 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Reduced Hindsight Experience Replay with Virtual Goal Prioritization
Paper and Code

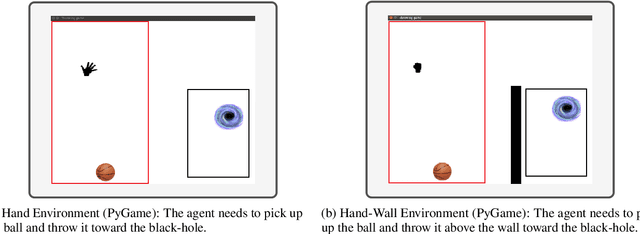

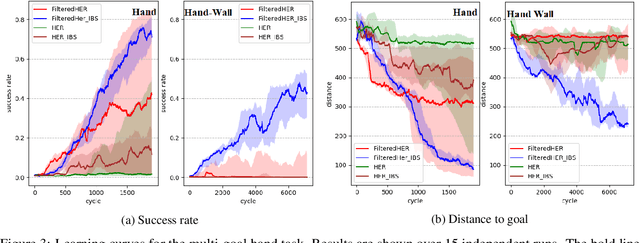
Hindsight Experience Replay (HER) is a multi-goal reinforcement learning algorithm for sparse reward functions. The algorithm treats every failure as a success for an alternative (virtual) goal that has been achieved in the episode. Virtual goals are randomly selected, irrespective of which are most instructive for the agent. In this paper, we present two improvements over the existing HER algorithm. First, we prioritize virtual goals from which the agent will learn more valuable information. We call this property the instructiveness of the virtual goal and define it by a heuristic measure, which expresses how well the agent will be able to generalize from that virtual goal to actual goals. Secondly, we reduce existing bias in HER by the removal of misleading samples. To test our algorithms, we built two challenging environments with sparse reward functions. Our empirical results in both environments show vast improvement in the final success rate and sample efficiency when compared to the original HER algorithm.