 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Policy Learning for Shared Autonomy
Paper and Code
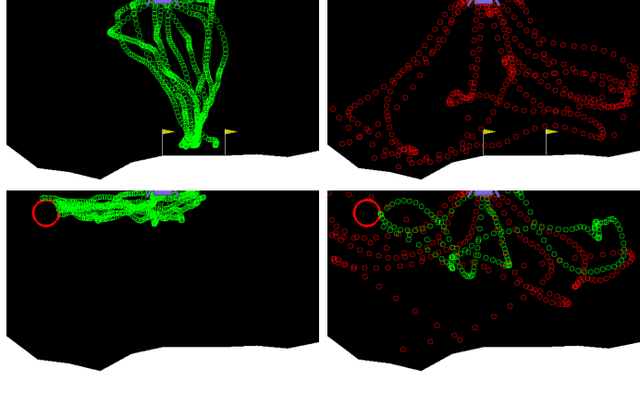
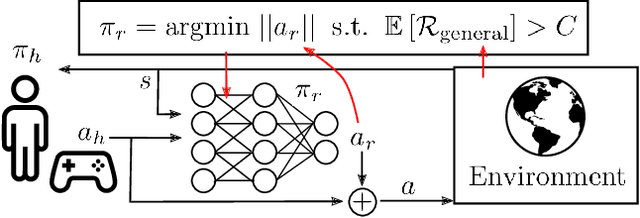

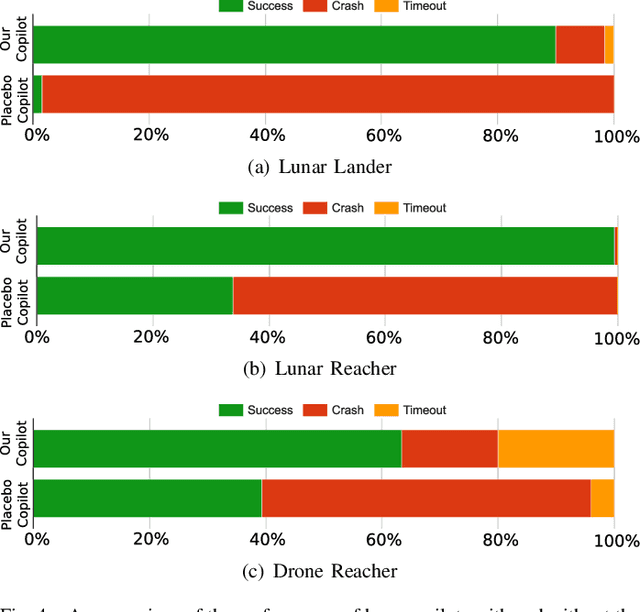
Shared autonomy provides an effective framework for human-robot collaboration that takes advantage of the complementary strengths of humans and robots to achieve common goals. Many existing approaches to shared autonomy make restrictive assumptions that the goal space, environment dynamics, or human policy are known a priori, or are limited to discrete action spaces, preventing those methods from scaling to complicated real world environments. We propose a model-free, residual policy learning algorithm for shared autonomy that alleviates the need for these assumptions. Our agents are trained to minimally adjust the human's actions such that a set of goal-agnostic constraints are satisfied. We test our method in two continuous control environments: LunarLander, a 2D flight control domain, and a 6-DOF quadrotor reaching task. In experiments with human and surrogate pilots, our method significantly improves task performance even though the agent has no explicit or implicit knowledge of the human's goal. These results highlight the ability of model-free deep reinforcement learning to realize assistive agents suited to complicated continuous control settings with minimal knowledge of user intent.