 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Human Computation
Paper and Code
Mar 05, 2009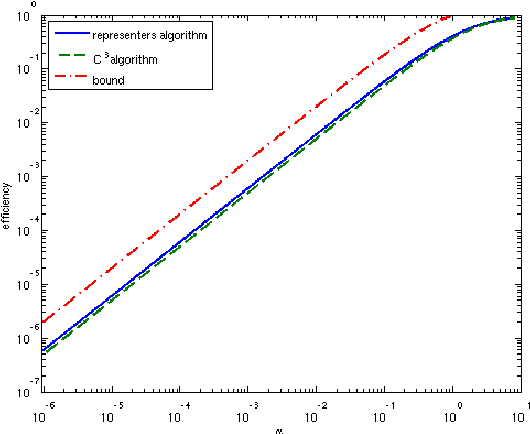
Collecting large labeled data sets is a laborious and expensive task, whose scaling up requires division of the labeling workload between many teachers. When the number of classes is large, miscorrespondences between the labels given by the different teachers are likely to occur, which, in the extreme case, may reach total inconsistency. In this paper we describe how globally consistent labels can be obtained, despite the absence of teacher coordination, and discuss the possible efficiency of this process in terms of human labor. We define a notion of label efficiency, measuring the ratio between the number of globally consistent labels obtained and the number of labels provided by distributed teachers. We show that the efficiency depends critically on the ratio alpha between the number of data instances seen by a single teacher, and the number of classes. We suggest several algorithms for the distributed labeling problem, and analyze their efficiency as a function of alpha. In addition, we provide an upper bound on label efficiency for the case of completely uncoordinated teachers, and show that efficiency approaches 0 as the ratio between the number of labels each teacher provides and the number of classes drops (i.e. alpha goes to 0).