 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Distillation Process from Deep Generative Models to Tractable Probabilistic Circuits
Paper and Code
Feb 16, 2023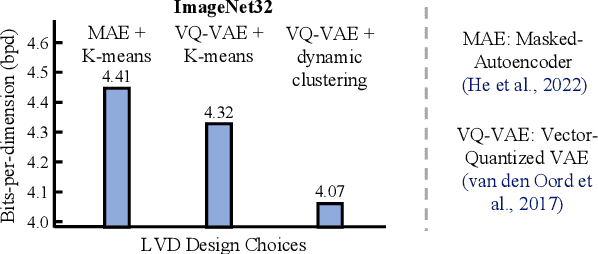
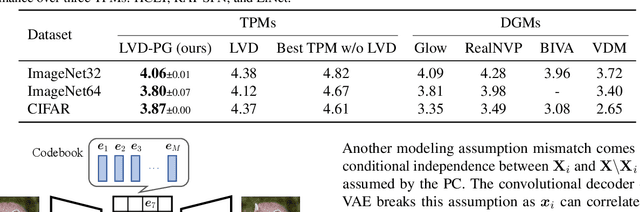
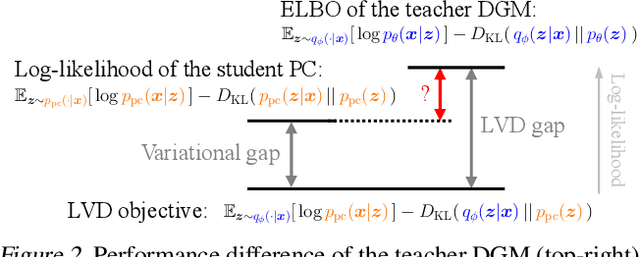
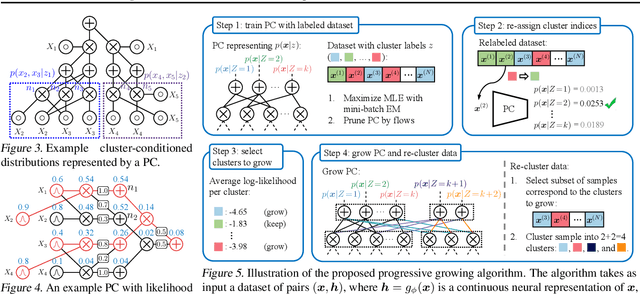
Probabilistic Circuits (PCs) are a general and unified computational framework for tractable probabilistic models that support efficient computation of various inference tasks (e.g., computing marginal probabilities). Towards enabling such reasoning capabilities in complex real-world tasks, Liu et al. (2022) propose to distill knowledge (through latent variable assignments) from less tractable but more expressive deep generative models. However, it is still unclear what factors make this distillation work well. In this paper, we theoretically and empirically discover that the performance of a PC can exceed that of its teacher model. Therefore, instead of performing distillation from the most expressive deep generative model, we study what properties the teacher model and the PC should have in order to achieve good distillation performance. This leads to a generic algorithmic improvement as well as other data-type-specific ones over the existing latent variable distillation pipeline. Empirically, we outperform SoTA TPMs by a large margin on challenging image modeling benchmarks. In particular, on ImageNet32, PCs achieve 4.06 bits-per-dimension, which is only 0.34 behind variational diffusion models (Kingma et al., 2021).