 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Compression for PyTorch Model Deployment on Microcontrollers
Mar 29, 2021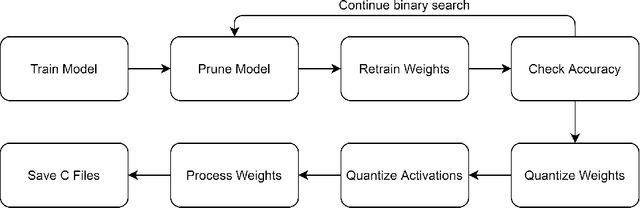

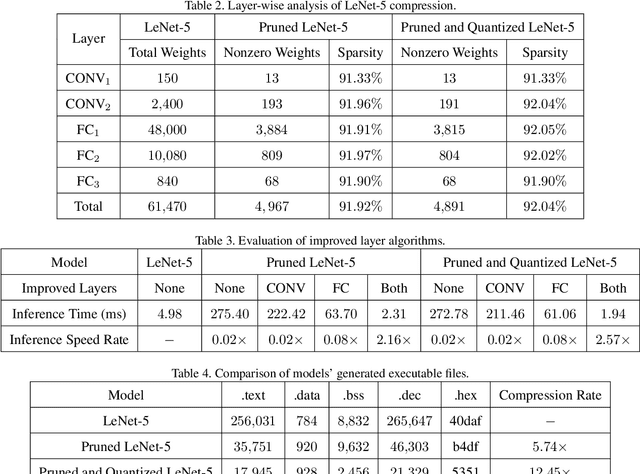
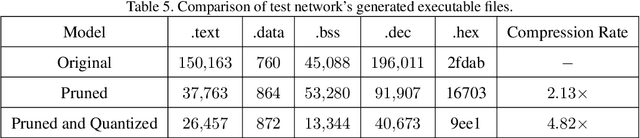
Neural network deployment on low-cost embedded systems, hence on microcontrollers (MCUs), has recently been attracting more attention than ever. Since MCUs have limited memory capacity as well as limited compute-speed, it is critical that we employ model compression, which reduces both memory and compute-speed requirements. In this paper, we add model compression, specifically Deep Compression, and further optimize Unlu's earlier work on arXiv, which efficiently deploys PyTorch models on MCUs. First, we prune the weights in convolutional and fully connected layers. Secondly, the remaining weights and activations are quantized to 8-bit integers from 32-bit floating-point. Finally, forward pass functions are compressed using special data structures for sparse matrices, which store only nonzero weights (without impacting performance and accuracy). In the case of the LeNet-5 model, the memory footprint was reduced by 12.45x, and the inference speed was boosted by 2.57x.
Efficient Neural Network Deployment for Microcontroller
Jul 02, 2020

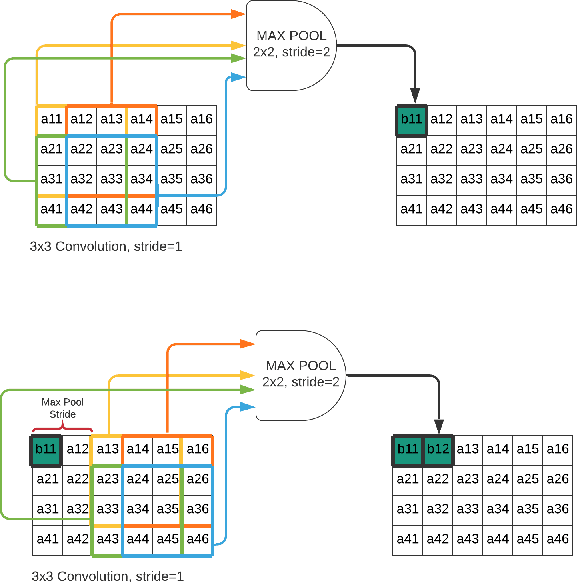
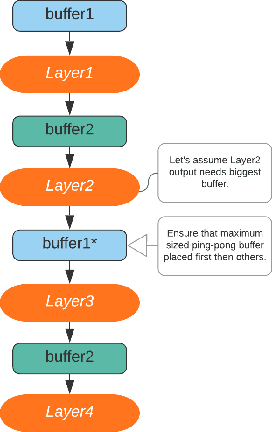
Edge computing for neural networks is getting important especially for low power applications and offline devices. TensorFlow Lite and PyTorch Mobile were released for this purpose. But they mainly support mobile devices instead of microcontroller level yet. Microcontroller support is an emerging area now. There are many approaches to reduce network size and compute load like pruning, binarization and layer manipulation i.e. operator reordering. This paper is going to explore and generalize convolution neural network deployment for microcontrollers with two novel optimization proposals offering memory saving and compute efficiency in 2D convolutions as well as fully connected layers. The first one is in-place max-pooling, if the stride is greater than or equal to pooling kernel size. The second optimization is to use ping-pong buffers between layers to reduce memory consumption significantly. The memory savings and performance will be compared with CMSIS-NN framework developed for ARM Cortex-M CPUs. The final purpose is to develop a tool consuming PyTorch model with trained network weights, and it turns into an optimized inference engine(forward pass) in C/C++ for low memory(kilobyte level) and limited computing capable microcontrollers.