 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoSelfRecon: Purely Self-Supervised Explicit Generalizable 3D Reconstruction of Indoor Scenes from Monocular RGB Views
Apr 10, 2024Current monocular 3D scene reconstruction (3DR) works are either fully-supervised, or not generalizable, or implicit in 3D representation. We propose a novel framework - MonoSelfRecon that for the first time achieves explicit 3D mesh reconstruction for generalizable indoor scenes with monocular RGB views by purely self-supervision on voxel-SDF (signed distance function). MonoSelfRecon follows an Autoencoder-based architecture, decodes voxel-SDF and a generalizable Neural Radiance Field (NeRF), which is used to guide voxel-SDF in self-supervision. We propose novel self-supervised losses, which not only support pure self-supervision, but can be used together with supervised signals to further boost supervised training. Our experiments show that "MonoSelfRecon" trained in pure self-supervision outperforms current best self-supervised indoor depth estimation models and is comparable to 3DR models trained in fully supervision with depth annotations. MonoSelfRecon is not restricted by specific model design, which can be used to any models with voxel-SDF for purely self-supervised manner.
LCDet: Low-Complexity Fully-Convolutional Neural Networks for Object Detection in Embedded Systems
May 16, 2017
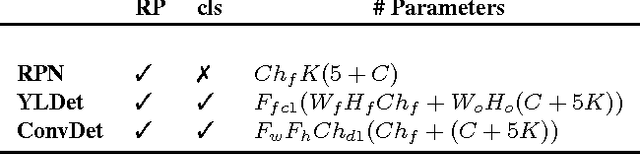
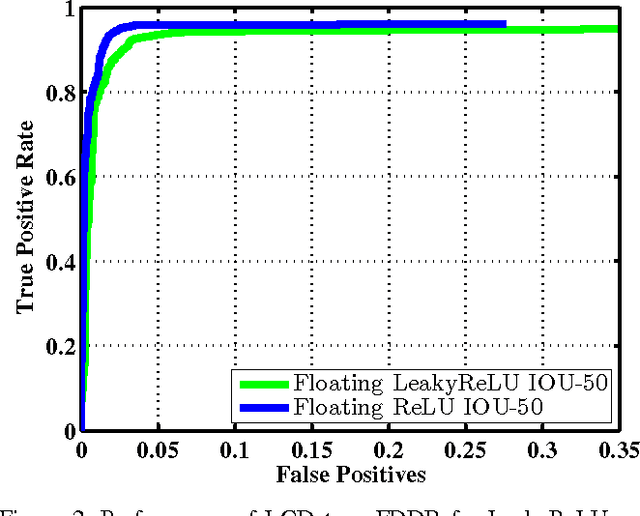
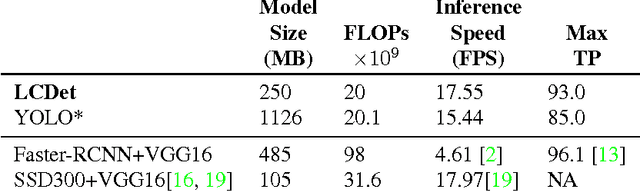
Deep convolutional Neural Networks (CNN) are the state-of-the-art performers for object detection task. It is well known that object detection requires more computation and memory than image classification. Thus the consolidation of a CNN-based object detection for an embedded system is more challenging. In this work, we propose LCDet, a fully-convolutional neural network for generic object detection that aims to work in embedded systems. We design and develop an end-to-end TensorFlow(TF)-based model. Additionally, we employ 8-bit quantization on the learned weights. We use face detection as a use case. Our TF-Slim based network can predict different faces of different shapes and sizes in a single forward pass. Our experimental results show that the proposed method achieves comparative accuracy comparing with state-of-the-art CNN-based face detection methods, while reducing the model size by 3x and memory-BW by ~4x comparing with one of the best real-time CNN-based object detector such as YOLO. TF 8-bit quantized model provides additional 4x memory reduction while keeping the accuracy as good as the floating point model. The proposed model thus becomes amenable for embedded implementations.