 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Multi-Armed Bandits Under Byzantine Attacks
Paper and Code
May 09, 2022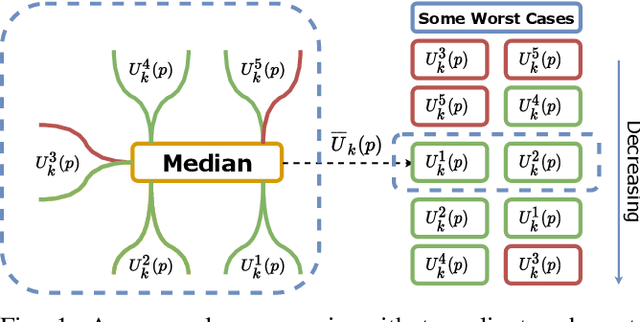
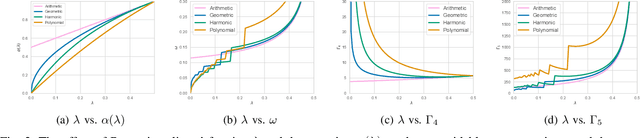
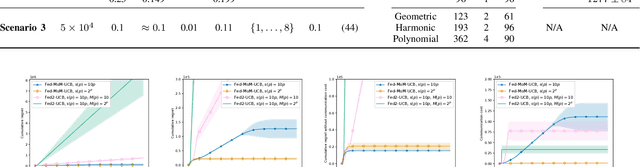
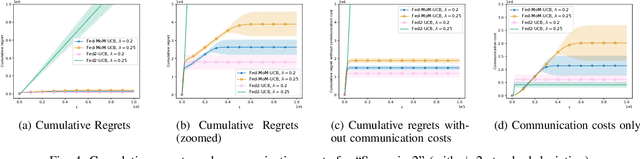
Multi-armed bandits (MAB) is a simple reinforcement learning model where the learner controls the trade-off between exploration versus exploitation to maximize its cumulative reward. Federated multi-armed bandits (FMAB) is a recently emerging framework where a cohort of learners with heterogeneous local models play a MAB game and communicate their aggregated feedback to a parameter server to learn the global feedback model. Federated learning models are vulnerable to adversarial attacks such as model-update attacks or data poisoning. In this work, we study an FMAB problem in the presence of Byzantine clients who can send false model updates that pose a threat to the learning process. We borrow tools from robust statistics and propose a median-of-means-based estimator: Fed-MoM-UCB, to cope with the Byzantine clients. We show that if the Byzantine clients constitute at most half the cohort, it is possible to incur a cumulative regret on the order of ${\cal O} (\log T)$ with respect to an unavoidable error margin, including the communication cost between the clients and the parameter server. We analyze the interplay between the algorithm parameters, unavoidable error margin, regret, communication cost, and the arms' suboptimality gaps. We demonstrate Fed-MoM-UCB's effectiveness against the baselines in the presence of Byzantine attacks via experiments.