 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX2BR: High-Fidelity 3D Bone Reconstruction from a Planar X-Ray Image with Hybrid Neural Implicit Methods
Apr 11, 2025



Accurate 3D bone reconstruction from a single planar X-ray remains a challenge due to anatomical complexity and limited input data. We propose X2BR, a hybrid neural implicit framework that combines continuous volumetric reconstruction with template-guided non-rigid registration. The core network, X2B, employs a ConvNeXt-based encoder to extract spatial features from X-rays and predict high-fidelity 3D bone occupancy fields without relying on statistical shape models. To further refine anatomical accuracy, X2BR integrates a patient-specific template mesh, constructed using YOLOv9-based detection and the SKEL biomechanical skeleton model. The coarse reconstruction is aligned to the template using geodesic-based coherent point drift, enabling anatomically consistent 3D bone volumes. Experimental results on a clinical dataset show that X2B achieves the highest numerical accuracy, with an IoU of 0.952 and Chamfer-L1 distance of 0.005, outperforming recent baselines including X2V and D2IM-Net. Building on this, X2BR incorporates anatomical priors via YOLOv9-based bone detection and biomechanical template alignment, leading to reconstructions that, while slightly lower in IoU (0.875), offer superior anatomical realism, especially in rib curvature and vertebral alignment. This numerical accuracy vs. visual consistency trade-off between X2B and X2BR highlights the value of hybrid frameworks for clinically relevant 3D reconstructions.
HM-Net: A Regression Network for Object Center Detection and Tracking on Wide Area Motion Imagery
Oct 19, 2021



Wide Area Motion Imagery (WAMI) yields high resolution images with a large number of extremely small objects. Target objects have large spatial displacements throughout consecutive frames. This nature of WAMI images makes object tracking and detection challenging. In this paper, we present our deep neural network-based combined object detection and tracking model, namely, Heat Map Network (HM-Net). HM-Net is significantly faster than state-of-the-art frame differencing and background subtraction-based methods, without compromising detection and tracking performances. HM-Net follows object center-based joint detection and tracking paradigm. Simple heat map-based predictions support unlimited number of simultaneous detections. The proposed method uses two consecutive frames and the object detection heat map obtained from the previous frame as input, which helps HM-Net monitor spatio-temporal changes between frames and keeps track of previously predicted objects. Although reuse of prior object detection heat map acts as a vital feedback-based memory element, it can lead to unintended surge of false positive detections. To increase robustness of the method against false positives and to eliminate low confidence detections, HM-Net employs novel feedback filters and advanced data augmentations. HM-Net outperforms state-of-the-art WAMI moving object detection and tracking methods on WPAFB dataset with its 96.2% F1 and 94.4% mAP detection scores, while achieving a 61.8% mAP tracking score on the same dataset.
Deep Compression for PyTorch Model Deployment on Microcontrollers
Mar 29, 2021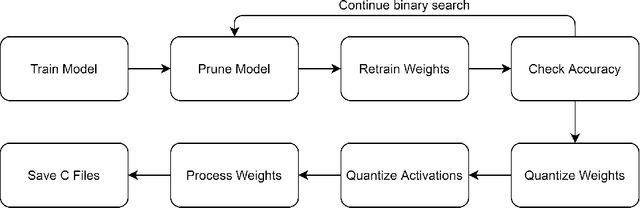

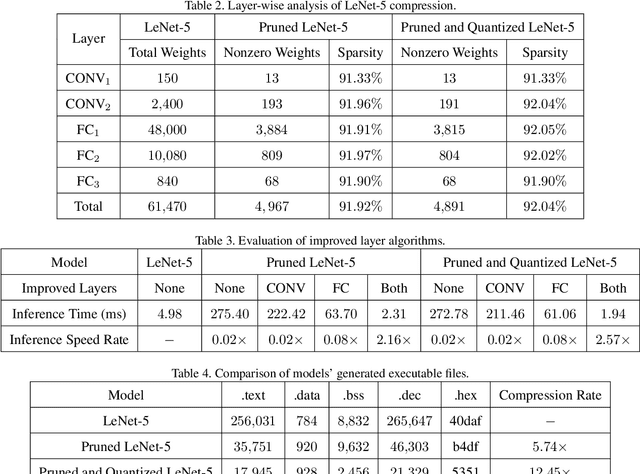
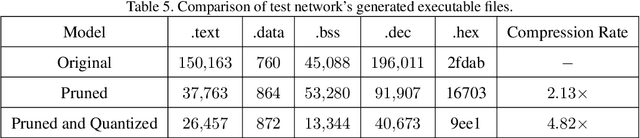
Neural network deployment on low-cost embedded systems, hence on microcontrollers (MCUs), has recently been attracting more attention than ever. Since MCUs have limited memory capacity as well as limited compute-speed, it is critical that we employ model compression, which reduces both memory and compute-speed requirements. In this paper, we add model compression, specifically Deep Compression, and further optimize Unlu's earlier work on arXiv, which efficiently deploys PyTorch models on MCUs. First, we prune the weights in convolutional and fully connected layers. Secondly, the remaining weights and activations are quantized to 8-bit integers from 32-bit floating-point. Finally, forward pass functions are compressed using special data structures for sparse matrices, which store only nonzero weights (without impacting performance and accuracy). In the case of the LeNet-5 model, the memory footprint was reduced by 12.45x, and the inference speed was boosted by 2.57x.