 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoSelfRecon: Purely Self-Supervised Explicit Generalizable 3D Reconstruction of Indoor Scenes from Monocular RGB Views
Apr 10, 2024Current monocular 3D scene reconstruction (3DR) works are either fully-supervised, or not generalizable, or implicit in 3D representation. We propose a novel framework - MonoSelfRecon that for the first time achieves explicit 3D mesh reconstruction for generalizable indoor scenes with monocular RGB views by purely self-supervision on voxel-SDF (signed distance function). MonoSelfRecon follows an Autoencoder-based architecture, decodes voxel-SDF and a generalizable Neural Radiance Field (NeRF), which is used to guide voxel-SDF in self-supervision. We propose novel self-supervised losses, which not only support pure self-supervision, but can be used together with supervised signals to further boost supervised training. Our experiments show that "MonoSelfRecon" trained in pure self-supervision outperforms current best self-supervised indoor depth estimation models and is comparable to 3DR models trained in fully supervision with depth annotations. MonoSelfRecon is not restricted by specific model design, which can be used to any models with voxel-SDF for purely self-supervised manner.
SM3D: Simultaneous Monocular Mapping and 3D Detection
Nov 24, 2021
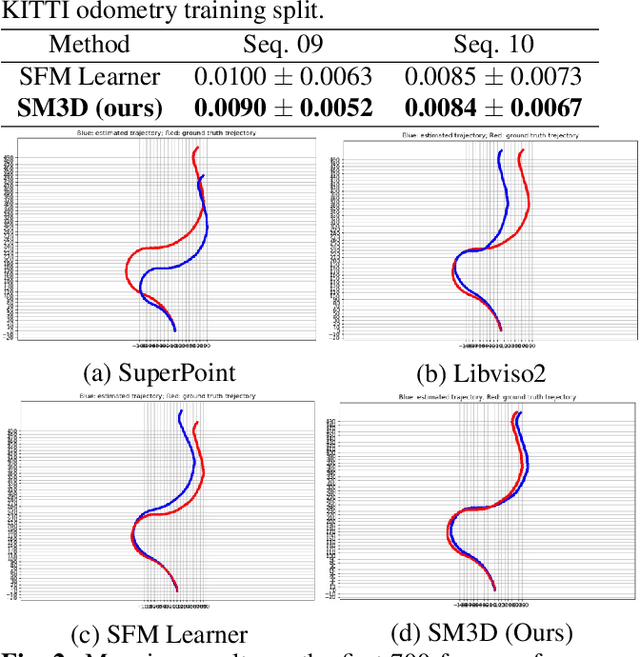

Mapping and 3D detection are two major issues in vision-based robotics, and self-driving. While previous works only focus on each task separately, we present an innovative and efficient multi-task deep learning framework (SM3D) for Simultaneous Mapping and 3D Detection by bridging the gap with robust depth estimation and "Pseudo-LiDAR" point cloud for the first time. The Mapping module takes consecutive monocular frames to generate depth and pose estimation. In 3D Detection module, the depth estimation is projected into 3D space to generate "Pseudo-LiDAR" point cloud, where LiDAR-based 3D detector can be leveraged on point cloud for vehicular 3D detection and localization. By end-to-end training of both modules, the proposed mapping and 3D detection method outperforms the state-of-the-art baseline by 10.0% and 13.2% in accuracy, respectively. While achieving better accuracy, our monocular multi-task SM3D is more than 2 times faster than pure stereo 3D detector, and 18.3% faster than using two modules separately.
MonoPLFlowNet: Permutohedral Lattice FlowNet for Real-Scale 3D Scene FlowEstimation with Monocular Images
Nov 24, 2021



Real-scale scene flow estimation has become increasingly important for 3D computer vision. Some works successfully estimate real-scale 3D scene flow with LiDAR. However, these ubiquitous and expensive sensors are still unlikely to be equipped widely for real application. Other works use monocular images to estimate scene flow, but their scene flow estimations are normalized with scale ambiguity, where additional depth or point cloud ground truth are required to recover the real scale. Even though they perform well in 2D, these works do not provide accurate and reliable 3D estimates. We present a deep learning architecture on permutohedral lattice - MonoPLFlowNet. Different from all previous works, our MonoPLFlowNet is the first work where only two consecutive monocular images are used as input, while both depth and 3D scene flow are estimated in real scale. Our real-scale scene flow estimation outperforms all state-of-the-art monocular-image based works recovered to real scale by ground truth, and is comparable to LiDAR approaches. As a by-product, our real-scale depth estimation also outperforms other state-of-the-art works.