 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Complex Manipulation Tasks with Sparse Feedback
Paper and Code
Jan 12, 2020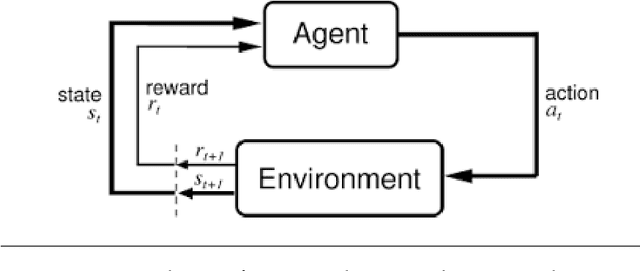
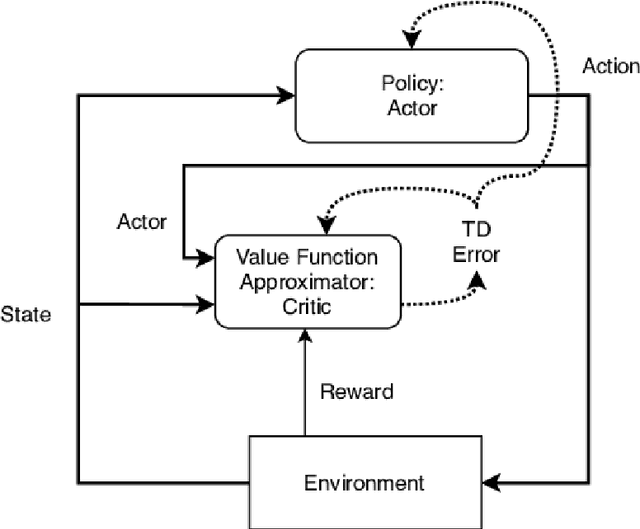

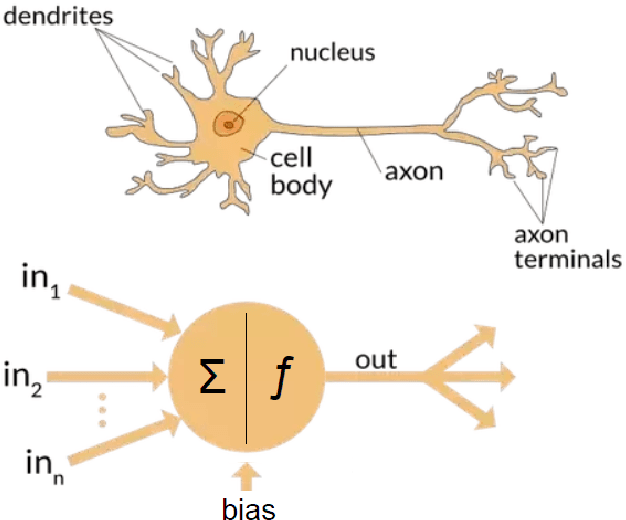
Learning optimal policies from sparse feedback is a known challenge in reinforcement learning. Hindsight Experience Replay (HER) is a multi-goal reinforcement learning algorithm that comes to solve such tasks. The algorithm treats every failure as a success for an alternative (virtual) goal that has been achieved in the episode and then generalizes from that virtual goal to real goals. HER has known flaws and is limited to relatively simple tasks. In this thesis, we present three algorithms based on the existing HER algorithm that improves its performances. First, we prioritize virtual goals from which the agent will learn more valuable information. We call this property the \textit{instructiveness} of the virtual goal and define it by a heuristic measure, which expresses how well the agent will be able to generalize from that virtual goal to actual goals. Secondly, we designed a filtering process that detects and removes misleading samples that may induce bias throughout the learning process. Lastly, we enable the learning of complex, sequential, tasks using a form of curriculum learning combined with HER. We call this algorithm \textit{Curriculum HER}. To test our algorithms, we built three challenging manipulation environments with sparse reward functions. Each environment has three levels of complexity. Our empirical results show vast improvement in the final success rate and sample efficiency when compared to the original HER algorithm.