 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning to Construct and Control Agents using Deep Reinforcement Learning
Paper and Code

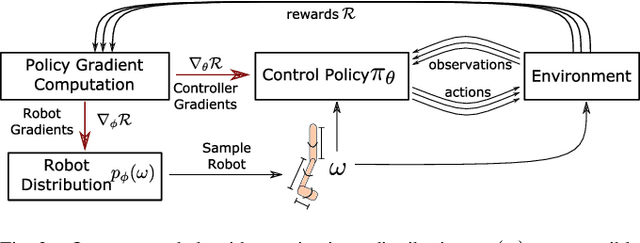
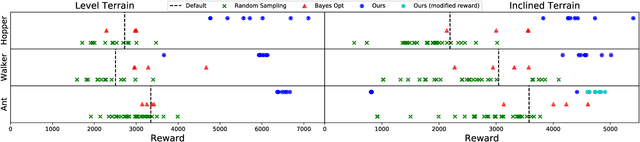
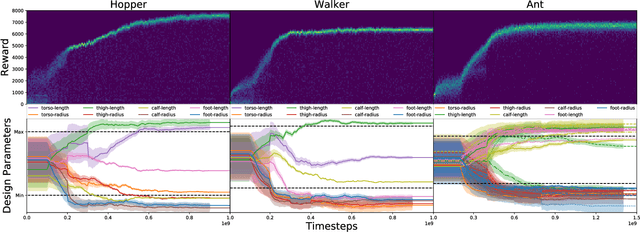
The physical design of a robot and the policy that controls its motion are inherently coupled, and should be determined according to the task and environment. In an increasing number of applications, data-driven and learning-based approaches, such as deep reinforcement learning, have proven effective at designing control policies. For most tasks, the only way to evaluate a physical design with respect to such control policies is empirical--i.e., by picking a design and training a control policy for it. Since training these policies is time-consuming, it is computationally infeasible to train separate policies for all possible designs as a means to identify the best one. In this work, we address this limitation by introducing a method that performs simultaneous joint optimization of the physical design and control network. Our approach maintains a distribution over designs and uses reinforcement learning to optimize a control policy to maximize expected reward over the design distribution. We give the controller access to design parameters to allow it to tailor its policy to each design in the distribution. Throughout training, we shift the distribution towards higher-performing designs, eventually converging to a design and control policy that are jointly optimal. We evaluate our approach in the context of legged locomotion, and demonstrate that it discovers novel designs and walking gaits, outperforming baselines in both performance and efficiency.