 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA TRRIP Down Memory Lane: Temperature-Based Re-Reference Interval Prediction For Instruction Caching
Sep 17, 2025Modern mobile CPU software pose challenges for conventional instruction cache replacement policies due to their complex runtime behavior causing high reuse distance between executions of the same instruction. Mobile code commonly suffers from large amounts of stalls in the CPU frontend and thus starvation of the rest of the CPU resources. Complexity of these applications and their code footprint are projected to grow at a rate faster than available on-chip memory due to power and area constraints, making conventional hardware-centric methods for managing instruction caches to be inadequate. We present a novel software-hardware co-design approach called TRRIP (Temperature-based Re-Reference Interval Prediction) that enables the compiler to analyze, classify, and transform code based on "temperature" (hot/cold), and to provide the hardware with a summary of code temperature information through a well-defined OS interface based on using code page attributes. TRRIP's lightweight hardware extension employs code temperature attributes to optimize the instruction cache replacement policy resulting in the eviction rate reduction of hot code. TRRIP is designed to be practical and adoptable in real mobile systems that have strict feature requirements on both the software and hardware components. TRRIP can reduce the L2 MPKI for instructions by 26.5% resulting in geomean speedup of 3.9%, on top of RRIP cache replacement running mobile code already optimized using PGO.
Low-Rank Deep Convolutional Neural Network for Multi-Task Learning
Apr 12, 2019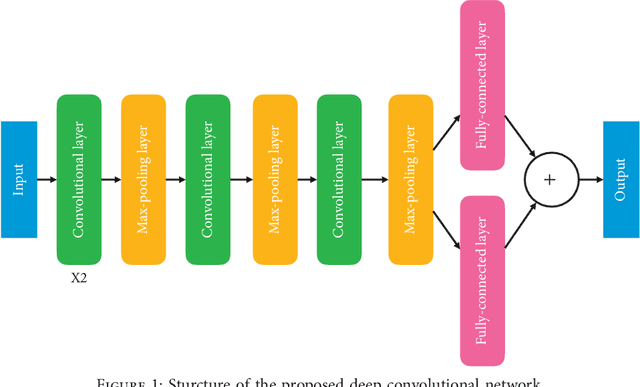
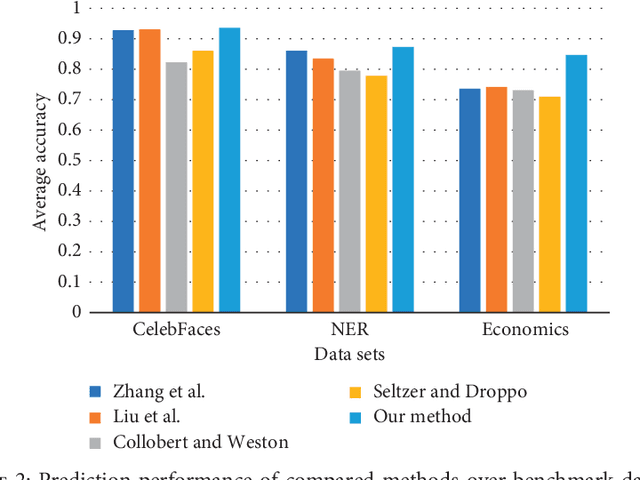
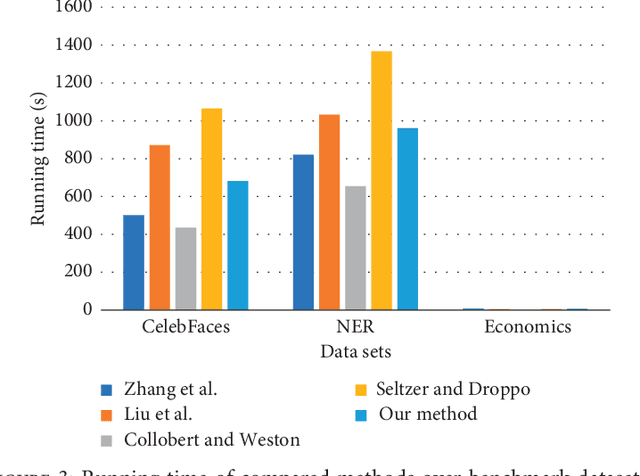
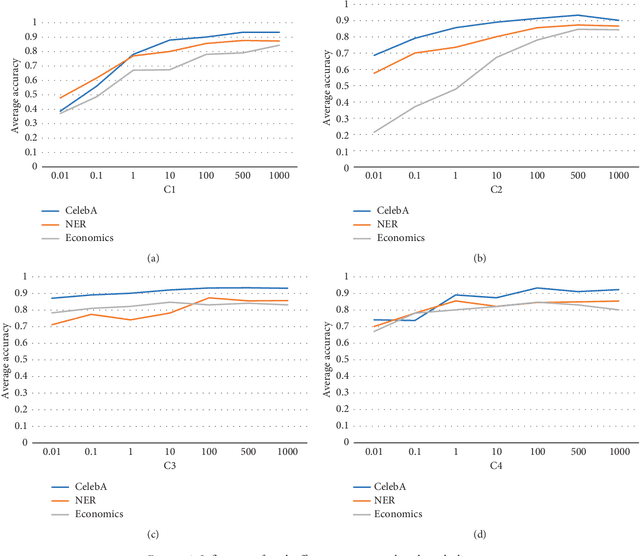
In this paper, we propose a novel multi-task learning method based on the deep convolutional network. The proposed deep network has four convolutional layers, three max-pooling layers, and two parallel fully connected layers. To adjust the deep network to multi-task learning problem, we propose to learn a low-rank deep network so that the relation among different tasks can be explored. We proposed to minimize the number of independent parameter rows of one fully connected layer to explore the relations among different tasks, which is measured by the nuclear norm of the parameter of one fully connected layer, and seek a low-rank parameter matrix. Meanwhile, we also propose to regularize another fully connected layer by sparsity penalty, so that the useful features learned by the lower layers can be selected. The learning problem is solved by an iterative algorithm based on gradient descent and back-propagation algorithms. The proposed algorithm is evaluated over benchmark data sets of multiple face attribute prediction, multi-task natural language processing, and joint economics index predictions. The evaluation results show the advantage of the low-rank deep CNN model over multi-task problems.
Cross-domain attribute representation based on convolutional neural network
May 17, 2018
In the problem of domain transfer learning, we learn a model for the predic-tion in a target domain from the data of both some source domains and the target domain, where the target domain is in lack of labels while the source domain has sufficient labels. Besides the instances of the data, recently the attributes of data shared across domains are also explored and proven to be very helpful to leverage the information of different domains. In this paper, we propose a novel learning framework for domain-transfer learning based on both instances and attributes. We proposed to embed the attributes of dif-ferent domains by a shared convolutional neural network (CNN), learn a domain-independent CNN model to represent the information shared by dif-ferent domains by matching across domains, and a domain-specific CNN model to represent the information of each domain. The concatenation of the three CNN model outputs is used to predict the class label. An iterative algo-rithm based on gradient descent method is developed to learn the parameters of the model. The experiments over benchmark datasets show the advantage of the proposed model.
Domain transfer convolutional attribute embedding
Apr 01, 2018
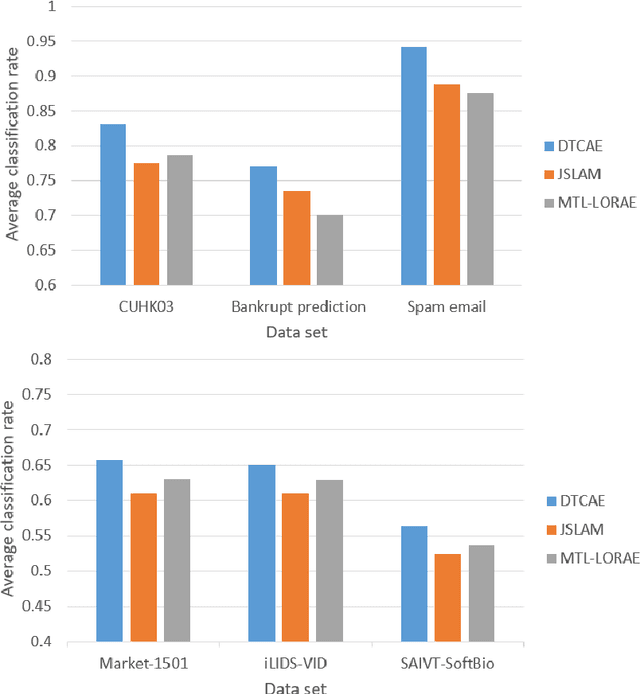
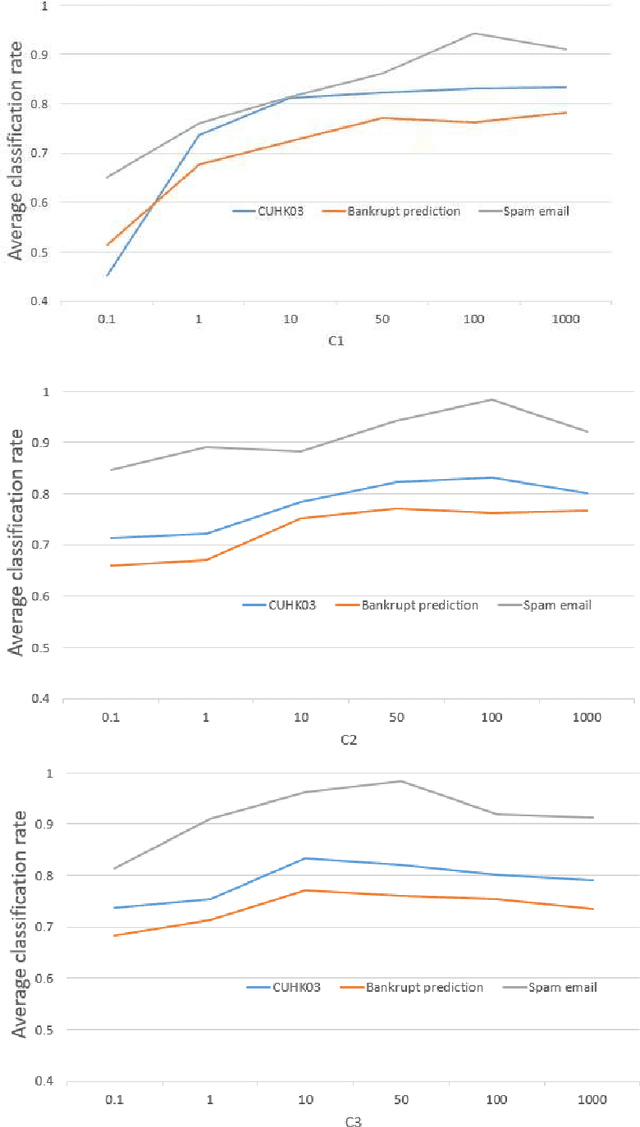
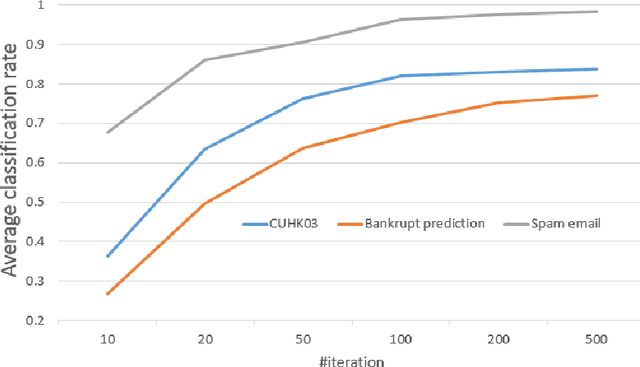
In this paper, we study the problem of transfer learning with the attribute data. In the transfer learning problem, we want to leverage the data of the auxiliary and the target domains to build an effective model for the classification problem in the target domain. Meanwhile, the attributes are naturally stable cross different domains. This strongly motives us to learn effective domain transfer attribute representations. To this end, we proposed to embed the attributes of the data to a common space by using the powerful convolutional neural network (CNN) model. The convolutional representations of the data points are mapped to the corresponding attributes so that they can be effective embedding of the attributes. We also represent the data of different domains by a domain-independent CNN, ant a domain-specific CNN, and combine their outputs with the attribute embedding to build the classification model. An joint learning framework is constructed to minimize the classification errors, the attribute mapping error, the mismatching of the domain-independent representations cross different domains, and to encourage the the neighborhood smoothness of representations in the target domain. The minimization problem is solved by an iterative algorithm based on gradient descent. Experiments over benchmark data sets of person re-identification, bankruptcy prediction, and spam email detection, show the effectiveness of the proposed method.