 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustRank: a Visual Quality Measure Trained on Perceptual Data for Sorting Scatterplots by Cluster Patterns
Jun 01, 2021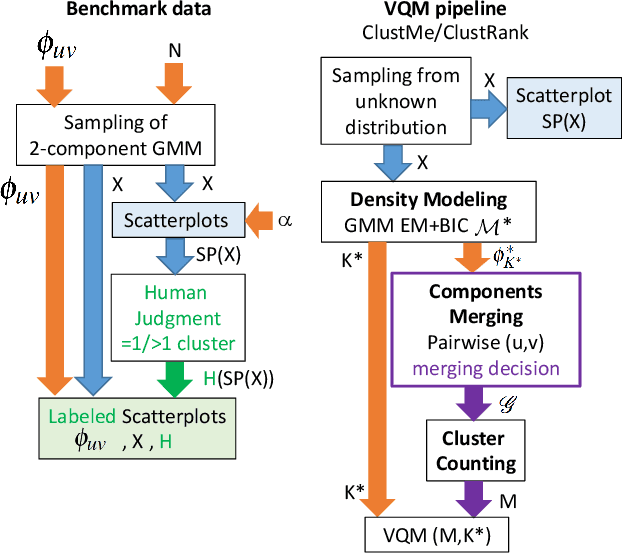
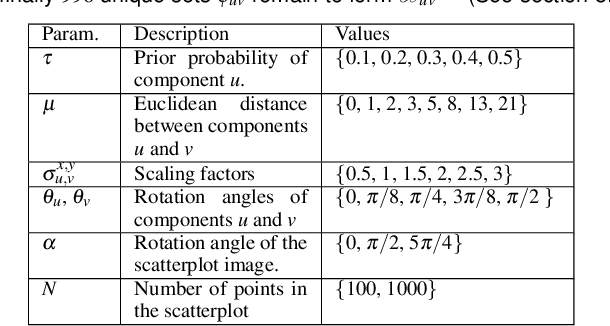
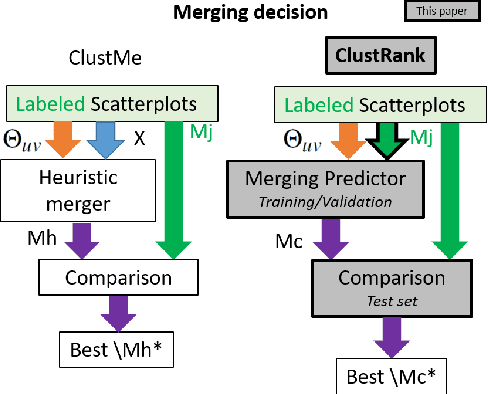
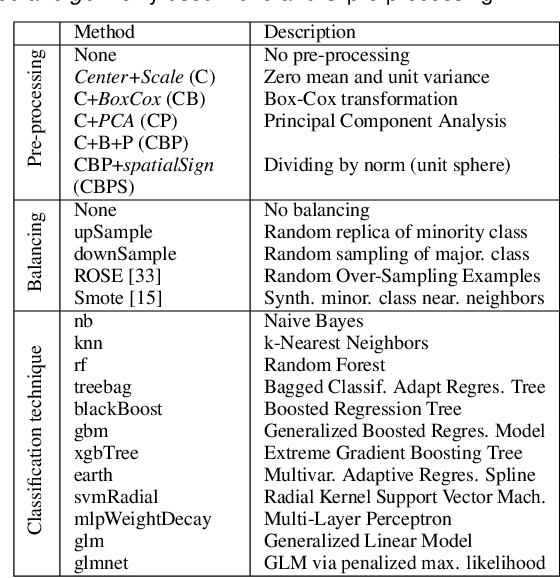
Visual quality measures (VQMs) are designed to support analysts by automatically detecting and quantifying patterns in visualizations. We propose a new data-driven technique called ClustRank that allows to rank scatterplots according to visible grouping patterns. Our model first encodes scatterplots in the parametric space of a Gaussian Mixture Model, and then uses a classifier trained on human judgment data to estimate the perceptual complexity of grouping patterns. The numbers of initial mixture components and final combined groups determine the rank of the scatterplot. ClustRank improves on existing VQM techniques by mimicking human judgments on two-Gaussian cluster patterns and gives more accuracy when ranking general cluster patterns in scatterplots. We demonstrate its benefit by analyzing kinship data for genome-wide association studies, a domain in which experts rely on the visual analysis of large sets of scatterplots. We make the three benchmark datasets and the ClustRank VQM available for practical use and further improvements.
Fast Computation of Katz Index for Efficient Processing of Link Prediction Queries
Dec 13, 2019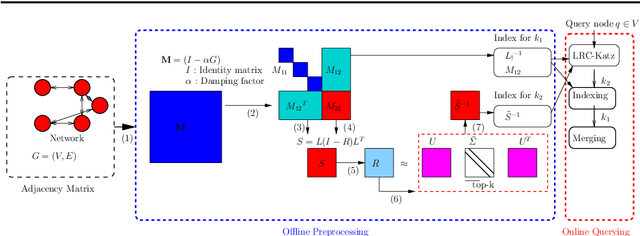
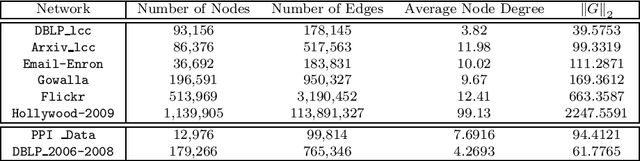
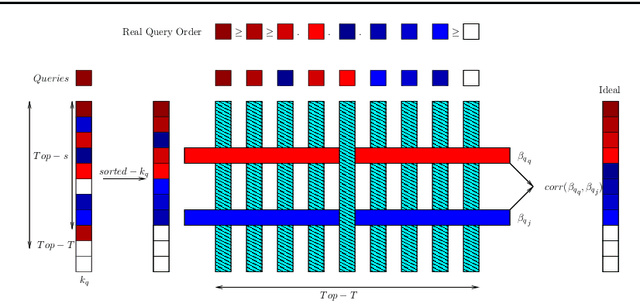

Network proximity computations are among the most common operations in various data mining applications, including link prediction and collaborative filtering. A common measure of network proximity is Katz index, which has been shown to be among the best-performing path-based link prediction algorithms. With the emergence of very large network databases, such proximity computations become an important part of query processing in these databases. Consequently, significant effort has been devoted to developing algorithms for efficient computation of Katz index between a given pair of nodes or between a query node and every other node in the network. Here, we present LRC-Katz, an algorithm based on indexing and low-rank correction to accelerate Katz index-based network proximity queries. Using a variety of very large real-world networks, we show that LRC-Katz outperforms the fastest existing method, Conjugate Gradient, for a wide range of parameter values. We also show that this acceleration in the computation of Katz index can be used to drastically improve the efficiency of processing link prediction queries in very large networks. Motivated by this observation, we propose a new link prediction algorithm that exploits modularity of networks that are encountered in practical applications. Our experimental results on the link prediction problem show that our modularity based algorithm significantly outperforms the state-of-the-art link prediction Katz method.