 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Facts (Pix2Fact): Benchmarking Multi-Hop Reasoning for Fine-Grained Visual Fact Checking
Jan 31, 2026Despite progress on general tasks, VLMs struggle with challenges demanding both detailed visual grounding and deliberate knowledge-based reasoning, a synergy not captured by existing benchmarks that evaluate these skills separately. To close this gap, we introduce Pix2Fact, a new visual question-answering benchmark designed to evaluate expert-level perception and knowledge-intensive multi-hop reasoning. Pix2Fact contains 1,000 high-resolution (4K+) images spanning 8 daily-life scenarios and situations, with questions and answers meticulously crafted by annotators holding PhDs from top global universities working in partnership with a professional data annotation firm. Each question requires detailed visual grounding, multi-hop reasoning, and the integration of external knowledge to answer. Our evaluation of 9 state-of-the-art VLMs, including proprietary models like Gemini-3-Pro and GPT-5, reveals the substantial challenge posed by Pix2Fact: the most advanced model achieves only 24.0% average accuracy, in stark contrast to human performance of 56%. This significant gap underscores the limitations of current models in replicating human-level visual comprehension. We believe Pix2Fact will serve as a critical benchmark to drive the development of next-generation multimodal agents that combine fine-grained perception with robust, knowledge-based reasoning.
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025
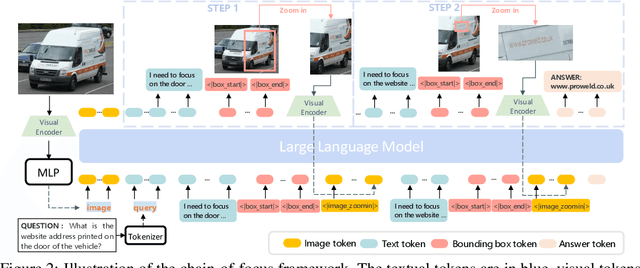


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
May 06, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
Iterative Trajectory Exploration for Multimodal Agents
Apr 30, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
Multi-modal Agent Tuning: Building a VLM-Driven Agent for Efficient Tool Usage
Dec 20, 2024The advancement of large language models (LLMs) prompts the development of multi-modal agents, which are used as a controller to call external tools, providing a feasible way to solve practical tasks. In this paper, we propose a multi-modal agent tuning method that automatically generates multi-modal tool-usage data and tunes a vision-language model (VLM) as the controller for powerful tool-usage reasoning. To preserve the data quality, we prompt the GPT-4o mini model to generate queries, files, and trajectories, followed by query-file and trajectory verifiers. Based on the data synthesis pipeline, we collect the MM-Traj dataset that contains 20K tasks with trajectories of tool usage. Then, we develop the T3-Agent via \underline{T}rajectory \underline{T}uning on VLMs for \underline{T}ool usage using MM-Traj. Evaluations on the GTA and GAIA benchmarks show that the T3-Agent consistently achieves improvements on two popular VLMs: MiniCPM-V-8.5B and {Qwen2-VL-7B}, which outperforms untrained VLMs by $20\%$, showing the effectiveness of the proposed data synthesis pipeline, leading to high-quality data for tool-usage capabilities.
FIRE: A Dataset for Feedback Integration and Refinement Evaluation of Multimodal Models
Jul 16, 2024Vision language models (VLMs) have achieved impressive progress in diverse applications, becoming a prevalent research direction. In this paper, we build FIRE, a feedback-refinement dataset, consisting of 1.1M multi-turn conversations that are derived from 27 source datasets, empowering VLMs to spontaneously refine their responses based on user feedback across diverse tasks. To scale up the data collection, FIRE is collected in two components: FIRE-100K and FIRE-1M, where FIRE-100K is generated by GPT-4V, and FIRE-1M is freely generated via models trained on FIRE-100K. Then, we build FIRE-Bench, a benchmark to comprehensively evaluate the feedback-refining capability of VLMs, which contains 11K feedback-refinement conversations as the test data, two evaluation settings, and a model to provide feedback for VLMs. We develop the FIRE-LLaVA model by fine-tuning LLaVA on FIRE-100K and FIRE-1M, which shows remarkable feedback-refining capability on FIRE-Bench and outperforms untrained VLMs by 50%, making more efficient user-agent interactions and underscoring the significance of the FIRE dataset.