 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-round jailbreak attack on large language models
Paper and Code
Oct 15, 2024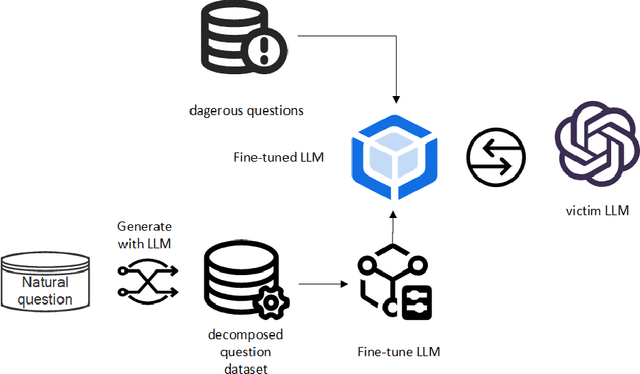

Ensuring the safety and alignment of large language models (LLMs) with human values is crucial for generating responses that are beneficial to humanity. While LLMs have the capability to identify and avoid harmful queries, they remain vulnerable to "jailbreak" attacks, where carefully crafted prompts can induce the generation of toxic content. Traditional single-round jailbreak attacks, such as GCG and AutoDAN, do not alter the sensitive words in the dangerous prompts. Although they can temporarily bypass the model's safeguards through prompt engineering, their success rate drops significantly as the LLM is further fine-tuned, and they cannot effectively circumvent static rule-based filters that remove the hazardous vocabulary. In this study, to better understand jailbreak attacks, we introduce a multi-round jailbreak approach. This method can rewrite the dangerous prompts, decomposing them into a series of less harmful sub-questions to bypass the LLM's safety checks. We first use the LLM to perform a decomposition task, breaking down a set of natural language questions into a sequence of progressive sub-questions, which are then used to fine-tune the Llama3-8B model, enabling it to decompose hazardous prompts. The fine-tuned model is then used to break down the problematic prompt, and the resulting sub-questions are sequentially asked to the victim model. If the victim model rejects a sub-question, a new decomposition is generated, and the process is repeated until the final objective is achieved. Our experimental results show a 94\% success rate on the llama2-7B and demonstrate the effectiveness of this approach in circumventing static rule-based filters.