 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised cross-modal factor analysis for multiple modal data classification
Paper and Code
Aug 18, 2015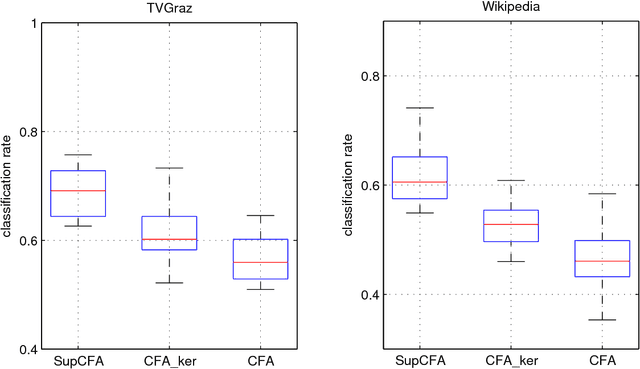
In this paper we study the problem of learning from multiple modal data for purpose of document classification. In this problem, each document is composed two different modals of data, i.e., an image and a text. Cross-modal factor analysis (CFA) has been proposed to project the two different modals of data to a shared data space, so that the classification of a image or a text can be performed directly in this space. A disadvantage of CFA is that it has ignored the supervision information. In this paper, we improve CFA by incorporating the supervision information to represent and classify both image and text modals of documents. We project both image and text data to a shared data space by factor analysis, and then train a class label predictor in the shared space to use the class label information. The factor analysis parameter and the predictor parameter are learned jointly by solving one single objective function. With this objective function, we minimize the distance between the projections of image and text of the same document, and the classification error of the projection measured by hinge loss function. The objective function is optimized by an alternate optimization strategy in an iterative algorithm. Experiments in two different multiple modal document data sets show the advantage of the proposed algorithm over other CFA methods.