 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Document-Level Biomedical Relation Extraction via Scenario-based Prompt Design in Two-Stage with LLM
May 02, 2025With the advent of artificial intelligence (AI), many researchers are attempting to extract structured information from document-level biomedical literature by fine-tuning large language models (LLMs). However, they face significant challenges such as the need for expensive hardware, like high-performance GPUs and the high labor costs associated with annotating training datasets, especially in biomedical realm. Recent research on LLMs, such as GPT-4 and Llama3, has shown promising performance in zero-shot settings, inspiring us to explore a novel approach to achieve the same results from unannotated full documents using general LLMs with lower hardware and labor costs. Our approach combines two major stages: named entity recognition (NER) and relation extraction (RE). NER identifies chemical, disease and gene entities from the document with synonym and hypernym extraction using an LLM with a crafted prompt. RE extracts relations between entities based on predefined relation schemas and prompts. To enhance the effectiveness of prompt, we propose a five-part template structure and a scenario-based prompt design principles, along with evaluation method to systematically assess the prompts. Finally, we evaluated our approach against fine-tuning and pre-trained models on two biomedical datasets: ChemDisGene and CDR. The experimental results indicate that our proposed method can achieve comparable accuracy levels to fine-tuning and pre-trained models but with reduced human and hardware expenses.
NavHint: Vision and Language Navigation Agent with a Hint Generator
Feb 04, 2024Existing work on vision and language navigation mainly relies on navigation-related losses to establish the connection between vision and language modalities, neglecting aspects of helping the navigation agent build a deep understanding of the visual environment. In our work, we provide indirect supervision to the navigation agent through a hint generator that provides detailed visual descriptions. The hint generator assists the navigation agent in developing a global understanding of the visual environment. It directs the agent's attention toward related navigation details, including the relevant sub-instruction, potential challenges in recognition and ambiguities in grounding, and the targeted viewpoint description. To train the hint generator, we construct a synthetic dataset based on landmarks in the instructions and visible and distinctive objects in the visual environment. We evaluate our method on the R2R and R4R datasets and achieve state-of-the-art on several metrics. The experimental results demonstrate that generating hints not only enhances the navigation performance but also helps improve the interpretability of the agent's actions.
DomiKnowS: A Library for Integration of Symbolic Domain Knowledge in Deep Learning
Aug 27, 2021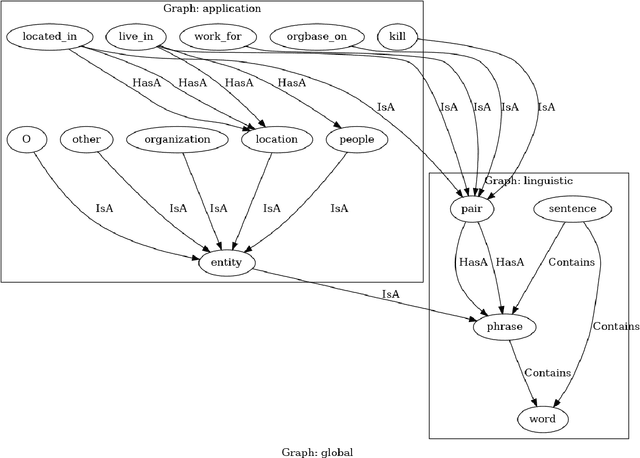
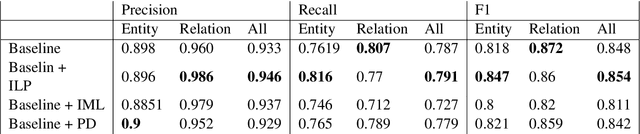

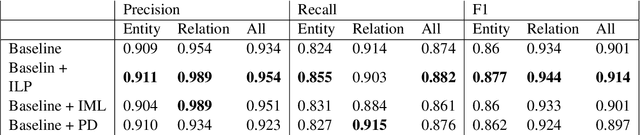
We demonstrate a library for the integration of domain knowledge in deep learning architectures. Using this library, the structure of the data is expressed symbolically via graph declarations and the logical constraints over outputs or latent variables can be seamlessly added to the deep models. The domain knowledge can be defined explicitly, which improves the models' explainability in addition to the performance and generalizability in the low-data regime. Several approaches for such an integration of symbolic and sub-symbolic models have been introduced; however, there is no library to facilitate the programming for such an integration in a generic way while various underlying algorithms can be used. Our library aims to simplify programming for such an integration in both training and inference phases while separating the knowledge representation from learning algorithms. We showcase various NLP benchmark tasks and beyond. The framework is publicly available at Github(https://github.com/HLR/DomiKnowS).
Towards Navigation by Reasoning over Spatial Configurations
May 14, 2021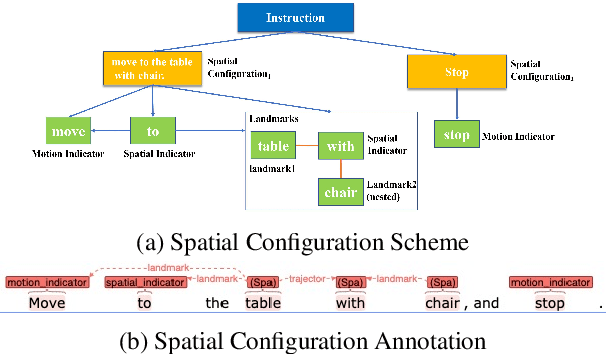
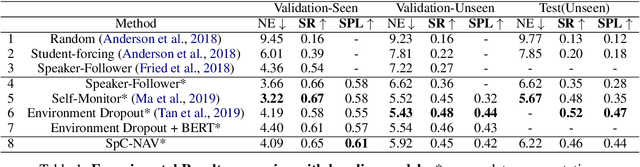
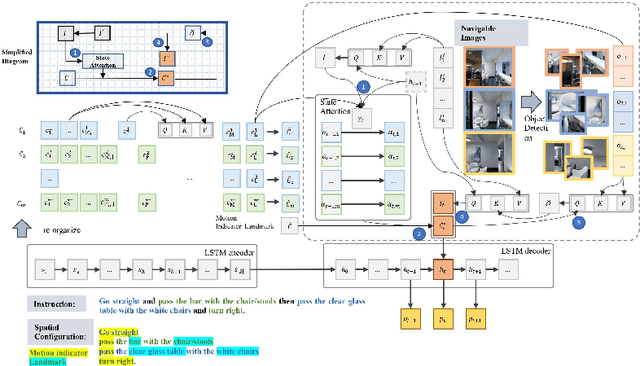
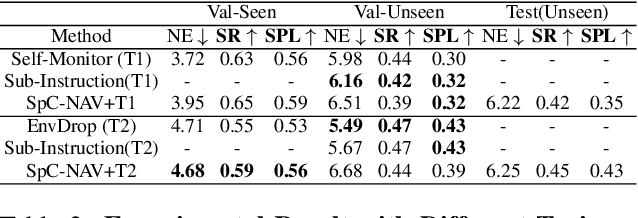
We deal with the navigation problem where the agent follows natural language instructions while observing the environment. Focusing on language understanding, we show the importance of spatial semantics in grounding navigation instructions into visual perceptions. We propose a neural agent that uses the elements of spatial configurations and investigate their influence on the navigation agent's reasoning ability. Moreover, we model the sequential execution order and align visual objects with spatial configurations in the instruction. Our neural agent improves strong baselines on the seen environments and shows competitive performance on the unseen environments. Additionally, the experimental results demonstrate that explicit modeling of spatial semantic elements in the instructions can improve the grounding and spatial reasoning of the model.
Cross-Modality Relevance for Reasoning on Language and Vision
May 12, 2020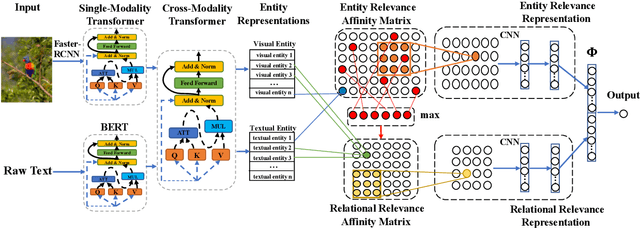
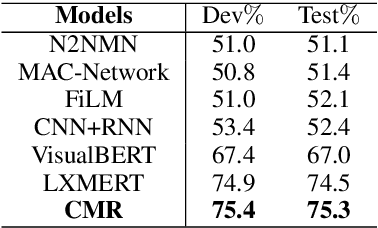
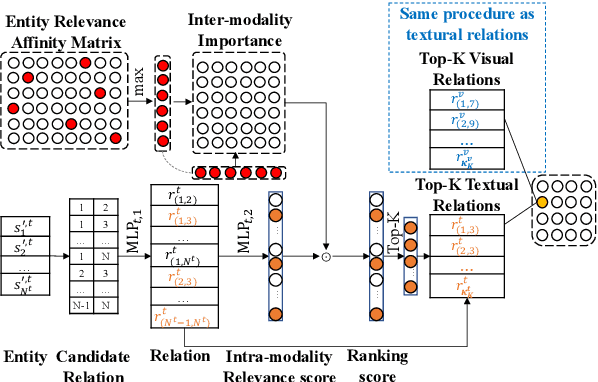
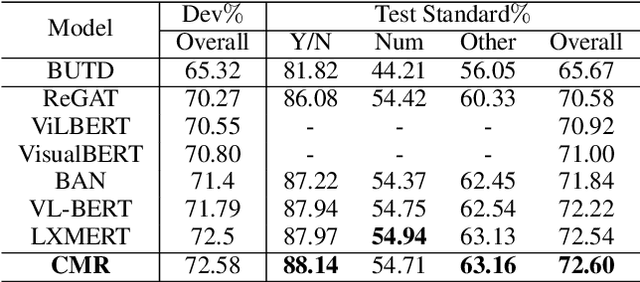
This work deals with the challenge of learning and reasoning over language and vision data for the related downstream tasks such as visual question answering (VQA) and natural language for visual reasoning (NLVR). We design a novel cross-modality relevance module that is used in an end-to-end framework to learn the relevance representation between components of various input modalities under the supervision of a target task, which is more generalizable to unobserved data compared to merely reshaping the original representation space. In addition to modeling the relevance between the textual entities and visual entities, we model the higher-order relevance between entity relations in the text and object relations in the image. Our proposed approach shows competitive performance on two different language and vision tasks using public benchmarks and improves the state-of-the-art published results. The learned alignments of input spaces and their relevance representations by NLVR task boost the training efficiency of VQA task.
A Multi-Modal Chinese Poetry Generation Model
Jun 26, 2018



Recent studies in sequence-to-sequence learning demonstrate that RNN encoder-decoder structure can successfully generate Chinese poetry. However, existing methods can only generate poetry with a given first line or user's intent theme. In this paper, we proposed a three-stage multi-modal Chinese poetry generation approach. Given a picture, the first line, the title and the other lines of the poem are successively generated in three stages. According to the characteristics of Chinese poems, we propose a hierarchy-attention seq2seq model which can effectively capture character, phrase, and sentence information between contexts and improve the symmetry delivered in poems. In addition, the Latent Dirichlet allocation (LDA) model is utilized for title generation and improve the relevance of the whole poem and the title. Compared with strong baseline, the experimental results demonstrate the effectiveness of our approach, using machine evaluations as well as human judgments.