 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Generation for Phrase Break Prediction with Large Language Model
Jul 24, 2025Current approaches to phrase break prediction address crucial prosodic aspects of text-to-speech systems but heavily rely on vast human annotations from audio or text, incurring significant manual effort and cost. Inherent variability in the speech domain, driven by phonetic factors, further complicates acquiring consistent, high-quality data. Recently, large language models (LLMs) have shown success in addressing data challenges in NLP by generating tailored synthetic data while reducing manual annotation needs. Motivated by this, we explore leveraging LLM to generate synthetic phrase break annotations, addressing the challenges of both manual annotation and speech-related tasks by comparing with traditional annotations and assessing effectiveness across multiple languages. Our findings suggest that LLM-based synthetic data generation effectively mitigates data challenges in phrase break prediction and highlights the potential of LLMs as a viable solution for the speech domain.
A Two-Step Approach for Data-Efficient French Pronunciation Learning
Oct 08, 2024

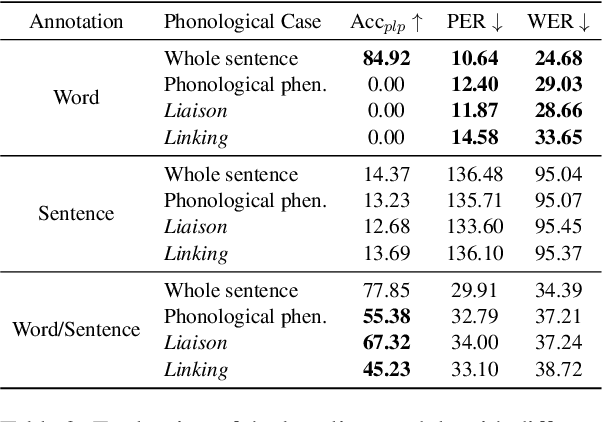

Recent studies have addressed intricate phonological phenomena in French, relying on either extensive linguistic knowledge or a significant amount of sentence-level pronunciation data. However, creating such resources is expensive and non-trivial. To this end, we propose a novel two-step approach that encompasses two pronunciation tasks: grapheme-to-phoneme and post-lexical processing. We then investigate the efficacy of the proposed approach with a notably limited amount of sentence-level pronunciation data. Our findings demonstrate that the proposed two-step approach effectively mitigates the lack of extensive labeled data, and serves as a feasible solution for addressing French phonological phenomena even under resource-constrained environments.
Cross-Lingual Transfer Learning for Phrase Break Prediction with Multilingual Language Model
Jun 05, 2023



Phrase break prediction is a crucial task for improving the prosody naturalness of a text-to-speech (TTS) system. However, most proposed phrase break prediction models are monolingual, trained exclusively on a large amount of labeled data. In this paper, we address this issue for low-resource languages with limited labeled data using cross-lingual transfer. We investigate the effectiveness of zero-shot and few-shot cross-lingual transfer for phrase break prediction using a pre-trained multilingual language model. We use manually collected datasets in four Indo-European languages: one high-resource language and three with limited resources. Our findings demonstrate that cross-lingual transfer learning can be a particularly effective approach, especially in the few-shot setting, for improving performance in low-resource languages. This suggests that cross-lingual transfer can be inexpensive and effective for developing TTS front-end in resource-poor languages.
Language Model-Based Emotion Prediction Methods for Emotional Speech Synthesis Systems
Jul 01, 2022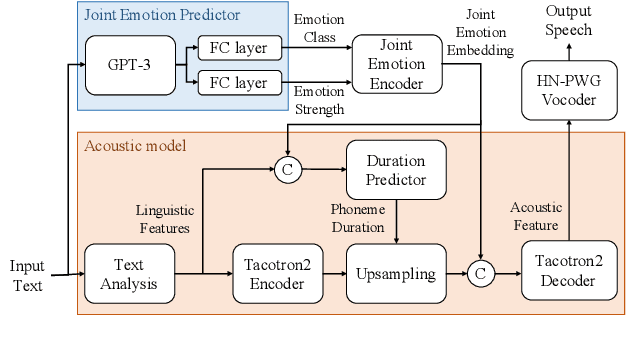

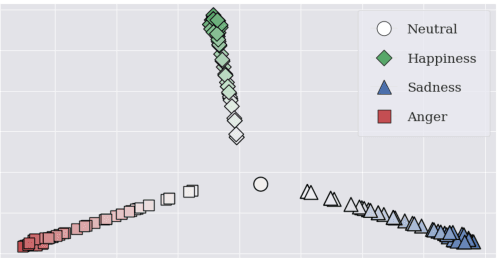

This paper proposes an effective emotional text-to-speech (TTS) system with a pre-trained language model (LM)-based emotion prediction method. Unlike conventional systems that require auxiliary inputs such as manually defined emotion classes, our system directly estimates emotion-related attributes from the input text. Specifically, we utilize generative pre-trained transformer (GPT)-3 to jointly predict both an emotion class and its strength in representing emotions coarse and fine properties, respectively. Then, these attributes are combined in the emotional embedding space and used as conditional features of the TTS model for generating output speech signals. Consequently, the proposed system can produce emotional speech only from text without any auxiliary inputs. Furthermore, because the GPT-3 enables to capture emotional context among the consecutive sentences, the proposed method can effectively handle the paragraph-level generation of emotional speech.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

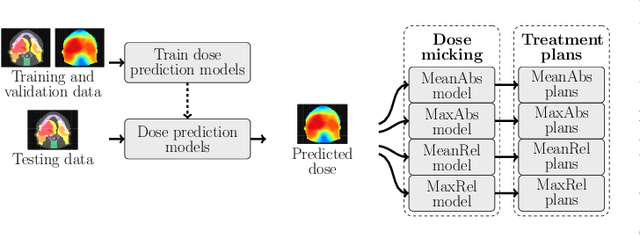
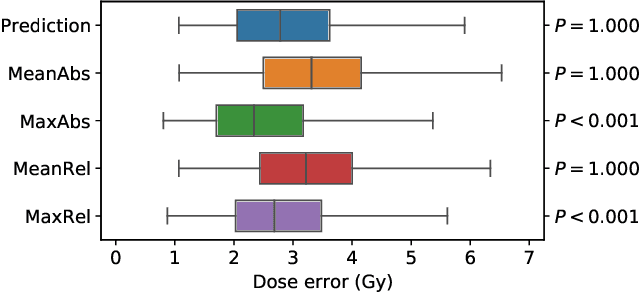
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
Deep-neural-network based sinogram synthesis for sparse-view CT image reconstruction
Mar 06, 2018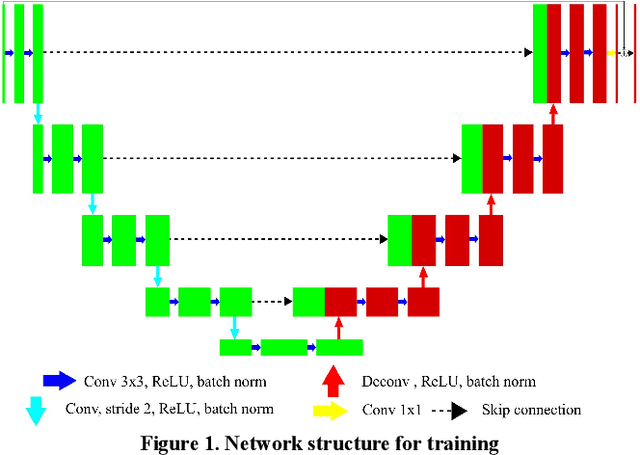
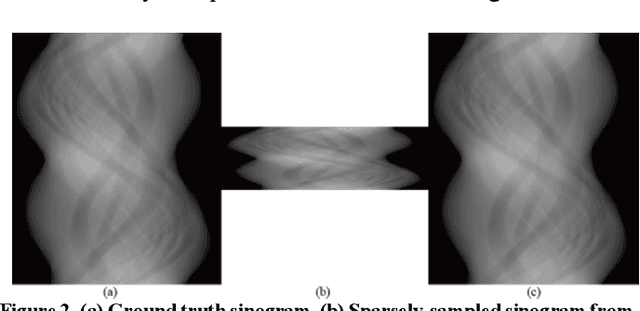

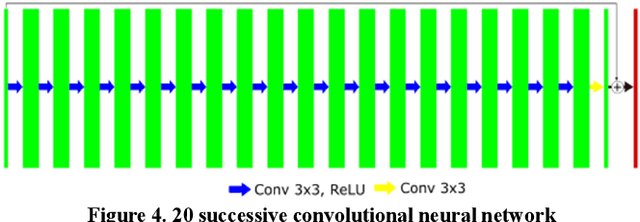
Recently, a number of approaches to low-dose computed tomography (CT) have been developed and deployed in commercialized CT scanners. Tube current reduction is perhaps the most actively explored technology with advanced image reconstruction algorithms. Sparse data sampling is another viable option to the low-dose CT, and sparse-view CT has been particularly of interest among the researchers in CT community. Since analytic image reconstruction algorithms would lead to severe image artifacts, various iterative algorithms have been developed for reconstructing images from sparsely view-sampled projection data. However, iterative algorithms take much longer computation time than the analytic algorithms, and images are usually prone to different types of image artifacts that heavily depend on the reconstruction parameters. Interpolation methods have also been utilized to fill the missing data in the sinogram of sparse-view CT thus providing synthetically full data for analytic image reconstruction. In this work, we introduce a deep-neural-network-enabled sinogram synthesis method for sparse-view CT, and show its outperformance to the existing interpolation methods and also to the iterative image reconstruction approach.