 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Editing for Audio-Visual Dubbing
May 29, 2025Visual dubbing, the synchronization of facial movements with new speech, is crucial for making content accessible across different languages, enabling broader global reach. However, current methods face significant limitations. Existing approaches often generate talking faces, hindering seamless integration into original scenes, or employ inpainting techniques that discard vital visual information like partial occlusions and lighting variations. This work introduces EdiDub, a novel framework that reformulates visual dubbing as a content-aware editing task. EdiDub preserves the original video context by utilizing a specialized conditioning scheme to ensure faithful and accurate modifications rather than mere copying. On multiple benchmarks, including a challenging occluded-lip dataset, EdiDub significantly improves identity preservation and synchronization. Human evaluations further confirm its superiority, achieving higher synchronization and visual naturalness scores compared to the leading methods. These results demonstrate that our content-aware editing approach outperforms traditional generation or inpainting, particularly in maintaining complex visual elements while ensuring accurate lip synchronization.
Curriculum Learning with Hindsight Experience Replay for Sequential Object Manipulation Tasks
Aug 21, 2020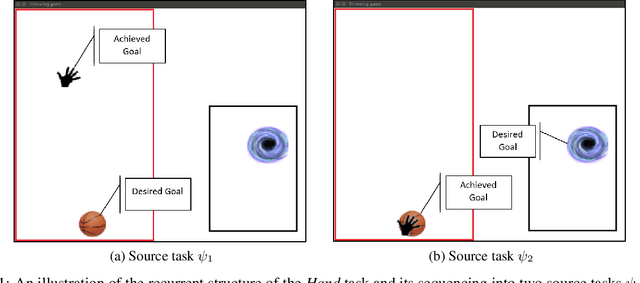
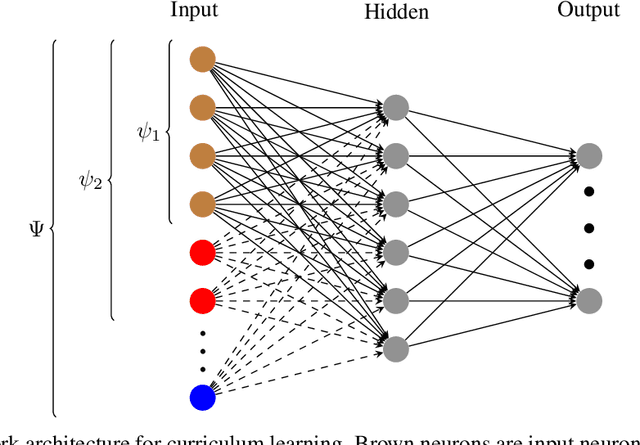
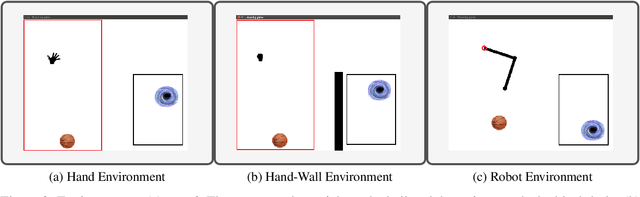
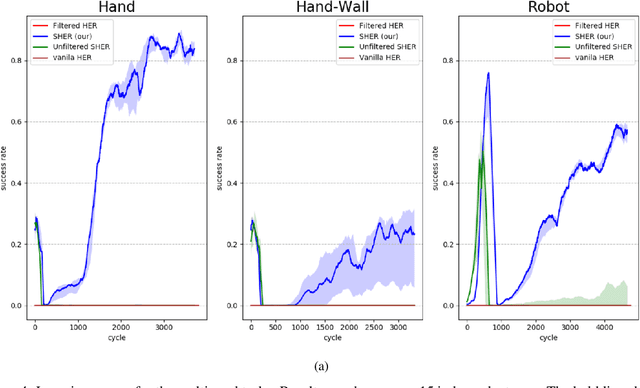
Learning complex tasks from scratch is challenging and often impossible for humans as well as for artificial agents. A curriculum can be used instead, which decomposes a complex task (target task) into a sequence of source tasks (the curriculum). Each source task is a simplified version of the next source task with increasing complexity. Learning then occurs gradually by training on each source task while using knowledge from the curriculum's prior source tasks. In this study, we present a new algorithm that combines curriculum learning with Hindsight Experience Replay (HER), to learn sequential object manipulation tasks for multiple goals and sparse feedback. The algorithm exploits the recurrent structure inherent in many object manipulation tasks and implements the entire learning process in the original simulation without adjusting it to each source task. We have tested our algorithm on three challenging throwing tasks and show vast improvements compared to vanilla-HER.
Metric-Based Imitation Learning Between Two Dissimilar Anthropomorphic Robotic Arms
Feb 25, 2020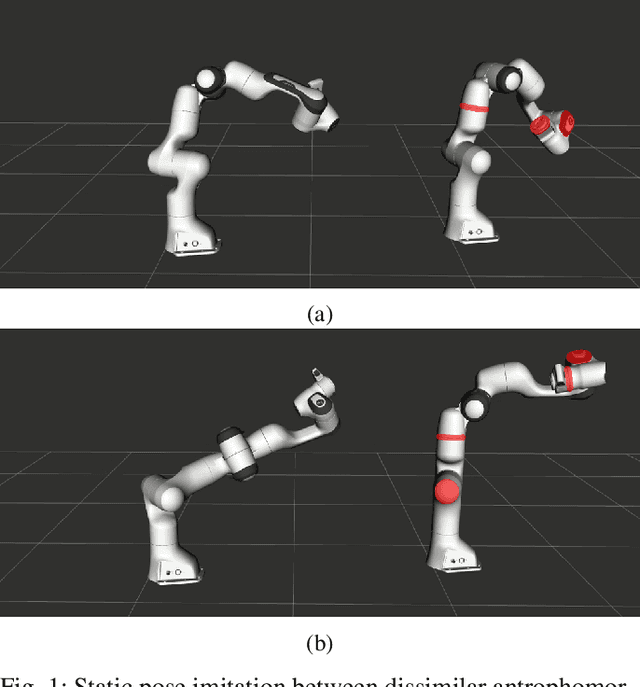
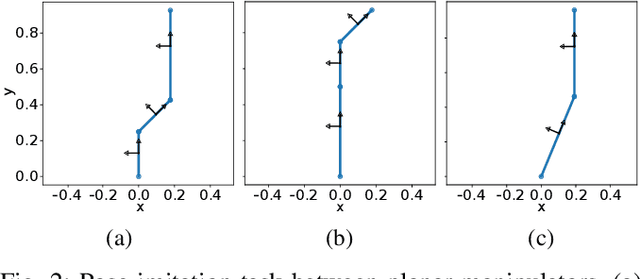
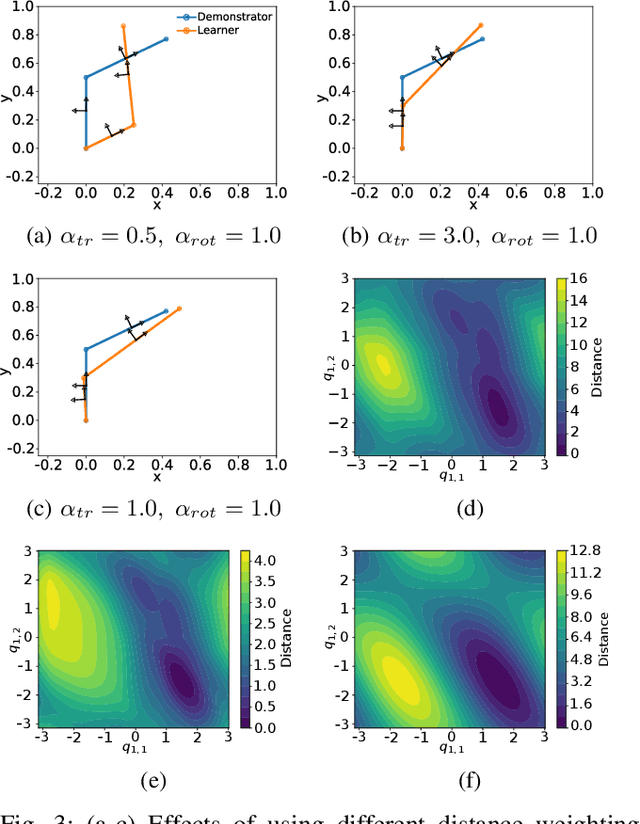
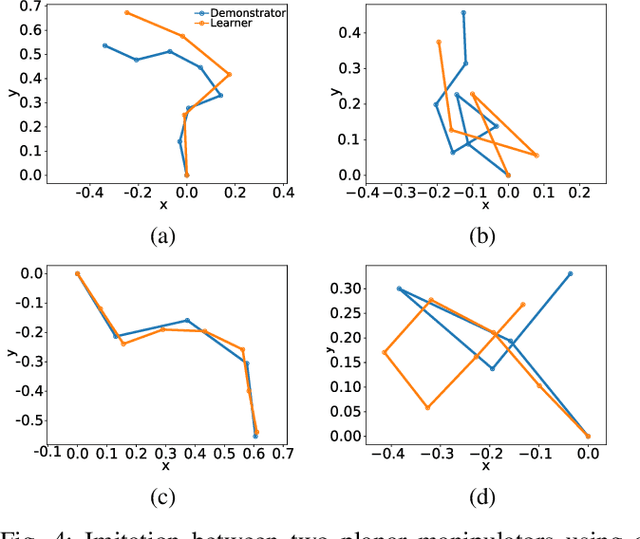
The development of autonomous robotic systems that can learn from human demonstrations to imitate a desired behavior - rather than being manually programmed - has huge technological potential. One major challenge in imitation learning is the correspondence problem: how to establish corresponding states and actions between expert and learner, when the embodiments of the agents are different (morphology, dynamics, degrees of freedom, etc.). Many existing approaches in imitation learning circumvent the correspondence problem, for example, kinesthetic teaching or teleoperation, which are performed on the robot. In this work we explicitly address the correspondence problem by introducing a distance measure between dissimilar embodiments. This measure is then used as a loss function for static pose imitation and as a feedback signal within a model-free deep reinforcement learning framework for dynamic movement imitation between two anthropomorphic robotic arms in simulation. We find that the measure is well suited for describing the similarity between embodiments and for learning imitation policies by distance minimization.
Deep Reinforcement Learning for Complex Manipulation Tasks with Sparse Feedback
Jan 12, 2020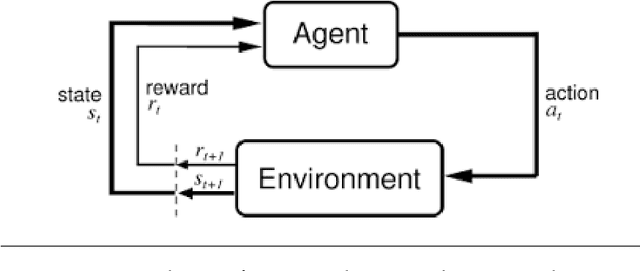
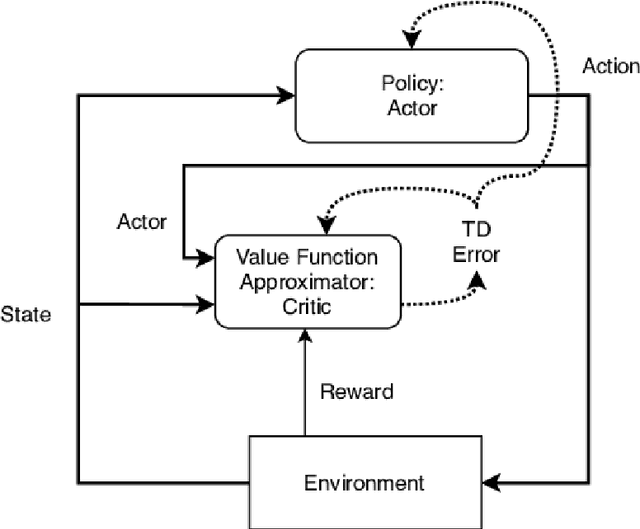

Learning optimal policies from sparse feedback is a known challenge in reinforcement learning. Hindsight Experience Replay (HER) is a multi-goal reinforcement learning algorithm that comes to solve such tasks. The algorithm treats every failure as a success for an alternative (virtual) goal that has been achieved in the episode and then generalizes from that virtual goal to real goals. HER has known flaws and is limited to relatively simple tasks. In this thesis, we present three algorithms based on the existing HER algorithm that improves its performances. First, we prioritize virtual goals from which the agent will learn more valuable information. We call this property the \textit{instructiveness} of the virtual goal and define it by a heuristic measure, which expresses how well the agent will be able to generalize from that virtual goal to actual goals. Secondly, we designed a filtering process that detects and removes misleading samples that may induce bias throughout the learning process. Lastly, we enable the learning of complex, sequential, tasks using a form of curriculum learning combined with HER. We call this algorithm \textit{Curriculum HER}. To test our algorithms, we built three challenging manipulation environments with sparse reward functions. Each environment has three levels of complexity. Our empirical results show vast improvement in the final success rate and sample efficiency when compared to the original HER algorithm.
Bias-Reduced Hindsight Experience Replay with Virtual Goal Prioritization
May 14, 2019
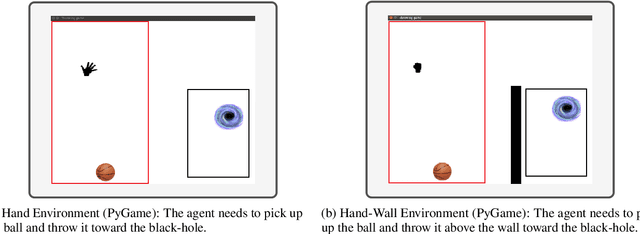

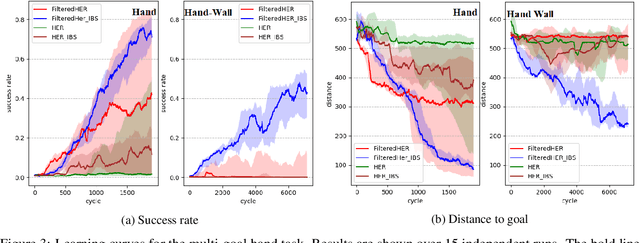
Hindsight Experience Replay (HER) is a multi-goal reinforcement learning algorithm for sparse reward functions. The algorithm treats every failure as a success for an alternative (virtual) goal that has been achieved in the episode. Virtual goals are randomly selected, irrespective of which are most instructive for the agent. In this paper, we present two improvements over the existing HER algorithm. First, we prioritize virtual goals from which the agent will learn more valuable information. We call this property the instructiveness of the virtual goal and define it by a heuristic measure, which expresses how well the agent will be able to generalize from that virtual goal to actual goals. Secondly, we reduce existing bias in HER by the removal of misleading samples. To test our algorithms, we built two challenging environments with sparse reward functions. Our empirical results in both environments show vast improvement in the final success rate and sample efficiency when compared to the original HER algorithm.