 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Self-Attention for Zero-Shot Multi-Speaker Text-to-Speech
Aug 28, 2023For personalized speech generation, a neural text-to-speech (TTS) model must be successfully implemented with limited data from a target speaker. To this end, the baseline TTS model needs to be amply generalized to out-of-domain data (i.e., target speaker's speech). However, approaches to address this out-of-domain generalization problem in TTS have yet to be thoroughly studied. In this work, we propose an effective pruning method for a transformer known as sparse attention, to improve the TTS model's generalization abilities. In particular, we prune off redundant connections from self-attention layers whose attention weights are below the threshold. To flexibly determine the pruning strength for searching optimal degree of generalization, we also propose a new differentiable pruning method that allows the model to automatically learn the thresholds. Evaluations on zero-shot multi-speaker TTS verify the effectiveness of our method in terms of voice quality and speaker similarity.
* INTERSPEECH 2023
Cross-Lingual Transfer Learning for Phrase Break Prediction with Multilingual Language Model
Jun 05, 2023



Phrase break prediction is a crucial task for improving the prosody naturalness of a text-to-speech (TTS) system. However, most proposed phrase break prediction models are monolingual, trained exclusively on a large amount of labeled data. In this paper, we address this issue for low-resource languages with limited labeled data using cross-lingual transfer. We investigate the effectiveness of zero-shot and few-shot cross-lingual transfer for phrase break prediction using a pre-trained multilingual language model. We use manually collected datasets in four Indo-European languages: one high-resource language and three with limited resources. Our findings demonstrate that cross-lingual transfer learning can be a particularly effective approach, especially in the few-shot setting, for improving performance in low-resource languages. This suggests that cross-lingual transfer can be inexpensive and effective for developing TTS front-end in resource-poor languages.
Language Model-Based Emotion Prediction Methods for Emotional Speech Synthesis Systems
Jul 01, 2022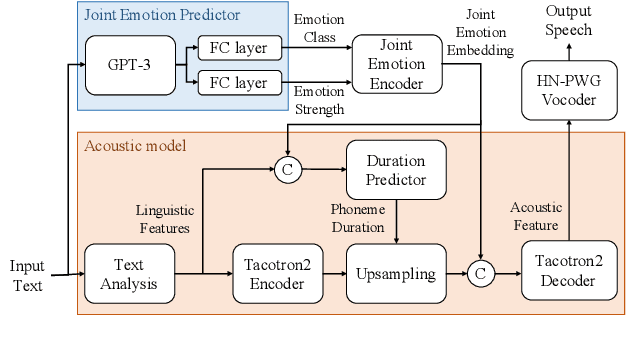

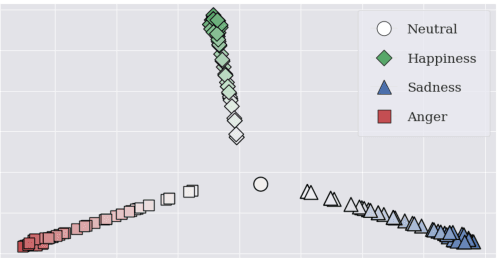

This paper proposes an effective emotional text-to-speech (TTS) system with a pre-trained language model (LM)-based emotion prediction method. Unlike conventional systems that require auxiliary inputs such as manually defined emotion classes, our system directly estimates emotion-related attributes from the input text. Specifically, we utilize generative pre-trained transformer (GPT)-3 to jointly predict both an emotion class and its strength in representing emotions coarse and fine properties, respectively. Then, these attributes are combined in the emotional embedding space and used as conditional features of the TTS model for generating output speech signals. Consequently, the proposed system can produce emotional speech only from text without any auxiliary inputs. Furthermore, because the GPT-3 enables to capture emotional context among the consecutive sentences, the proposed method can effectively handle the paragraph-level generation of emotional speech.
TTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
Jun 30, 2022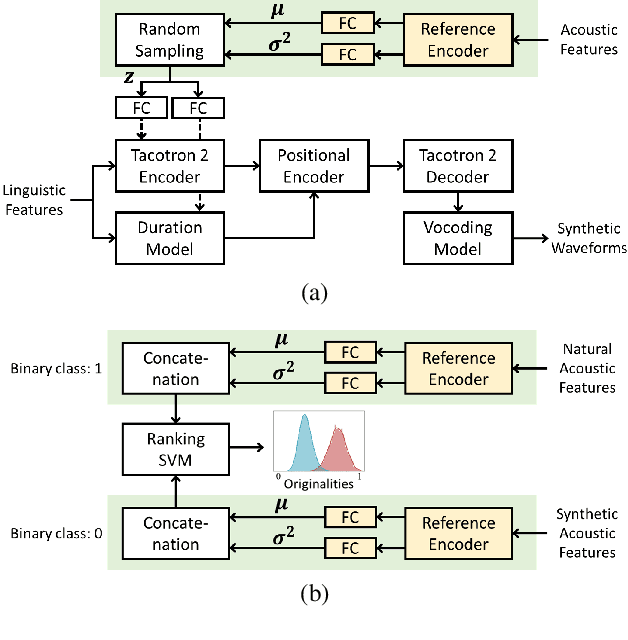

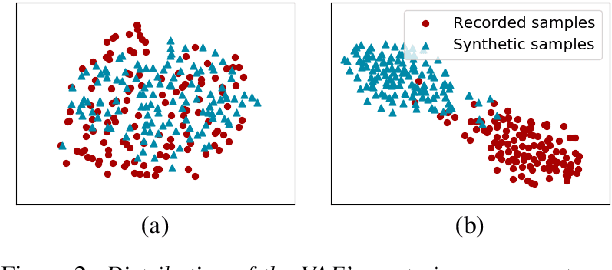
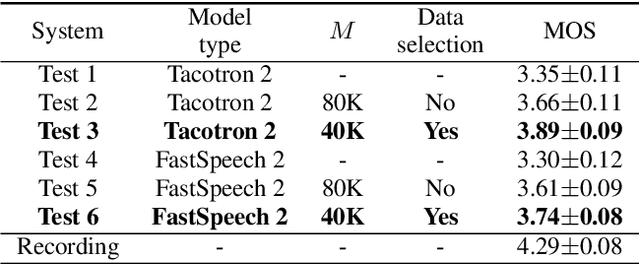
Recent advances in synthetic speech quality have enabled us to train text-to-speech (TTS) systems by using synthetic corpora. However, merely increasing the amount of synthetic data is not always advantageous for improving training efficiency. Our aim in this study is to selectively choose synthetic data that are beneficial to the training process. In the proposed method, we first adopt a variational autoencoder whose posterior distribution is utilized to extract latent features representing acoustic similarity between the recorded and synthetic corpora. By using those learned features, we then train a ranking support vector machine (RankSVM) that is well known for effectively ranking relative attributes among binary classes. By setting the recorded and synthetic ones as two opposite classes, RankSVM is used to determine how the synthesized speech is acoustically similar to the recorded data. Then, synthetic TTS data, whose distribution is close to the recorded data, are selected from large-scale synthetic corpora. By using these data for retraining the TTS model, the synthetic quality can be significantly improved. Objective and subjective evaluation results show the superiority of the proposed method over the conventional methods.
Cross-Speaker Emotion Transfer for Low-Resource Text-to-Speech Using Non-Parallel Voice Conversion with Pitch-Shift Data Augmentation
Apr 21, 2022
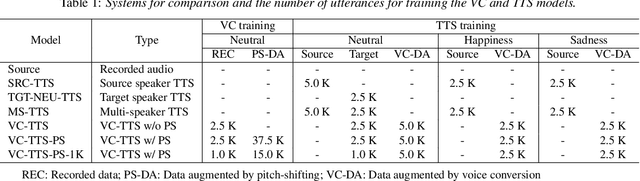
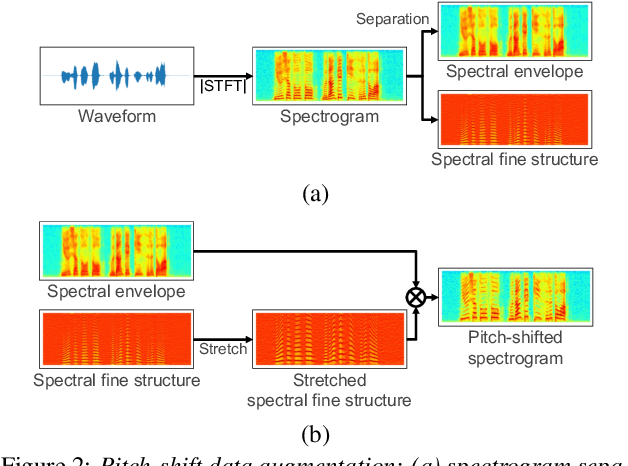
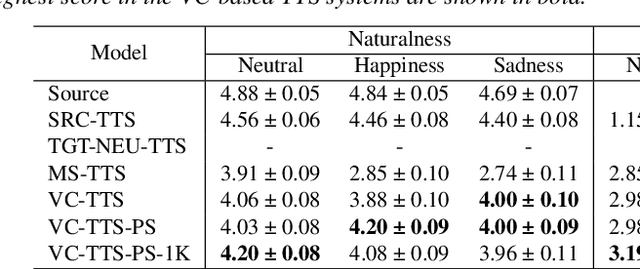
Data augmentation via voice conversion (VC) has been successfully applied to low-resource expressive text-to-speech (TTS) when only neutral data for the target speaker are available. Although the quality of VC is crucial for this approach, it is challenging to learn a stable VC model because the amount of data is limited in low-resource scenarios, and highly expressive speech has large acoustic variety. To address this issue, we propose a novel data augmentation method that combines pitch-shifting and VC techniques. Because pitch-shift data augmentation enables the coverage of a variety of pitch dynamics, it greatly stabilizes training for both VC and TTS models, even when only 1,000 utterances of the target speaker's neutral data are available. Subjective test results showed that a FastSpeech 2-based emotional TTS system with the proposed method improved naturalness and emotional similarity compared with conventional methods.
Audio Dequantization for High Fidelity Audio Generation in Flow-based Neural Vocoder
Aug 16, 2020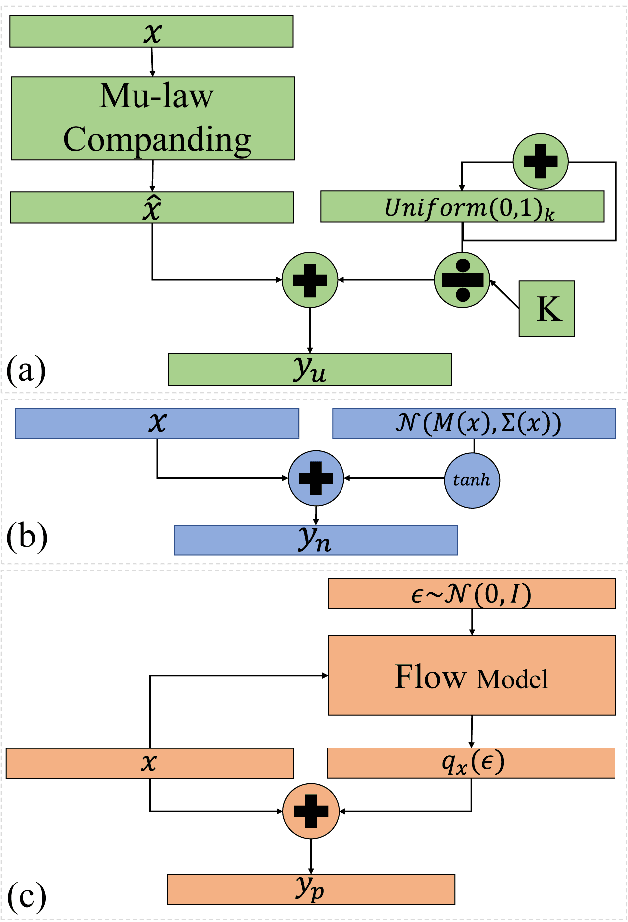
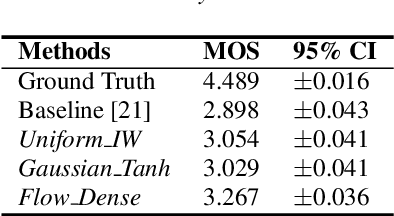


In recent works, a flow-based neural vocoder has shown significant improvement in real-time speech generation task. The sequence of invertible flow operations allows the model to convert samples from simple distribution to audio samples. However, training a continuous density model on discrete audio data can degrade model performance due to the topological difference between latent and actual distribution. To resolve this problem, we propose audio dequantization methods in flow-based neural vocoder for high fidelity audio generation. Data dequantization is a well-known method in image generation but has not yet been studied in the audio domain. For this reason, we implement various audio dequantization methods in flow-based neural vocoder and investigate the effect on the generated audio. We conduct various objective performance assessments and subjective evaluation to show that audio dequantization can improve audio generation quality. From our experiments, using audio dequantization produces waveform audio with better harmonic structure and fewer digital artifacts.