 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLASH: Self-Supervised Speech Pitch Estimation Leveraging DSP-derived Absolute Pitch
Jul 23, 2025We present SLASH, a pitch estimation method of speech signals based on self-supervised learning (SSL). To enhance the performance of conventional SSL-based approaches that primarily depend on the relative pitch difference derived from pitch shifting, our method incorporates absolute pitch values by 1) introducing a prior pitch distribution derived from digital signal processing (DSP), and 2) optimizing absolute pitch through gradient descent with a loss between the target and differentiable DSP-derived spectrograms. To stabilize the optimization, a novel spectrogram generation method is used that skips complicated waveform generation. In addition, the aperiodic components in speech are accurately predicted through differentiable DSP, enhancing the method's applicability to speech signal processing. Experimental results showed that the proposed method outperformed both baseline DSP and SSL-based pitch estimation methods, attributed to the effective integration of SSL and DSP.
Song Data Cleansing for End-to-End Neural Singer Diarization Using Neural Analysis and Synthesis Framework
Jun 24, 2024



We propose a data cleansing method that utilizes a neural analysis and synthesis (NANSY++) framework to train an end-to-end neural diarization model (EEND) for singer diarization. Our proposed model converts song data with choral singing which is commonly contained in popular music and unsuitable for generating a simulated dataset to the solo singing data. This cleansing is based on NANSY++, which is a framework trained to reconstruct an input non-overlapped audio signal. We exploit the pre-trained NANSY++ to convert choral singing into clean, non-overlapped audio. This cleansing process mitigates the mislabeling of choral singing to solo singing and helps the effective training of EEND models even when the majority of available song data contains choral singing sections. We experimentally evaluated the EEND model trained with a dataset using our proposed method using annotated popular duet songs. As a result, our proposed method improved 14.8 points in diarization error rate.
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-end Emotional Speech Synthesis
Oct 28, 2022



Several fully end-to-end text-to-speech (TTS) models have been proposed that have shown better performance compared to cascade models (i.e., training acoustic and vocoder models separately). However, they often generate unstable pitch contour with audible artifacts when the dataset contains emotional attributes, i.e., large diversity of pronunciation and prosody. To address this problem, we propose Period VITS, a novel end-to-end TTS model that incorporates an explicit periodicity generator. In the proposed method, we introduce a frame pitch predictor that predicts prosodic features, such as pitch and voicing flags, from the input text. From these features, the proposed periodicity generator produces a sample-level sinusoidal source that enables the waveform decoder to accurately reproduce the pitch. Finally, the entire model is jointly optimized in an end-to-end manner with variational inference and adversarial objectives. As a result, the decoder becomes capable of generating more stable, expressive, and natural output waveforms. The experimental results showed that the proposed model significantly outperforms baseline models in terms of naturalness, with improved pitch stability in the generated samples.
Cross-Speaker Emotion Transfer for Low-Resource Text-to-Speech Using Non-Parallel Voice Conversion with Pitch-Shift Data Augmentation
Apr 21, 2022
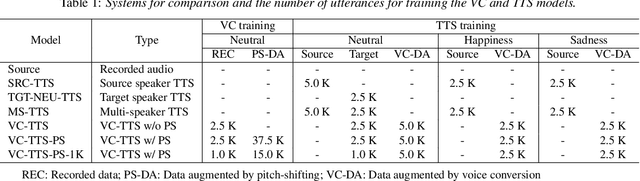
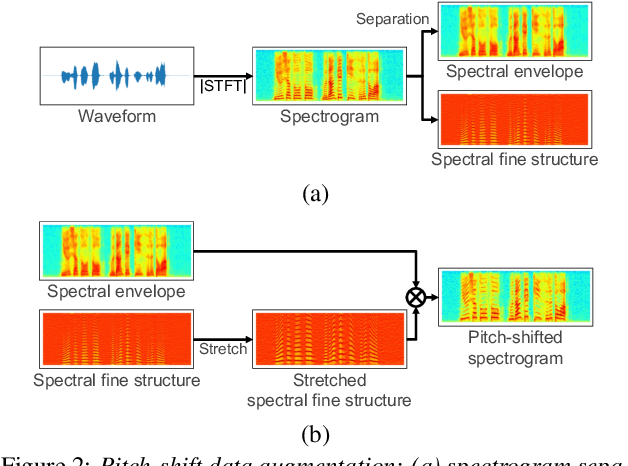
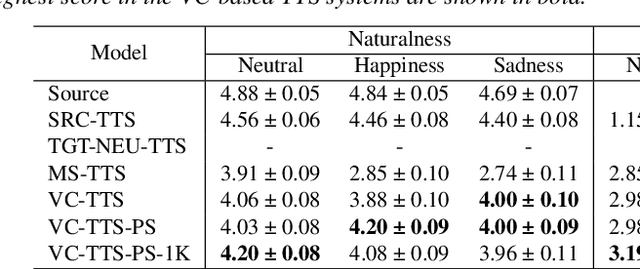
Data augmentation via voice conversion (VC) has been successfully applied to low-resource expressive text-to-speech (TTS) when only neutral data for the target speaker are available. Although the quality of VC is crucial for this approach, it is challenging to learn a stable VC model because the amount of data is limited in low-resource scenarios, and highly expressive speech has large acoustic variety. To address this issue, we propose a novel data augmentation method that combines pitch-shifting and VC techniques. Because pitch-shift data augmentation enables the coverage of a variety of pitch dynamics, it greatly stabilizes training for both VC and TTS models, even when only 1,000 utterances of the target speaker's neutral data are available. Subjective test results showed that a FastSpeech 2-based emotional TTS system with the proposed method improved naturalness and emotional similarity compared with conventional methods.