 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Dequantization for High Fidelity Audio Generation in Flow-based Neural Vocoder
Aug 16, 2020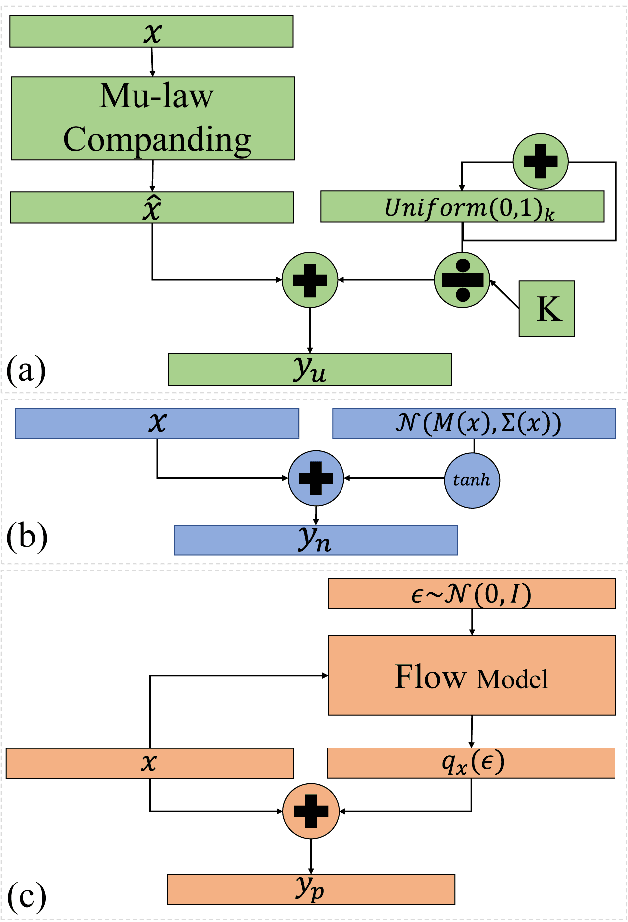
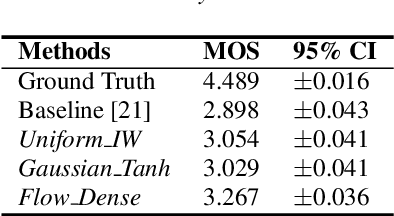


In recent works, a flow-based neural vocoder has shown significant improvement in real-time speech generation task. The sequence of invertible flow operations allows the model to convert samples from simple distribution to audio samples. However, training a continuous density model on discrete audio data can degrade model performance due to the topological difference between latent and actual distribution. To resolve this problem, we propose audio dequantization methods in flow-based neural vocoder for high fidelity audio generation. Data dequantization is a well-known method in image generation but has not yet been studied in the audio domain. For this reason, we implement various audio dequantization methods in flow-based neural vocoder and investigate the effect on the generated audio. We conduct various objective performance assessments and subjective evaluation to show that audio dequantization can improve audio generation quality. From our experiments, using audio dequantization produces waveform audio with better harmonic structure and fewer digital artifacts.