 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSM3D: Simultaneous Monocular Mapping and 3D Detection
Paper and Code
Nov 24, 2021
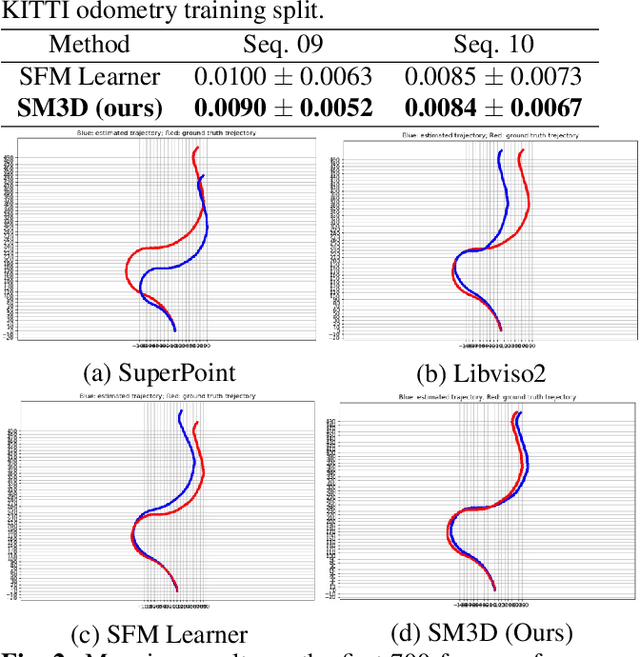

Mapping and 3D detection are two major issues in vision-based robotics, and self-driving. While previous works only focus on each task separately, we present an innovative and efficient multi-task deep learning framework (SM3D) for Simultaneous Mapping and 3D Detection by bridging the gap with robust depth estimation and "Pseudo-LiDAR" point cloud for the first time. The Mapping module takes consecutive monocular frames to generate depth and pose estimation. In 3D Detection module, the depth estimation is projected into 3D space to generate "Pseudo-LiDAR" point cloud, where LiDAR-based 3D detector can be leveraged on point cloud for vehicular 3D detection and localization. By end-to-end training of both modules, the proposed mapping and 3D detection method outperforms the state-of-the-art baseline by 10.0% and 13.2% in accuracy, respectively. While achieving better accuracy, our monocular multi-task SM3D is more than 2 times faster than pure stereo 3D detector, and 18.3% faster than using two modules separately.