 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Change Captioning in Remote Sensing: SECOND-CC Dataset and MModalCC Framework
Jan 17, 2025



Remote sensing change captioning (RSICC) aims to describe changes between bitemporal images in natural language. Existing methods often fail under challenges like illumination differences, viewpoint changes, blur effects, leading to inaccuracies, especially in no-change regions. Moreover, the images acquired at different spatial resolutions and have registration errors tend to affect the captions. To address these issues, we introduce SECOND-CC, a novel RSICC dataset featuring high-resolution RGB image pairs, semantic segmentation maps, and diverse real-world scenarios. SECOND-CC which contains 6,041 pairs of bitemporal RS images and 30,205 sentences describing the differences between images. Additionally, we propose MModalCC, a multimodal framework that integrates semantic and visual data using advanced attention mechanisms, including Cross-Modal Cross Attention (CMCA) and Multimodal Gated Cross Attention (MGCA). Detailed ablation studies and attention visualizations further demonstrate its effectiveness and ability to address RSICC challenges. Comprehensive experiments show that MModalCC outperforms state-of-the-art RSICC methods, including RSICCformer, Chg2Cap, and PSNet with +4.6% improvement on BLEU4 score and +9.6% improvement on CIDEr score. We will make our dataset and codebase publicly available to facilitate future research at https://github.com/ChangeCapsInRS/SecondCC
Cosmos-LLaVA: Chatting with the Visual Cosmos-LLaVA: Görselle Sohbet Etmek
Dec 03, 2024In this study, a Turkish visual instruction model was developed and various model architectures and dataset combinations were analysed to improve the performance of this model. The Cosmos-LLaVA model, which is built by combining different large language models and image coders, is designed to overcome the deficiencies in the Turkish language. In the experiments, the effects of fine-tuning with various datasets on the model performance are analysed in detail. The results show that model architecture and dataset selection have a significant impact on performance. Bu \c{c}al{\i}\c{s}mada bir T\"urk\c{c}e g\"orsel talimat modeli geli\c{s}tirilerek bu modelin performans{\i}n{\i} art{\i}rmaya y\"onelik \c{c}e\c{s}itli model mimarileri ve veri k\"umesi kombinasyonlar{\i} derinlemesine incelenmi\c{s}tir. Farkl{\i} b\"uy\"uk dil modelleri ve g\"or\"unt\"u kodlay{\i}c{\i}lar{\i}n{\i}n bir araya getirilmesiyle olu\c{s}turulan Cosmos-LLaVA modeli, T\"urk\c{c}e dilindeki eksiklikleri gidermeye y\"onelik olarak tasarlanm{\i}\c{s}t{\i}r. Yap{\i}lan deneylerde, \c{c}e\c{s}itli veri k\"umeleri ile yap{\i}lan ince ayarlar{\i}n model performans{\i}n{\i} nas{\i}l etkiledi\u{g}i detayl{\i} olarak ele al{\i}nm{\i}\c{s}t{\i}r. Sonu\c{c}lar, model mimarisi ve veri k\"umesi se\c{c}iminin performans \"uzerinde \"onemli bir etkiye sahip oldu\u{g}unu g\"ostermektedir.
Optimizing Large Language Models for Turkish: New Methodologies in Corpus Selection and Training
Dec 03, 2024



In this study, we develop and assess new corpus selection and training methodologies to improve the effectiveness of Turkish language models. Specifically, we adapted Large Language Model generated datasets and translated English datasets into Turkish, integrating these resources into the training process. This approach led to substantial enhancements in model accuracy for both few-shot and zero-shot learning scenarios. Furthermore, the merging of these adapted models was found to markedly improve their performance. Human evaluative metrics, including task-specific performance assessments, further demonstrated that these adapted models possess a greater aptitude for comprehending the Turkish language and addressing logic-based queries. This research underscores the importance of refining corpus selection strategies to optimize the performance of multilingual models, particularly for under-resourced languages like Turkish.
* 2024 Innovations in Intelligent Systems and Applications Conference (ASYU)
Introducing cosmosGPT: Monolingual Training for Turkish Language Models
Apr 26, 2024The number of open source language models that can produce Turkish is increasing day by day, as in other languages. In order to create the basic versions of such models, the training of multilingual models is usually continued with Turkish corpora. The alternative is to train the model with only Turkish corpora. In this study, we first introduce the cosmosGPT models that we created with this alternative method. Then, we introduce new finetune datasets for basic language models to fulfill user requests and new evaluation datasets for measuring the capabilities of Turkish language models. Finally, a comprehensive comparison of the adapted Turkish language models on different capabilities is presented. The results show that the language models we built with the monolingual corpus have promising performance despite being about 10 times smaller than the others.
Türkçe Dil Modellerinin Performans Karşılaştırması Performance Comparison of Turkish Language Models
Apr 25, 2024The developments that language models have provided in fulfilling almost all kinds of tasks have attracted the attention of not only researchers but also the society and have enabled them to become products. There are commercially successful language models available. However, users may prefer open-source language models due to cost, data privacy, or regulations. Yet, despite the increasing number of these models, there is no comprehensive comparison of their performance for Turkish. This study aims to fill this gap in the literature. A comparison is made among seven selected language models based on their contextual learning and question-answering abilities. Turkish datasets for contextual learning and question-answering were prepared, and both automatic and human evaluations were conducted. The results show that for question-answering, continuing pretraining before fine-tuning with instructional datasets is more successful in adapting multilingual models to Turkish and that in-context learning performances do not much related to question-answering performances.
Cyclical Curriculum Learning
Feb 11, 2022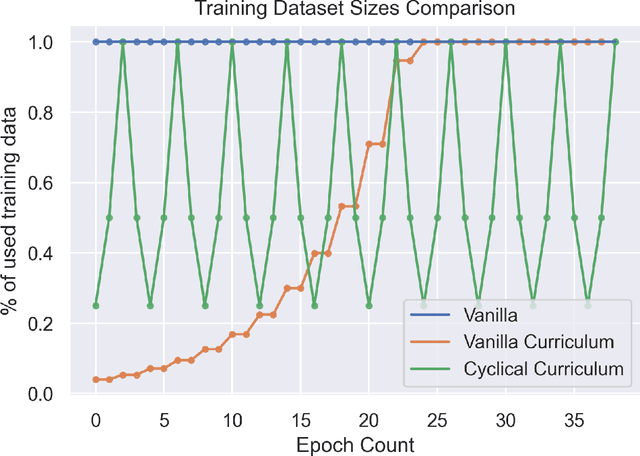
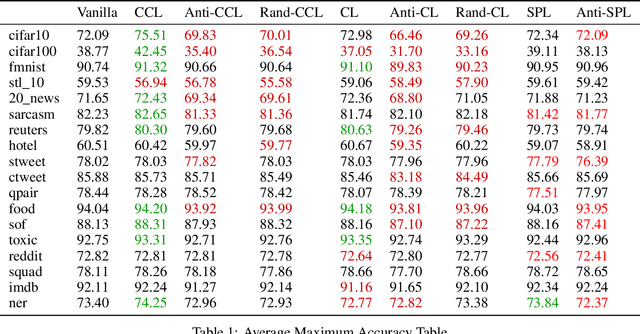
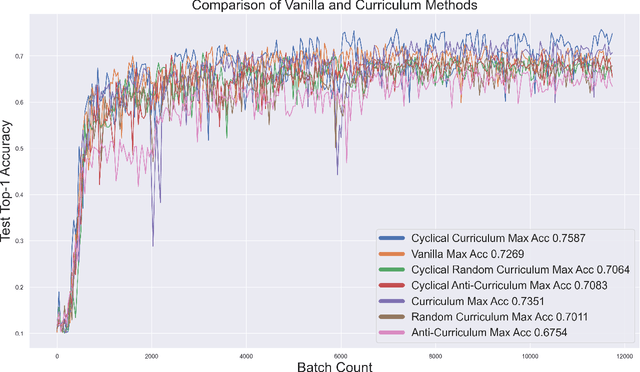
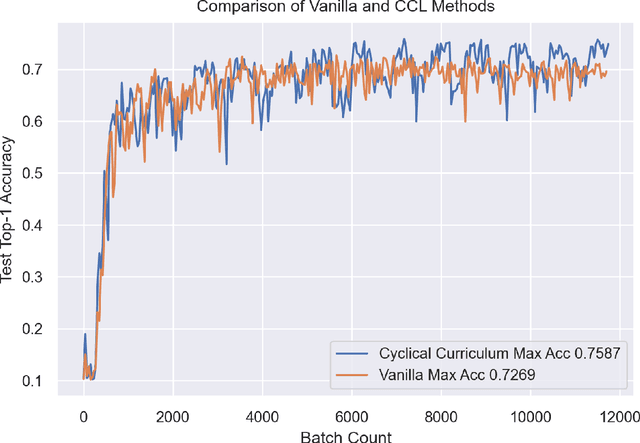
Artificial neural networks (ANN) are inspired by human learning. However, unlike human education, classical ANN does not use a curriculum. Curriculum Learning (CL) refers to the process of ANN training in which examples are used in a meaningful order. When using CL, training begins with a subset of the dataset and new samples are added throughout the training, or training begins with the entire dataset and the number of samples used is reduced. With these changes in training dataset size, better results can be obtained with curriculum, anti-curriculum, or random-curriculum methods than the vanilla method. However, a generally efficient CL method for various architectures and data sets is not found. In this paper, we propose cyclical curriculum learning (CCL), in which the data size used during training changes cyclically rather than simply increasing or decreasing. Instead of using only the vanilla method or only the curriculum method, using both methods cyclically like in CCL provides more successful results. We tested the method on 18 different data sets and 15 architectures in image and text classification tasks and obtained more successful results than no-CL and existing CL methods. We also have shown theoretically that it is less erroneous to apply CL and vanilla cyclically instead of using only CL or only vanilla method. The code of Cyclical Curriculum is available at https://github.com/CyclicalCurriculum/Cyclical-Curriculum.
Development and Comparison of Scoring Functions in Curriculum Learning
Feb 10, 2022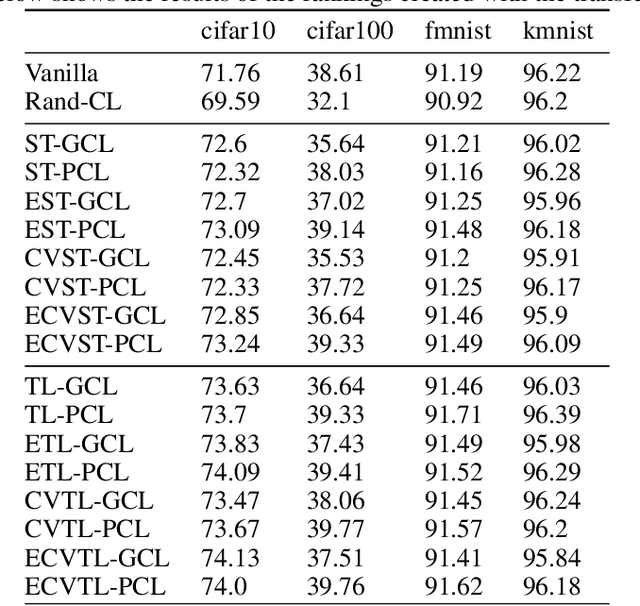
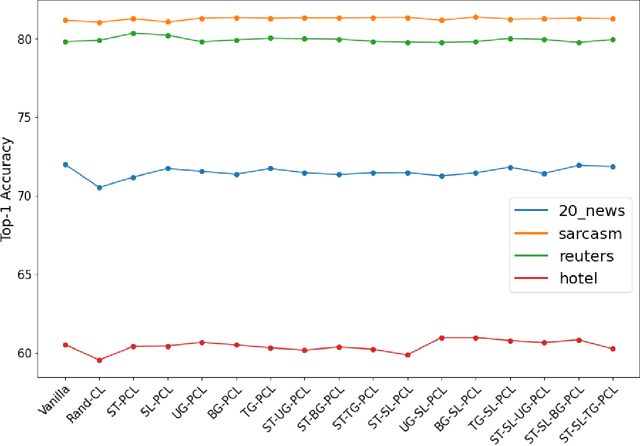
Curriculum Learning is the presentation of samples to the machine learning model in a meaningful order instead of a random order. The main challenge of Curriculum Learning is determining how to rank these samples. The ranking of the samples is expressed by the scoring function. In this study, scoring functions were compared using data set features, using the model to be trained, and using another model and their ensemble versions. Experiments were performed for 4 images and 4 text datasets. No significant differences were found between scoring functions for text datasets, but significant improvements were obtained in scoring functions created using transfer learning compared to classical model training and other scoring functions for image datasets. It shows that different new scoring functions are waiting to be found for text classification tasks.