 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Continuum Intensity for Solar Active Region Emergence Prediction using Transformers
Jan 19, 2026Early and accurate prediction of solar active region (AR) emergence is crucial for space weather forecasting. Building on established Long Short-Term Memory (LSTM) based approaches for forecasting the continuum intensity decrease associated with AR emergence, this work expands the modeling with new architectures and targets. We investigate a sliding-window Transformer architecture to forecast continuum intensity evolution up to 12 hours ahead using data from 46 ARs observed by SDO/HMI. We conduct a systematic ablation study to evaluate two key components: (1) the inclusion of a temporal 1D convolutional (Conv1D) front-end and (2) a novel `Early Detection' architecture featuring attention biases and a timing-aware loss function. Our best-performing model, combining the Early Detection architecture without the Conv1D layer, achieved a Root Mean Square Error (RMSE) of 0.1189 (representing a 10.6% improvement over the LSTM baseline) and an average advance warning time of 4.73 hours (timing difference of -4.73h), even under a stricter emergence criterion than previous studies. While the Transformer demonstrates superior aggregate timing and accuracy, we note that this high-sensitivity detection comes with increased variance compared to smoother baseline models. However, this volatility is a necessary trade-off for operational warning systems: the model's ability to detect micro-changes in precursor signals enables significantly earlier detection, outweighing the cost of increased noise. Our results demonstrate that Transformer architectures modified with early detection biases, when used without temporal smoothing layers, provide a high-sensitivity alternative for forecasting AR emergence that prioritizes advance warning over statistical smoothness.
SolARED: Solar Active Region Emergence Dataset for Machine Learning Aided Predictions
Jan 19, 2026The development of accurate forecasts of solar eruptive activity has become increasingly important for preventing potential impacts on space technologies and exploration. Therefore, it is crucial to detect Active Regions (ARs) before they start forming on the solar surface. This will enable the development of early-warning capabilities for upcoming space weather disturbances. For this reason, we prepared the Solar Active Region Emergence Dataset (SolARED). The dataset is derived from full-disk maps of the Doppler velocity, magnetic field, and continuum intensity, obtained by the Helioseismic and Magnetic Imager (HMI) onboard the Solar Dynamics Observatory (SDO). SolARED includes time series of remapped, tracked, and binned data that characterize the evolution of acoustic power of solar oscillations, unsigned magnetic flux, and continuum intensity for 50 large ARs before, during, and after their emergence on the solar surface, as well as surrounding areas observed on the solar disc between 2010 and 2023. The resulting ML-ready SolARED dataset is designed to support enhancements of predictive capabilities, enabling the development of operational forecasts for the emergence of active regions. The SolARED dataset is available at https://sun.njit.edu/sarportal/, through an interactive visualization web application.
Optimizing Large Language Models for Turkish: New Methodologies in Corpus Selection and Training
Dec 03, 2024



In this study, we develop and assess new corpus selection and training methodologies to improve the effectiveness of Turkish language models. Specifically, we adapted Large Language Model generated datasets and translated English datasets into Turkish, integrating these resources into the training process. This approach led to substantial enhancements in model accuracy for both few-shot and zero-shot learning scenarios. Furthermore, the merging of these adapted models was found to markedly improve their performance. Human evaluative metrics, including task-specific performance assessments, further demonstrated that these adapted models possess a greater aptitude for comprehending the Turkish language and addressing logic-based queries. This research underscores the importance of refining corpus selection strategies to optimize the performance of multilingual models, particularly for under-resourced languages like Turkish.
* 2024 Innovations in Intelligent Systems and Applications Conference (ASYU)
Cosmos-LLaVA: Chatting with the Visual Cosmos-LLaVA: Görselle Sohbet Etmek
Dec 03, 2024In this study, a Turkish visual instruction model was developed and various model architectures and dataset combinations were analysed to improve the performance of this model. The Cosmos-LLaVA model, which is built by combining different large language models and image coders, is designed to overcome the deficiencies in the Turkish language. In the experiments, the effects of fine-tuning with various datasets on the model performance are analysed in detail. The results show that model architecture and dataset selection have a significant impact on performance. Bu \c{c}al{\i}\c{s}mada bir T\"urk\c{c}e g\"orsel talimat modeli geli\c{s}tirilerek bu modelin performans{\i}n{\i} art{\i}rmaya y\"onelik \c{c}e\c{s}itli model mimarileri ve veri k\"umesi kombinasyonlar{\i} derinlemesine incelenmi\c{s}tir. Farkl{\i} b\"uy\"uk dil modelleri ve g\"or\"unt\"u kodlay{\i}c{\i}lar{\i}n{\i}n bir araya getirilmesiyle olu\c{s}turulan Cosmos-LLaVA modeli, T\"urk\c{c}e dilindeki eksiklikleri gidermeye y\"onelik olarak tasarlanm{\i}\c{s}t{\i}r. Yap{\i}lan deneylerde, \c{c}e\c{s}itli veri k\"umeleri ile yap{\i}lan ince ayarlar{\i}n model performans{\i}n{\i} nas{\i}l etkiledi\u{g}i detayl{\i} olarak ele al{\i}nm{\i}\c{s}t{\i}r. Sonu\c{c}lar, model mimarisi ve veri k\"umesi se\c{c}iminin performans \"uzerinde \"onemli bir etkiye sahip oldu\u{g}unu g\"ostermektedir.
VLSI Hypergraph Partitioning with Deep Learning
Sep 02, 2024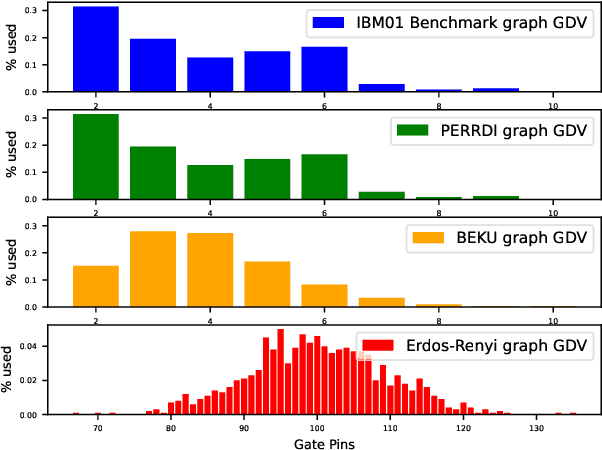
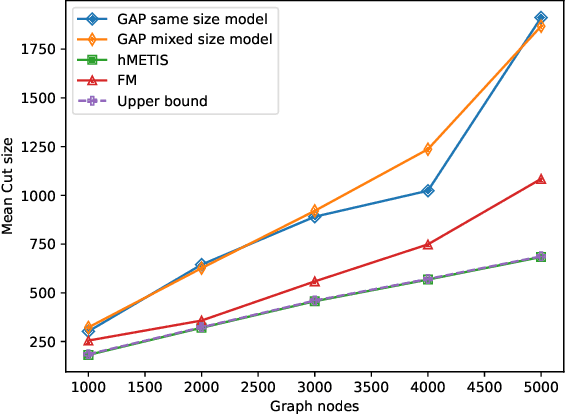
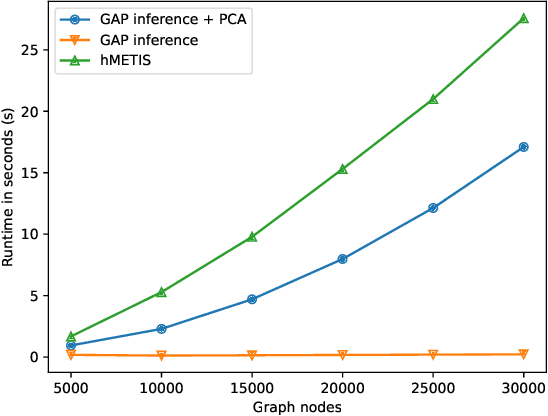
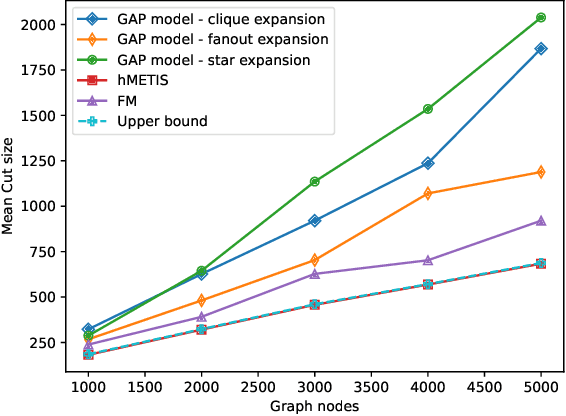
Partitioning is a known problem in computer science and is critical in chip design workflows, as advancements in this area can significantly influence design quality and efficiency. Deep Learning (DL) techniques, particularly those involving Graph Neural Networks (GNNs), have demonstrated strong performance in various node, edge, and graph prediction tasks using both inductive and transductive learning methods. A notable area of recent interest within GNNs are pooling layers and their application to graph partitioning. While these methods have yielded promising results across social, computational, and other random graphs, their effectiveness has not yet been explored in the context of VLSI hypergraph netlists. In this study, we introduce a new set of synthetic partitioning benchmarks that emulate real-world netlist characteristics and possess a known upper bound for solution cut quality. We distinguish these benchmarks with the prior work and evaluate existing state-of-the-art partitioning algorithms alongside GNN-based approaches, highlighting their respective advantages and disadvantages.
GAT-Steiner: Rectilinear Steiner Minimal Tree Prediction Using GNNs
Jul 01, 2024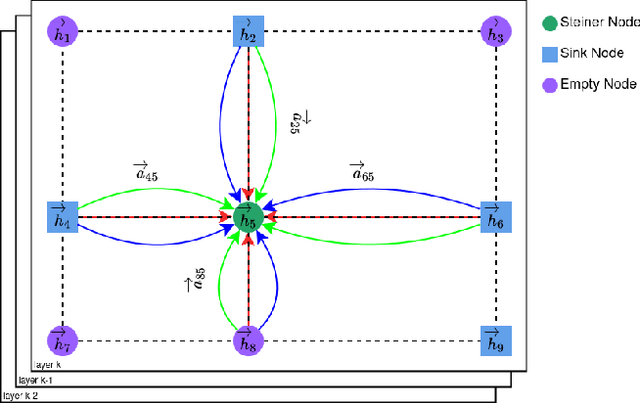
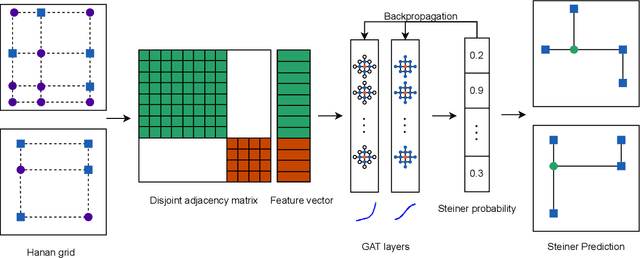
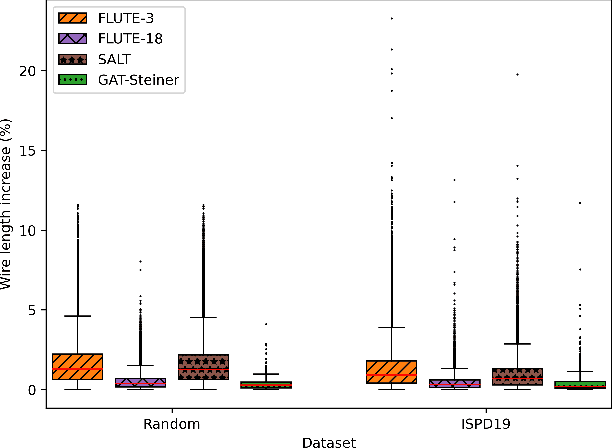

The Rectilinear Steiner Minimum Tree (RSMT) problem is a fundamental problem in VLSI placement and routing and is known to be NP-hard. Traditional RSMT algorithms spend a significant amount of time on finding Steiner points to reduce the total wire length or use heuristics to approximate producing sub-optimal results. We show that Graph Neural Networks (GNNs) can be used to predict optimal Steiner points in RSMTs with high accuracy and can be parallelized on GPUs. In this paper, we propose GAT-Steiner, a graph attention network model that correctly predicts 99.846% of the nets in the ISPD19 benchmark with an average increase in wire length of only 0.480% on suboptimal wire length nets. On randomly generated benchmarks, GAT-Steiner correctly predicts 99.942% with an average increase in wire length of only 0.420% on suboptimal wire length nets.
Introducing cosmosGPT: Monolingual Training for Turkish Language Models
Apr 26, 2024The number of open source language models that can produce Turkish is increasing day by day, as in other languages. In order to create the basic versions of such models, the training of multilingual models is usually continued with Turkish corpora. The alternative is to train the model with only Turkish corpora. In this study, we first introduce the cosmosGPT models that we created with this alternative method. Then, we introduce new finetune datasets for basic language models to fulfill user requests and new evaluation datasets for measuring the capabilities of Turkish language models. Finally, a comprehensive comparison of the adapted Turkish language models on different capabilities is presented. The results show that the language models we built with the monolingual corpus have promising performance despite being about 10 times smaller than the others.
Türkçe Dil Modellerinin Performans Karşılaştırması Performance Comparison of Turkish Language Models
Apr 25, 2024The developments that language models have provided in fulfilling almost all kinds of tasks have attracted the attention of not only researchers but also the society and have enabled them to become products. There are commercially successful language models available. However, users may prefer open-source language models due to cost, data privacy, or regulations. Yet, despite the increasing number of these models, there is no comprehensive comparison of their performance for Turkish. This study aims to fill this gap in the literature. A comparison is made among seven selected language models based on their contextual learning and question-answering abilities. Turkish datasets for contextual learning and question-answering were prepared, and both automatic and human evaluations were conducted. The results show that for question-answering, continuing pretraining before fine-tuning with instructional datasets is more successful in adapting multilingual models to Turkish and that in-context learning performances do not much related to question-answering performances.
Deep Compression for PyTorch Model Deployment on Microcontrollers
Mar 29, 2021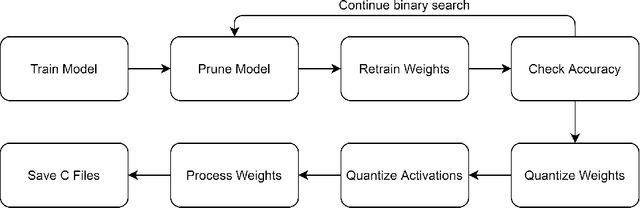

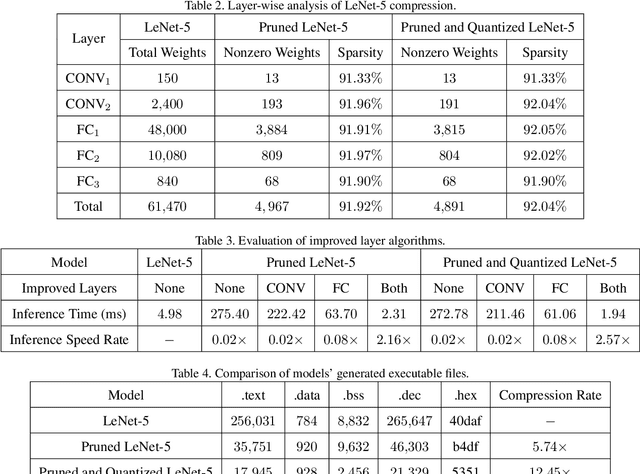
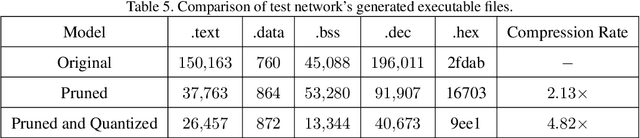
Neural network deployment on low-cost embedded systems, hence on microcontrollers (MCUs), has recently been attracting more attention than ever. Since MCUs have limited memory capacity as well as limited compute-speed, it is critical that we employ model compression, which reduces both memory and compute-speed requirements. In this paper, we add model compression, specifically Deep Compression, and further optimize Unlu's earlier work on arXiv, which efficiently deploys PyTorch models on MCUs. First, we prune the weights in convolutional and fully connected layers. Secondly, the remaining weights and activations are quantized to 8-bit integers from 32-bit floating-point. Finally, forward pass functions are compressed using special data structures for sparse matrices, which store only nonzero weights (without impacting performance and accuracy). In the case of the LeNet-5 model, the memory footprint was reduced by 12.45x, and the inference speed was boosted by 2.57x.