 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Label Sets for Graph Convolutional Networks
Dec 18, 2019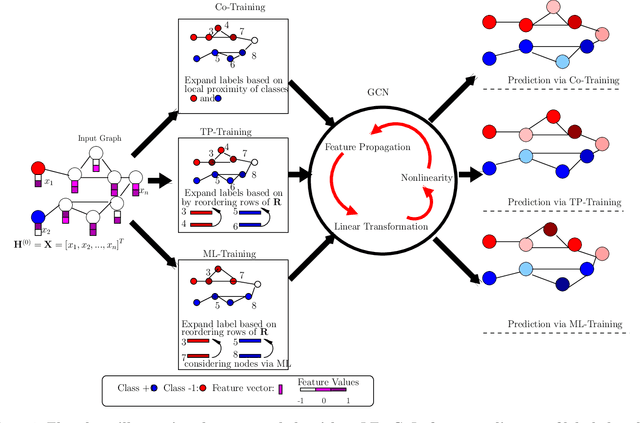
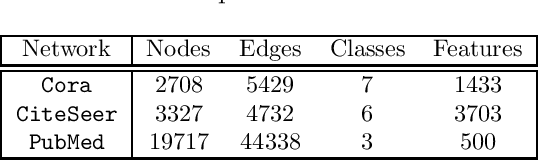
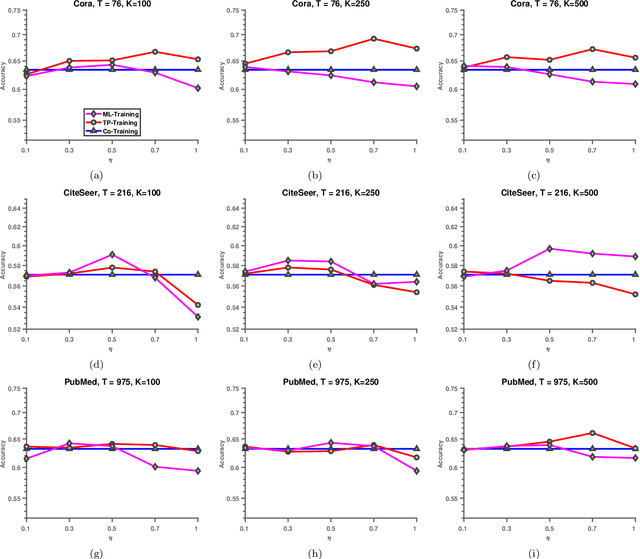
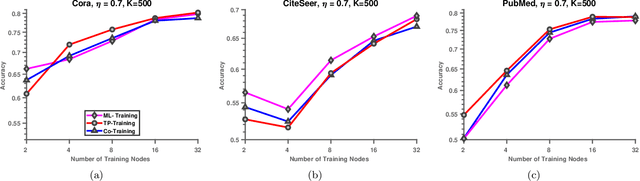
In recent years, Graph Convolutional Networks (GCNs) and their variants have been widely utilized in learning tasks that involve graphs. These tasks include recommendation systems, node classification, among many others. In node classification problem, the input is a graph in which the edges represent the association between pairs of nodes, multi-dimensional feature vectors are associated with the nodes, and some of the nodes in the graph have known labels. The objective is to predict the labels of the nodes that are not labeled, using the nodes features, in conjunction with graph topology. While GCNs have been successfully applied to this problem, the caveats that they inherit from traditional deep learning models pose significant challenges to broad utilization of GCNs in node classification. One such caveat is that training a GCN requires a large number of labeled training instances, which is often not the case in realistic settings. To remedy this requirement, state-of-the-art methods leverage network diffusion-based approaches to propagate labels across the network before training GCNs. However, these approaches ignore the tendency of the network diffusion methods in biasing proximity with centrality, resulting in the propagation of labels to the nodes that are well-connected in the graph. To address this problem, here we present an alternate approach to extrapolating node labels in GCNs in the following three steps: (i) clustering of the network to identify communities, (ii) use of network diffusion algorithms to quantify the proximity of each node to the communities, thereby obtaining a low-dimensional topological profile for each node, (iii) comparing these topological profiles to identify nodes that are most similar to the labeled nodes.
Fast Computation of Katz Index for Efficient Processing of Link Prediction Queries
Dec 13, 2019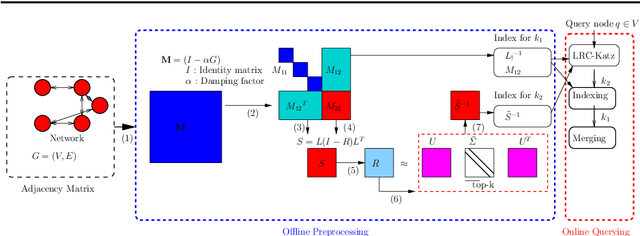
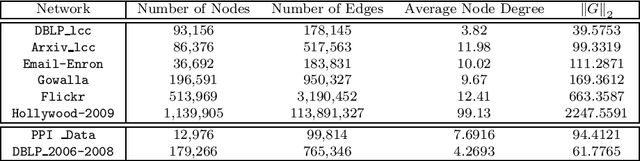
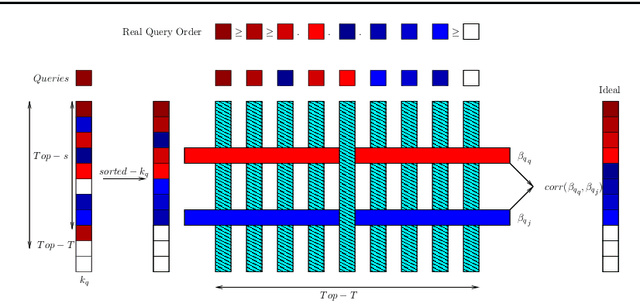

Network proximity computations are among the most common operations in various data mining applications, including link prediction and collaborative filtering. A common measure of network proximity is Katz index, which has been shown to be among the best-performing path-based link prediction algorithms. With the emergence of very large network databases, such proximity computations become an important part of query processing in these databases. Consequently, significant effort has been devoted to developing algorithms for efficient computation of Katz index between a given pair of nodes or between a query node and every other node in the network. Here, we present LRC-Katz, an algorithm based on indexing and low-rank correction to accelerate Katz index-based network proximity queries. Using a variety of very large real-world networks, we show that LRC-Katz outperforms the fastest existing method, Conjugate Gradient, for a wide range of parameter values. We also show that this acceleration in the computation of Katz index can be used to drastically improve the efficiency of processing link prediction queries in very large networks. Motivated by this observation, we propose a new link prediction algorithm that exploits modularity of networks that are encountered in practical applications. Our experimental results on the link prediction problem show that our modularity based algorithm significantly outperforms the state-of-the-art link prediction Katz method.