 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Humanoid Whole-Body Control via Pretraining and Fast Adaptation
Feb 12, 2026Learning a general whole-body controller for humanoid robots remains challenging due to the diversity of motion distributions, the difficulty of fast adaptation, and the need for robust balance in high-dynamic scenarios. Existing approaches often require task-specific training or suffer from performance degradation when adapting to new motions. In this paper, we present FAST, a general humanoid whole-body control framework that enables Fast Adaptation and Stable Motion Tracking. FAST introduces Parseval-Guided Residual Policy Adaptation, which learns a lightweight delta action policy under orthogonality and KL constraints, enabling efficient adaptation to out-of-distribution motions while mitigating catastrophic forgetting. To further improve physical robustness, we propose Center-of-Mass-Aware Control, which incorporates CoM-related observations and objectives to enhance balance when tracking challenging reference motions. Extensive experiments in simulation and real-world deployment demonstrate that FAST consistently outperforms state-of-the-art baselines in robustness, adaptation efficiency, and generalization.
Multi-round jailbreak attack on large language models
Oct 15, 2024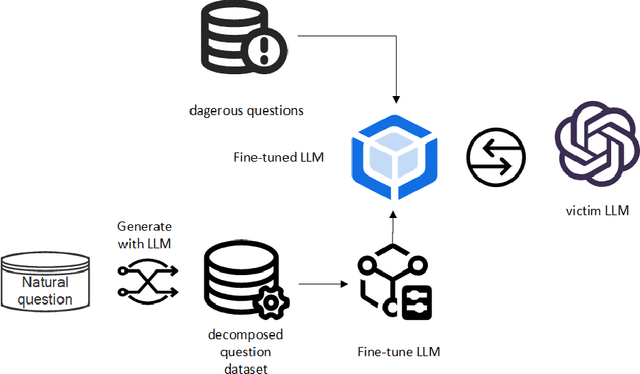

Ensuring the safety and alignment of large language models (LLMs) with human values is crucial for generating responses that are beneficial to humanity. While LLMs have the capability to identify and avoid harmful queries, they remain vulnerable to "jailbreak" attacks, where carefully crafted prompts can induce the generation of toxic content. Traditional single-round jailbreak attacks, such as GCG and AutoDAN, do not alter the sensitive words in the dangerous prompts. Although they can temporarily bypass the model's safeguards through prompt engineering, their success rate drops significantly as the LLM is further fine-tuned, and they cannot effectively circumvent static rule-based filters that remove the hazardous vocabulary. In this study, to better understand jailbreak attacks, we introduce a multi-round jailbreak approach. This method can rewrite the dangerous prompts, decomposing them into a series of less harmful sub-questions to bypass the LLM's safety checks. We first use the LLM to perform a decomposition task, breaking down a set of natural language questions into a sequence of progressive sub-questions, which are then used to fine-tune the Llama3-8B model, enabling it to decompose hazardous prompts. The fine-tuned model is then used to break down the problematic prompt, and the resulting sub-questions are sequentially asked to the victim model. If the victim model rejects a sub-question, a new decomposition is generated, and the process is repeated until the final objective is achieved. Our experimental results show a 94\% success rate on the llama2-7B and demonstrate the effectiveness of this approach in circumventing static rule-based filters.
Rethinking the Principle of Gradient Smooth Methods in Model Explanation
Oct 10, 2024



Gradient Smoothing is an efficient approach to reducing noise in gradient-based model explanation method. SmoothGrad adds Gaussian noise to mitigate much of these noise. However, the crucial hyper-parameter in this method, the variance $\sigma$ of Gaussian noise, is set manually or with heuristic approach. However, it results in the smoothed gradients still containing a certain amount of noise. In this paper, we aim to interpret SmoothGrad as a corollary of convolution, thereby re-understanding the gradient noise and the role of $\sigma$ from the perspective of confidence level. Furthermore, we propose an adaptive gradient smoothing method, AdaptGrad, based on these insights. Through comprehensive experiments, both qualitative and quantitative results demonstrate that AdaptGrad could effectively reduce almost all the noise in vanilla gradients compared with baselines methods. AdaptGrad is simple and universal, making it applicable for enhancing gradient-based interpretability methods for better visualization.
$\mathrm{E^{2}CFD}$: Towards Effective and Efficient Cost Function Design for Safe Reinforcement Learning via Large Language Model
Jul 08, 2024Different classes of safe reinforcement learning algorithms have shown satisfactory performance in various types of safety requirement scenarios. However, the existing methods mainly address one or several classes of specific safety requirement scenario problems and cannot be applied to arbitrary safety requirement scenarios. In addition, the optimization objectives of existing reinforcement learning algorithms are misaligned with the task requirements. Based on the need to address these issues, we propose $\mathrm{E^{2}CFD}$, an effective and efficient cost function design framework. $\mathrm{E^{2}CFD}$ leverages the capabilities of a large language model (LLM) to comprehend various safety scenarios and generate corresponding cost functions. It incorporates the \textit{fast performance evaluation (FPE)} method to facilitate rapid and iterative updates to the generated cost function. Through this iterative process, $\mathrm{E^{2}CFD}$ aims to obtain the most suitable cost function for policy training, tailored to the specific tasks within the safety scenario. Experiments have proven that the performance of policies trained using this framework is superior to traditional safe reinforcement learning algorithms and policies trained with carefully designed cost functions.
Axiomatization of Gradient Smoothing in Neural Networks
Jun 29, 2024Gradients play a pivotal role in neural networks explanation. The inherent high dimensionality and structural complexity of neural networks result in the original gradients containing a significant amount of noise. While several approaches were proposed to reduce noise with smoothing, there is little discussion of the rationale behind smoothing gradients in neural networks. In this work, we proposed a gradient smooth theoretical framework for neural networks based on the function mollification and Monte Carlo integration. The framework intrinsically axiomatized gradient smoothing and reveals the rationale of existing methods. Furthermore, we provided an approach to design new smooth methods derived from the framework. By experimental measurement of several newly designed smooth methods, we demonstrated the research potential of our framework.
Joint Alignment of Multi-Task Feature and Label Spaces for Emotion Cause Pair Extraction
Sep 09, 2022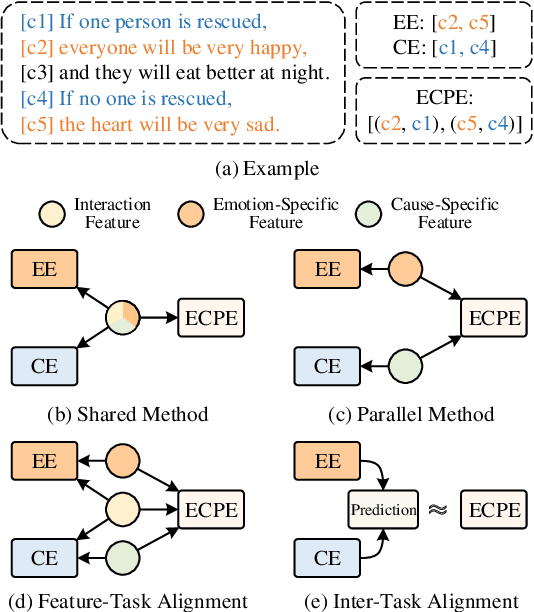
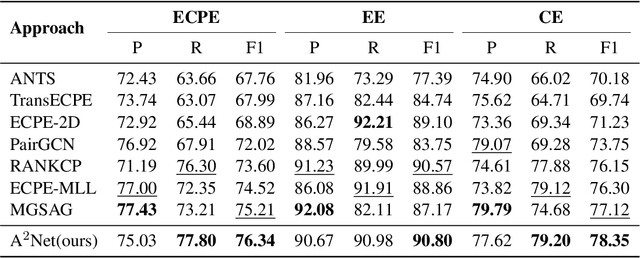
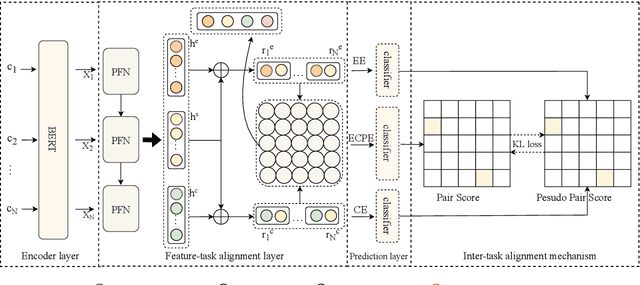
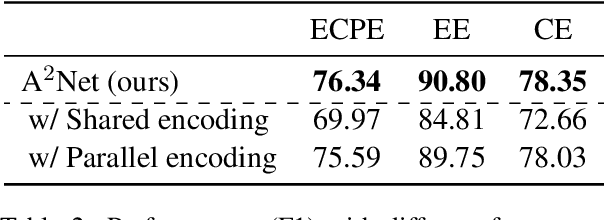
Emotion cause pair extraction (ECPE), as one of the derived subtasks of emotion cause analysis (ECA), shares rich inter-related features with emotion extraction (EE) and cause extraction (CE). Therefore EE and CE are frequently utilized as auxiliary tasks for better feature learning, modeled via multi-task learning (MTL) framework by prior works to achieve state-of-the-art (SoTA) ECPE results. However, existing MTL-based methods either fail to simultaneously model the specific features and the interactive feature in between, or suffer from the inconsistency of label prediction. In this work, we consider addressing the above challenges for improving ECPE by performing two alignment mechanisms with a novel A^2Net model. We first propose a feature-task alignment to explicitly model the specific emotion-&cause-specific features and the shared interactive feature. Besides, an inter-task alignment is implemented, in which the label distance between the ECPE and the combinations of EE&CE are learned to be narrowed for better label consistency. Evaluations of benchmarks show that our methods outperform current best-performing systems on all ECA subtasks. Further analysis proves the importance of our proposed alignment mechanisms for the task.