 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Tables: Deep Learning without Convolutions
Apr 23, 2023



We propose a novel formulation of deep networks that do not use dot-product neurons and rely on a hierarchy of voting tables instead, denoted as Convolutional Tables (CT), to enable accelerated CPU-based inference. Convolutional layers are the most time-consuming bottleneck in contemporary deep learning techniques, severely limiting their use in Internet of Things and CPU-based devices. The proposed CT performs a fern operation at each image location: it encodes the location environment into a binary index and uses the index to retrieve the desired local output from a table. The results of multiple tables are combined to derive the final output. The computational complexity of a CT transformation is independent of the patch (filter) size and grows gracefully with the number of channels, outperforming comparable convolutional layers. It is shown to have a better capacity:compute ratio than dot-product neurons, and that deep CT networks exhibit a universal approximation property similar to neural networks. As the transformation involves computing discrete indices, we derive a soft relaxation and gradient-based approach for training the CT hierarchy. Deep CT networks have been experimentally shown to have accuracy comparable to that of CNNs of similar architectures. In the low compute regime, they enable an error:speed trade-off superior to alternative efficient CNN architectures.
Learning Pose Estimation for High-Precision Robotic Assembly Using Simulated Depth Images
Mar 23, 2019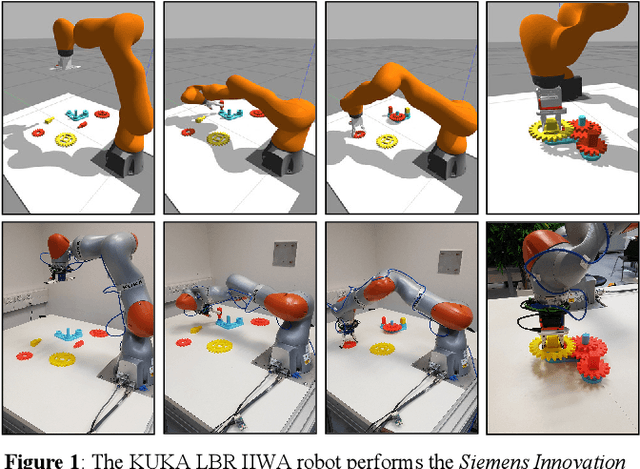
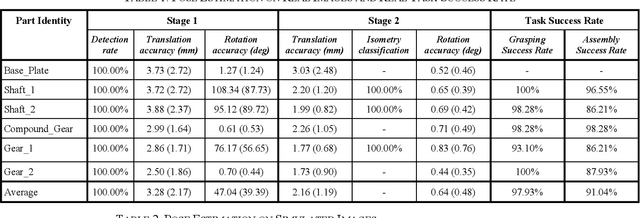

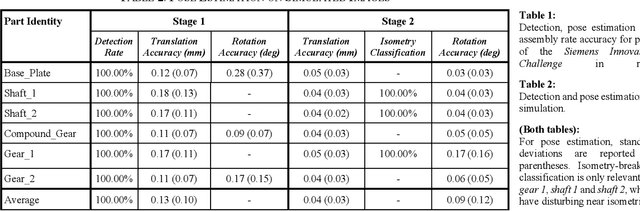
Most of industrial robotic assembly tasks today require fixed initial conditions for successful assembly. These constraints induce high production costs and low adaptability to new tasks. In this work we aim towards flexible and adaptable robotic assembly by using 3D CAD models for all parts to be assembled. We focus on a generic assembly task - the Siemens Innovation Challenge - in which a robot needs to assemble a gear-like mechanism with high precision into an operating system. To obtain the millimeter-accuracy required for this task and industrial settings alike, we use a depth camera mounted near the robot end-effector. We present a high-accuracy two-stage pose estimation procedure based on deep convolutional neural networks, which includes detection, pose estimation, refinement, and handling of near- and full symmetries of parts. The networks are trained on simulated depth images with means to ensure successful transfer to the real robot. We obtain an average pose estimation error of 2.16 millimeters and 0.64 degree leading to 91% success rate for robotic assembly of randomly distributed parts. To the best of our knowledge, this is the first time that the Siemens Innovation Challenge is fully addressed, with all the parts assembled with high success rates.
Convolutional Tables Ensemble: classification in microseconds
Feb 14, 2016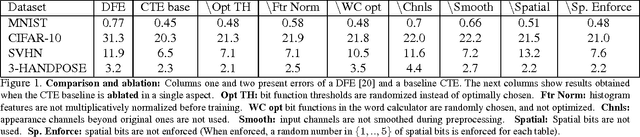

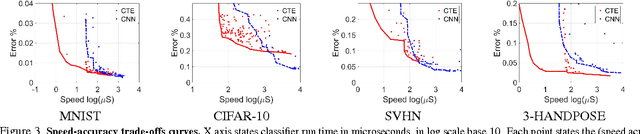
We study classifiers operating under severe classification time constraints, corresponding to 1-1000 CPU microseconds, using Convolutional Tables Ensemble (CTE), an inherently fast architecture for object category recognition. The architecture is based on convolutionally-applied sparse feature extraction, using trees or ferns, and a linear voting layer. Several structure and optimization variants are considered, including novel decision functions, tree learning algorithm, and distillation from CNN to CTE architecture. Accuracy improvements of 24-45% over related art of similar speed are demonstrated on standard object recognition benchmarks. Using Pareto speed-accuracy curves, we show that CTE can provide better accuracy than Convolutional Neural Networks (CNN) for a certain range of classification time constraints, or alternatively provide similar error rates with 5-200X speedup.
Efficient Human Computation
Mar 05, 2009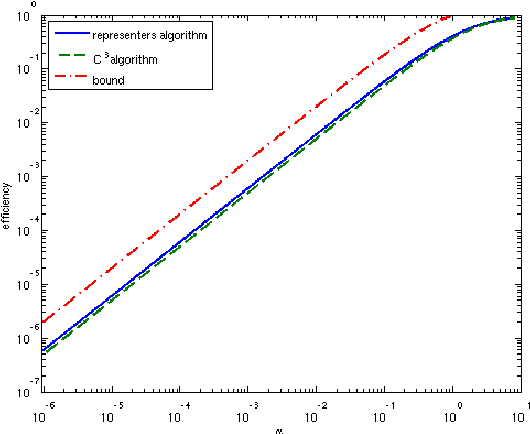
Collecting large labeled data sets is a laborious and expensive task, whose scaling up requires division of the labeling workload between many teachers. When the number of classes is large, miscorrespondences between the labels given by the different teachers are likely to occur, which, in the extreme case, may reach total inconsistency. In this paper we describe how globally consistent labels can be obtained, despite the absence of teacher coordination, and discuss the possible efficiency of this process in terms of human labor. We define a notion of label efficiency, measuring the ratio between the number of globally consistent labels obtained and the number of labels provided by distributed teachers. We show that the efficiency depends critically on the ratio alpha between the number of data instances seen by a single teacher, and the number of classes. We suggest several algorithms for the distributed labeling problem, and analyze their efficiency as a function of alpha. In addition, we provide an upper bound on label efficiency for the case of completely uncoordinated teachers, and show that efficiency approaches 0 as the ratio between the number of labels each teacher provides and the number of classes drops (i.e. alpha goes to 0).