 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionRAG: Attention-Guided Context Pruning in Retrieval-Augmented Generation
Paper and Code
Mar 13, 2025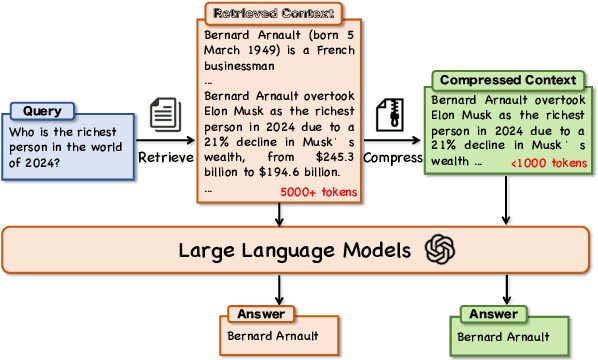



While RAG demonstrates remarkable capabilities in LLM applications, its effectiveness is hindered by the ever-increasing length of retrieved contexts, which introduces information redundancy and substantial computational overhead. Existing context pruning methods, such as LLMLingua, lack contextual awareness and offer limited flexibility in controlling compression rates, often resulting in either insufficient pruning or excessive information loss. In this paper, we propose AttentionRAG, an attention-guided context pruning method for RAG systems. The core idea of AttentionRAG lies in its attention focus mechanism, which reformulates RAG queries into a next-token prediction paradigm. This mechanism isolates the query's semantic focus to a single token, enabling precise and efficient attention calculation between queries and retrieved contexts. Extensive experiments on LongBench and Babilong benchmarks show that AttentionRAG achieves up to 6.3$\times$ context compression while outperforming LLMLingua methods by around 10\% in key metrics.