 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-round jailbreak attack on large language models
Oct 15, 2024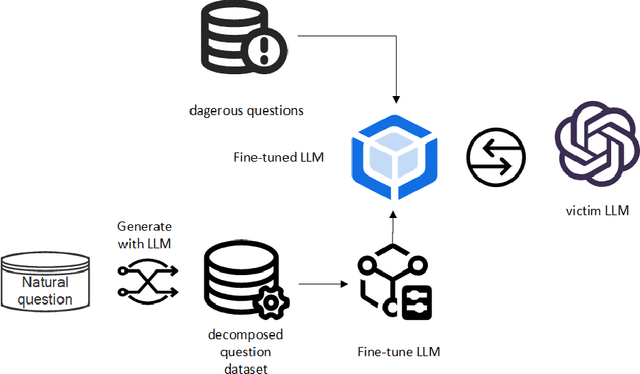

Ensuring the safety and alignment of large language models (LLMs) with human values is crucial for generating responses that are beneficial to humanity. While LLMs have the capability to identify and avoid harmful queries, they remain vulnerable to "jailbreak" attacks, where carefully crafted prompts can induce the generation of toxic content. Traditional single-round jailbreak attacks, such as GCG and AutoDAN, do not alter the sensitive words in the dangerous prompts. Although they can temporarily bypass the model's safeguards through prompt engineering, their success rate drops significantly as the LLM is further fine-tuned, and they cannot effectively circumvent static rule-based filters that remove the hazardous vocabulary. In this study, to better understand jailbreak attacks, we introduce a multi-round jailbreak approach. This method can rewrite the dangerous prompts, decomposing them into a series of less harmful sub-questions to bypass the LLM's safety checks. We first use the LLM to perform a decomposition task, breaking down a set of natural language questions into a sequence of progressive sub-questions, which are then used to fine-tune the Llama3-8B model, enabling it to decompose hazardous prompts. The fine-tuned model is then used to break down the problematic prompt, and the resulting sub-questions are sequentially asked to the victim model. If the victim model rejects a sub-question, a new decomposition is generated, and the process is repeated until the final objective is achieved. Our experimental results show a 94\% success rate on the llama2-7B and demonstrate the effectiveness of this approach in circumventing static rule-based filters.
Multiple kernel multivariate performance learning using cutting plane algorithm
Aug 25, 2015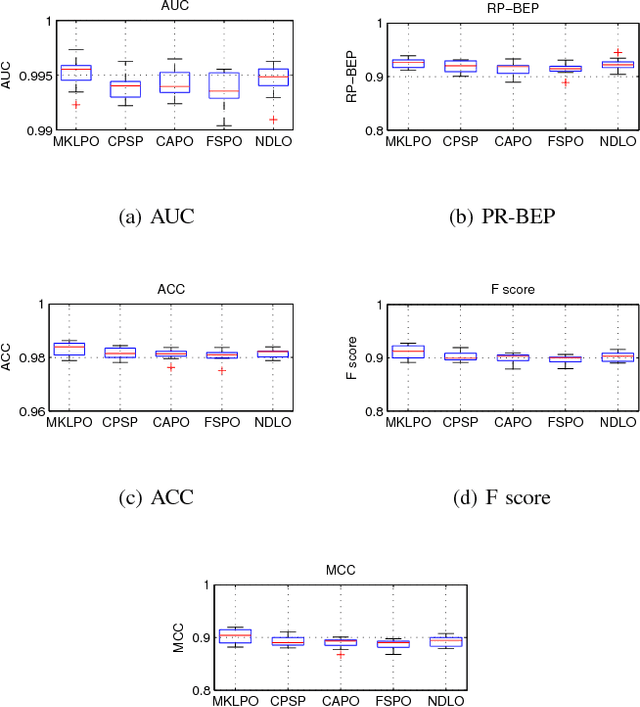
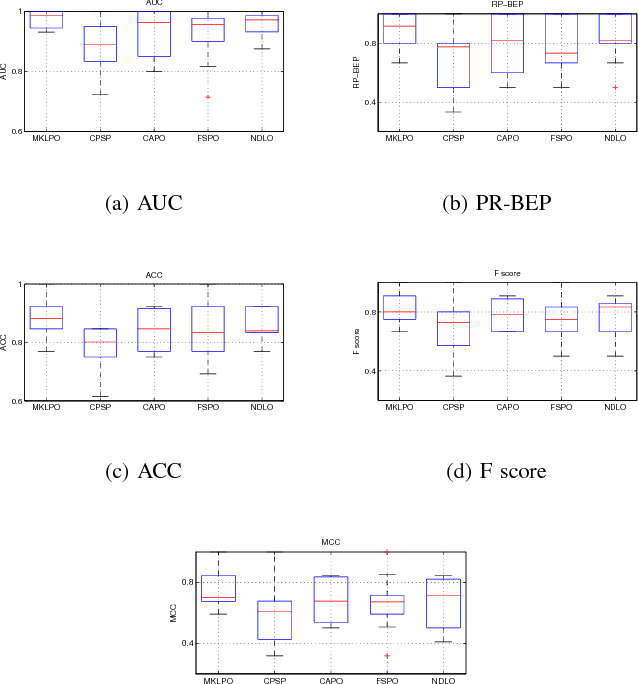
In this paper, we propose a multi-kernel classifier learning algorithm to optimize a given nonlinear and nonsmoonth multivariate classifier performance measure. Moreover, to solve the problem of kernel function selection and kernel parameter tuning, we proposed to construct an optimal kernel by weighted linear combination of some candidate kernels. The learning of the classifier parameter and the kernel weight are unified in a single objective function considering to minimize the upper boundary of the given multivariate performance measure. The objective function is optimized with regard to classifier parameter and kernel weight alternately in an iterative algorithm by using cutting plane algorithm. The developed algorithm is evaluated on two different pattern classification methods with regard to various multivariate performance measure optimization problems. The experiment results show the proposed algorithm outperforms the competing methods.
Image tag completion by local learning
Aug 18, 2015
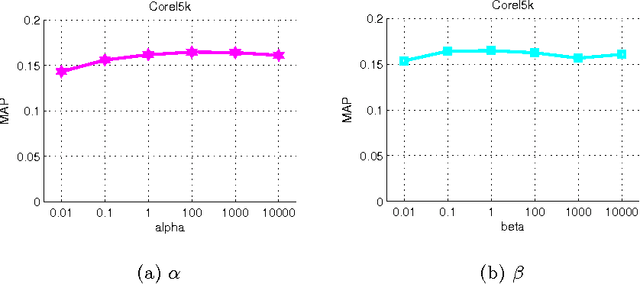
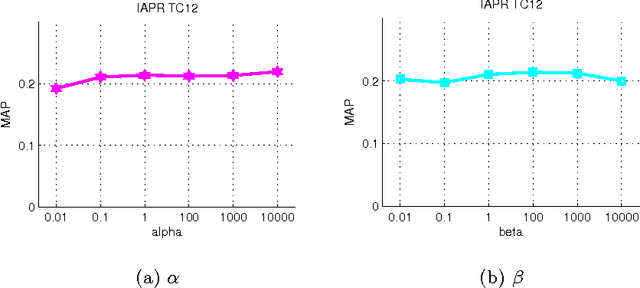
The problem of tag completion is to learn the missing tags of an image. In this paper, we propose to learn a tag scoring vector for each image by local linear learning. A local linear function is used in the neighborhood of each image to predict the tag scoring vectors of its neighboring images. We construct a unified objective function for the learning of both tag scoring vectors and local linear function parame- ters. In the objective, we impose the learned tag scoring vectors to be consistent with the known associations to the tags of each image, and also minimize the prediction error of each local linear function, while reducing the complexity of each local function. The objective function is optimized by an alternate optimization strategy and gradient descent methods in an iterative algorithm. We compare the proposed algorithm against different state-of-the-art tag completion methods, and the results show its advantages.
Representing data by sparse combination of contextual data points for classification
Aug 18, 2015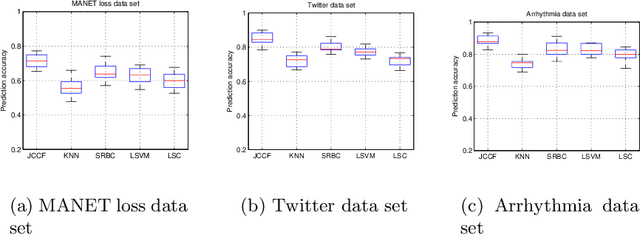
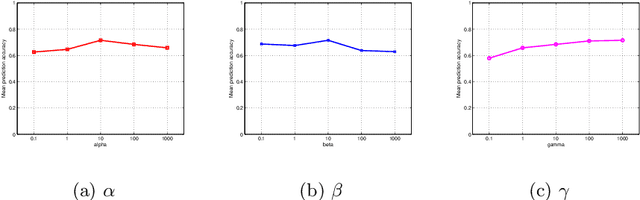
In this paper, we study the problem of using contextual da- ta points of a data point for its classification problem. We propose to represent a data point as the sparse linear reconstruction of its context, and learn the sparse context to gather with a linear classifier in a su- pervised way to increase its discriminative ability. We proposed a novel formulation for context learning, by modeling the learning of context reconstruction coefficients and classifier in a unified objective. In this objective, the reconstruction error is minimized and the coefficient spar- sity is encouraged. Moreover, the hinge loss of the classifier is minimized and the complexity of the classifier is reduced. This objective is opti- mized by an alternative strategy in an iterative algorithm. Experiments on three benchmark data set show its advantage over state-of-the-art context-based data representation and classification methods.
Supervised cross-modal factor analysis for multiple modal data classification
Aug 18, 2015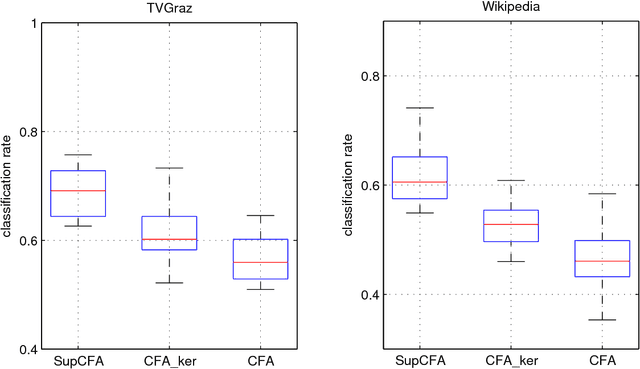
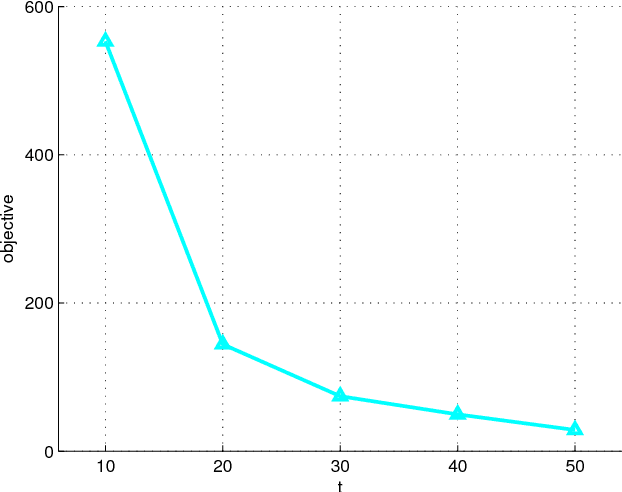
In this paper we study the problem of learning from multiple modal data for purpose of document classification. In this problem, each document is composed two different modals of data, i.e., an image and a text. Cross-modal factor analysis (CFA) has been proposed to project the two different modals of data to a shared data space, so that the classification of a image or a text can be performed directly in this space. A disadvantage of CFA is that it has ignored the supervision information. In this paper, we improve CFA by incorporating the supervision information to represent and classify both image and text modals of documents. We project both image and text data to a shared data space by factor analysis, and then train a class label predictor in the shared space to use the class label information. The factor analysis parameter and the predictor parameter are learned jointly by solving one single objective function. With this objective function, we minimize the distance between the projections of image and text of the same document, and the classification error of the projection measured by hinge loss function. The objective function is optimized by an alternate optimization strategy in an iterative algorithm. Experiments in two different multiple modal document data sets show the advantage of the proposed algorithm over other CFA methods.