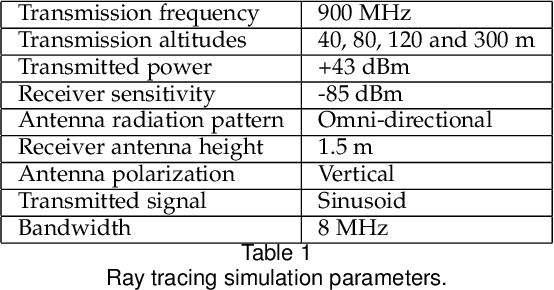
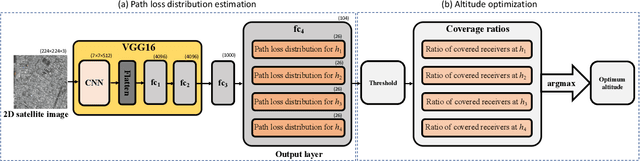
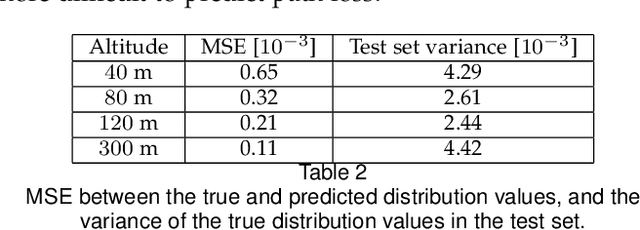
It is expected that unmanned aerial vehicles (UAVs) will play a vital role in future communication systems. Optimum positioning of UAVs, serving as base stations, can be done through extensive field measurements or ray tracing simulations when the 3D model of the region of interest is available. In this paper, we present an alternative approach to optimize UAV base station altitude for a region. The approach is based on deep learning; specifically, a 2D satellite image of the target region is input to a deep neural network to predict path loss distributions for different UAV altitudes. The predicted path distributions are used to calculate the coverage in the region; and the optimum altitude, maximizing the coverage, is determined. The neural network is designed and trained to produce multiple path loss distributions in a single inference; thus, it is not necessary to train a separate network for each altitude.