 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustRank: a Visual Quality Measure Trained on Perceptual Data for Sorting Scatterplots by Cluster Patterns
Jun 01, 2021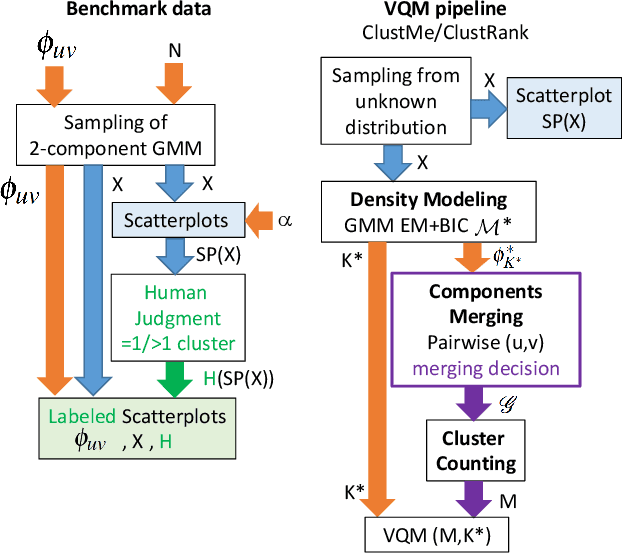
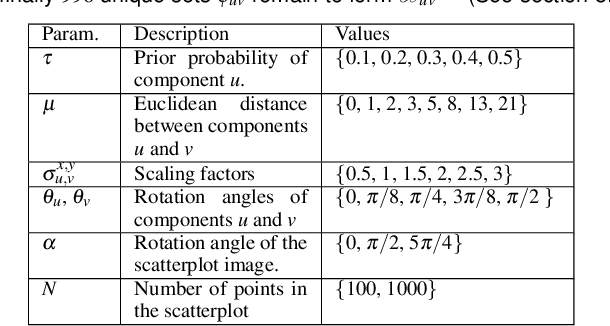
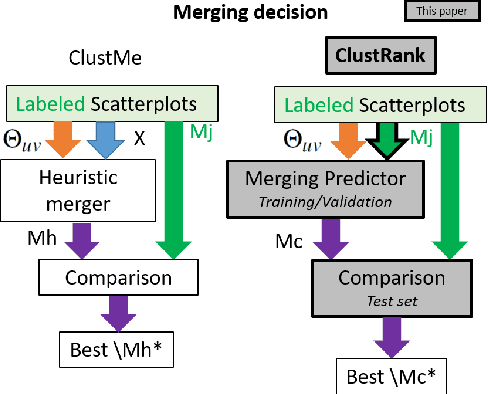
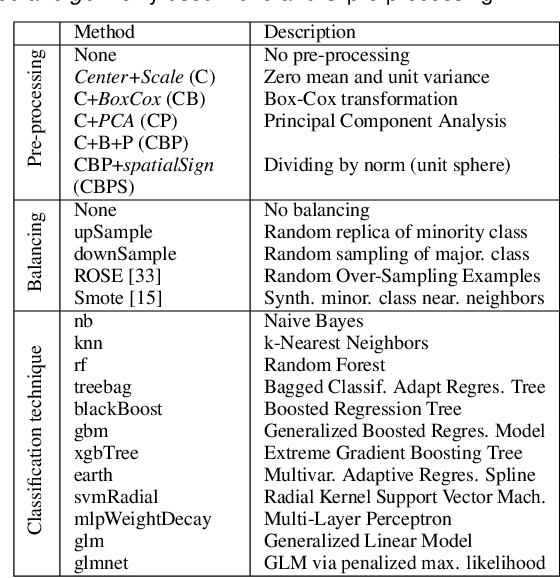
Visual quality measures (VQMs) are designed to support analysts by automatically detecting and quantifying patterns in visualizations. We propose a new data-driven technique called ClustRank that allows to rank scatterplots according to visible grouping patterns. Our model first encodes scatterplots in the parametric space of a Gaussian Mixture Model, and then uses a classifier trained on human judgment data to estimate the perceptual complexity of grouping patterns. The numbers of initial mixture components and final combined groups determine the rank of the scatterplot. ClustRank improves on existing VQM techniques by mimicking human judgments on two-Gaussian cluster patterns and gives more accuracy when ranking general cluster patterns in scatterplots. We demonstrate its benefit by analyzing kinship data for genome-wide association studies, a domain in which experts rely on the visual analysis of large sets of scatterplots. We make the three benchmark datasets and the ClustRank VQM available for practical use and further improvements.
Supervised cross-modal factor analysis for multiple modal data classification
Aug 18, 2015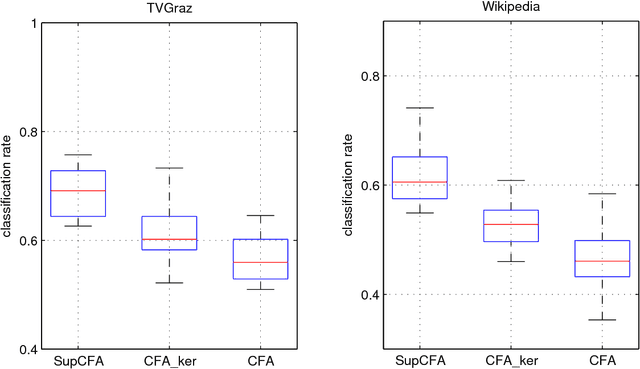
In this paper we study the problem of learning from multiple modal data for purpose of document classification. In this problem, each document is composed two different modals of data, i.e., an image and a text. Cross-modal factor analysis (CFA) has been proposed to project the two different modals of data to a shared data space, so that the classification of a image or a text can be performed directly in this space. A disadvantage of CFA is that it has ignored the supervision information. In this paper, we improve CFA by incorporating the supervision information to represent and classify both image and text modals of documents. We project both image and text data to a shared data space by factor analysis, and then train a class label predictor in the shared space to use the class label information. The factor analysis parameter and the predictor parameter are learned jointly by solving one single objective function. With this objective function, we minimize the distance between the projections of image and text of the same document, and the classification error of the projection measured by hinge loss function. The objective function is optimized by an alternate optimization strategy in an iterative algorithm. Experiments in two different multiple modal document data sets show the advantage of the proposed algorithm over other CFA methods.
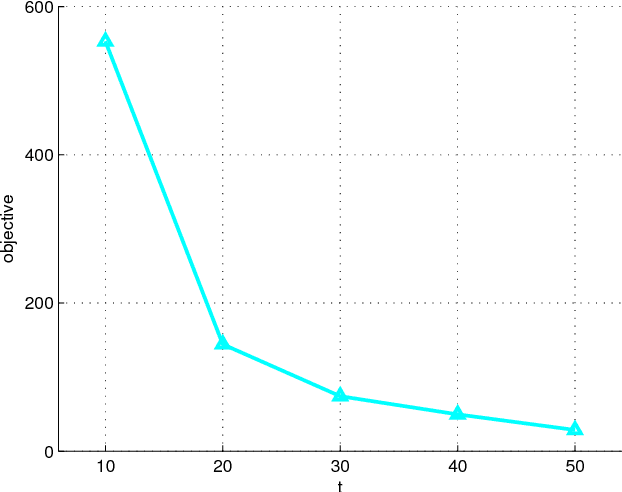
Multiple graph regularized protein domain ranking
Apr 21, 2013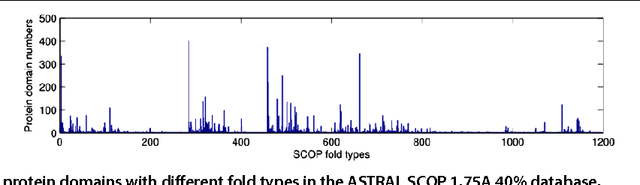



Background Protein domain ranking is a fundamental task in structural biology. Most protein domain ranking methods rely on the pairwise comparison of protein domains while neglecting the global manifold structure of the protein domain database. Recently, graph regularized ranking that exploits the global structure of the graph defined by the pairwise similarities has been proposed. However, the existing graph regularized ranking methods are very sensitive to the choice of the graph model and parameters, and this remains a difficult problem for most of the protein domain ranking methods. Results To tackle this problem, we have developed the Multiple Graph regularized Ranking algorithm, MultiG- Rank. Instead of using a single graph to regularize the ranking scores, MultiG-Rank approximates the intrinsic manifold of protein domain distribution by combining multiple initial graphs for the regularization. Graph weights are learned with ranking scores jointly and automatically, by alternately minimizing an ob- jective function in an iterative algorithm. Experimental results on a subset of the ASTRAL SCOP protein domain database demonstrate that MultiG-Rank achieves a better ranking performance than single graph regularized ranking methods and pairwise similarity based ranking methods. Conclusion The problem of graph model and parameter selection in graph regularized protein domain ranking can be solved effectively by combining multiple graphs. This aspect of generalization introduces a new frontier in applying multiple graphs to solving protein domain ranking applications.
* 21 pages