 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Neural Network Deployment for Microcontroller
Paper and Code


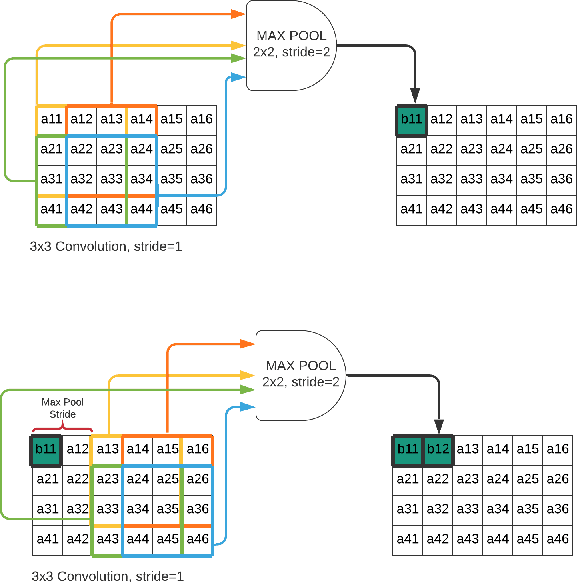
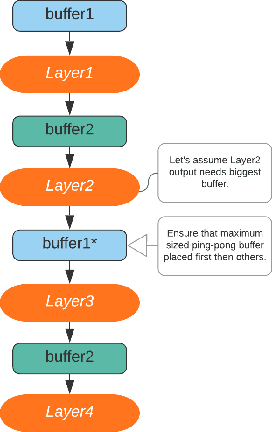
Edge computing for neural networks is getting important especially for low power applications and offline devices. TensorFlow Lite and PyTorch Mobile were released for this purpose. But they mainly support mobile devices instead of microcontroller level yet. Microcontroller support is an emerging area now. There are many approaches to reduce network size and compute load like pruning, binarization and layer manipulation i.e. operator reordering. This paper is going to explore and generalize convolution neural network deployment for microcontrollers with two novel optimization proposals offering memory saving and compute efficiency in 2D convolutions as well as fully connected layers. The first one is in-place max-pooling, if the stride is greater than or equal to pooling kernel size. The second optimization is to use ping-pong buffers between layers to reduce memory consumption significantly. The memory savings and performance will be compared with CMSIS-NN framework developed for ARM Cortex-M CPUs. The final purpose is to develop a tool consuming PyTorch model with trained network weights, and it turns into an optimized inference engine(forward pass) in C/C++ for low memory(kilobyte level) and limited computing capable microcontrollers.