 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepressLLM: Interpretable domain-adapted language model for depression detection from real-world narratives
Aug 12, 2025Advances in large language models (LLMs) have enabled a wide range of applications. However, depression prediction is hindered by the lack of large-scale, high-quality, and rigorously annotated datasets. This study introduces DepressLLM, trained and evaluated on a novel corpus of 3,699 autobiographical narratives reflecting both happiness and distress. DepressLLM provides interpretable depression predictions and, via its Score-guided Token Probability Summation (SToPS) module, delivers both improved classification performance and reliable confidence estimates, achieving an AUC of 0.789, which rises to 0.904 on samples with confidence $\geq$ 0.95. To validate its robustness to heterogeneous data, we evaluated DepressLLM on in-house datasets, including an Ecological Momentary Assessment (EMA) corpus of daily stress and mood recordings, and on public clinical interview data. Finally, a psychiatric review of high-confidence misclassifications highlighted key model and data limitations that suggest directions for future refinements. These findings demonstrate that interpretable AI can enable earlier diagnosis of depression and underscore the promise of medical AI in psychiatry.
A Two-Step Approach for Data-Efficient French Pronunciation Learning
Oct 08, 2024

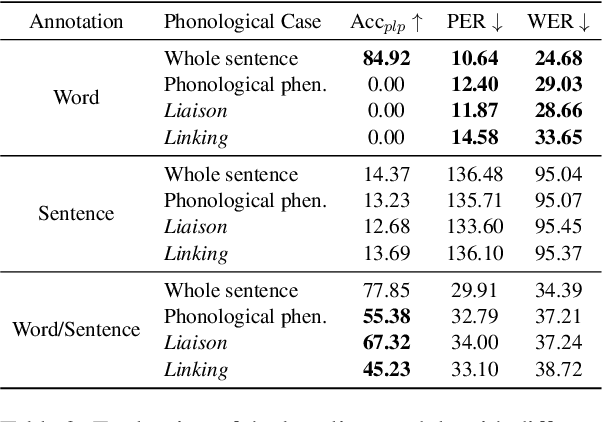

Recent studies have addressed intricate phonological phenomena in French, relying on either extensive linguistic knowledge or a significant amount of sentence-level pronunciation data. However, creating such resources is expensive and non-trivial. To this end, we propose a novel two-step approach that encompasses two pronunciation tasks: grapheme-to-phoneme and post-lexical processing. We then investigate the efficacy of the proposed approach with a notably limited amount of sentence-level pronunciation data. Our findings demonstrate that the proposed two-step approach effectively mitigates the lack of extensive labeled data, and serves as a feasible solution for addressing French phonological phenomena even under resource-constrained environments.
Cross-Lingual Transfer Learning for Phrase Break Prediction with Multilingual Language Model
Jun 05, 2023



Phrase break prediction is a crucial task for improving the prosody naturalness of a text-to-speech (TTS) system. However, most proposed phrase break prediction models are monolingual, trained exclusively on a large amount of labeled data. In this paper, we address this issue for low-resource languages with limited labeled data using cross-lingual transfer. We investigate the effectiveness of zero-shot and few-shot cross-lingual transfer for phrase break prediction using a pre-trained multilingual language model. We use manually collected datasets in four Indo-European languages: one high-resource language and three with limited resources. Our findings demonstrate that cross-lingual transfer learning can be a particularly effective approach, especially in the few-shot setting, for improving performance in low-resource languages. This suggests that cross-lingual transfer can be inexpensive and effective for developing TTS front-end in resource-poor languages.
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-end Emotional Speech Synthesis
Oct 28, 2022



Several fully end-to-end text-to-speech (TTS) models have been proposed that have shown better performance compared to cascade models (i.e., training acoustic and vocoder models separately). However, they often generate unstable pitch contour with audible artifacts when the dataset contains emotional attributes, i.e., large diversity of pronunciation and prosody. To address this problem, we propose Period VITS, a novel end-to-end TTS model that incorporates an explicit periodicity generator. In the proposed method, we introduce a frame pitch predictor that predicts prosodic features, such as pitch and voicing flags, from the input text. From these features, the proposed periodicity generator produces a sample-level sinusoidal source that enables the waveform decoder to accurately reproduce the pitch. Finally, the entire model is jointly optimized in an end-to-end manner with variational inference and adversarial objectives. As a result, the decoder becomes capable of generating more stable, expressive, and natural output waveforms. The experimental results showed that the proposed model significantly outperforms baseline models in terms of naturalness, with improved pitch stability in the generated samples.
Language Model-Based Emotion Prediction Methods for Emotional Speech Synthesis Systems
Jul 01, 2022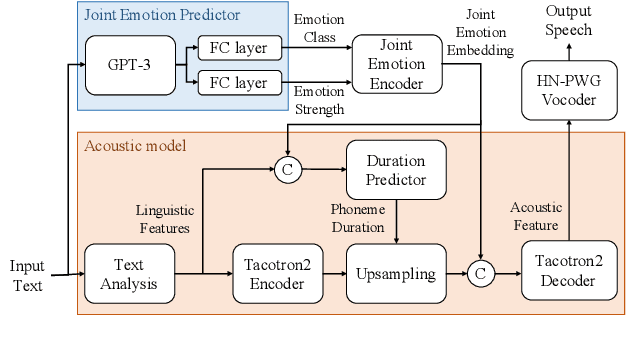

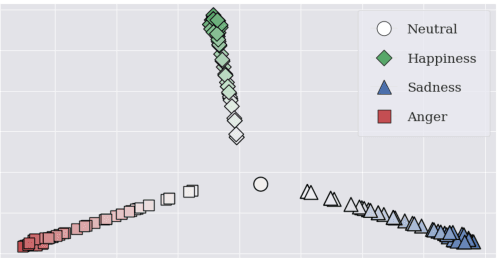

This paper proposes an effective emotional text-to-speech (TTS) system with a pre-trained language model (LM)-based emotion prediction method. Unlike conventional systems that require auxiliary inputs such as manually defined emotion classes, our system directly estimates emotion-related attributes from the input text. Specifically, we utilize generative pre-trained transformer (GPT)-3 to jointly predict both an emotion class and its strength in representing emotions coarse and fine properties, respectively. Then, these attributes are combined in the emotional embedding space and used as conditional features of the TTS model for generating output speech signals. Consequently, the proposed system can produce emotional speech only from text without any auxiliary inputs. Furthermore, because the GPT-3 enables to capture emotional context among the consecutive sentences, the proposed method can effectively handle the paragraph-level generation of emotional speech.
TTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
Jun 30, 2022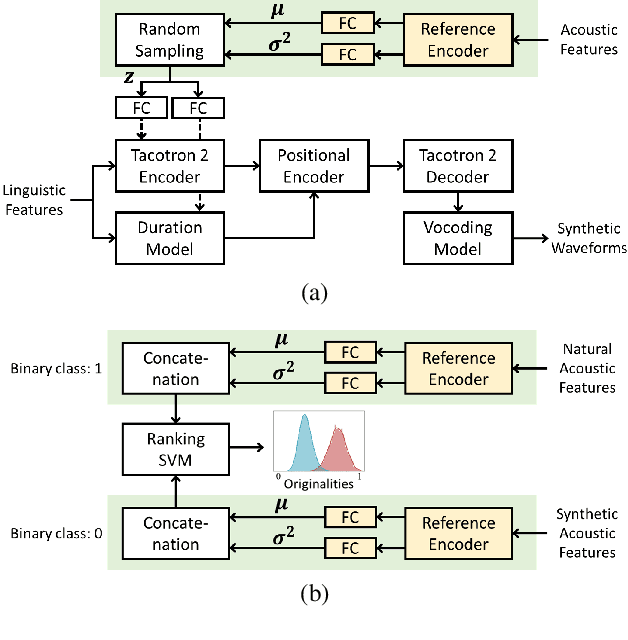

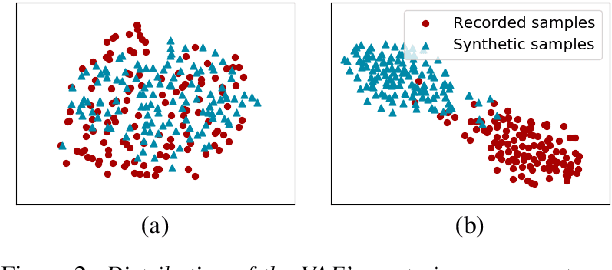
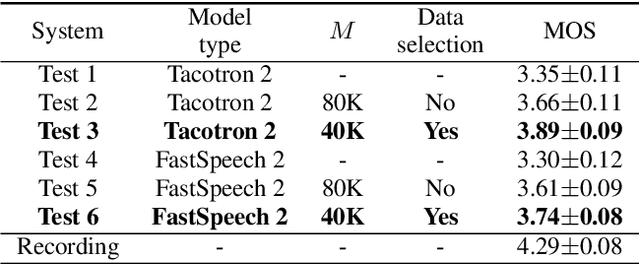
Recent advances in synthetic speech quality have enabled us to train text-to-speech (TTS) systems by using synthetic corpora. However, merely increasing the amount of synthetic data is not always advantageous for improving training efficiency. Our aim in this study is to selectively choose synthetic data that are beneficial to the training process. In the proposed method, we first adopt a variational autoencoder whose posterior distribution is utilized to extract latent features representing acoustic similarity between the recorded and synthetic corpora. By using those learned features, we then train a ranking support vector machine (RankSVM) that is well known for effectively ranking relative attributes among binary classes. By setting the recorded and synthetic ones as two opposite classes, RankSVM is used to determine how the synthesized speech is acoustically similar to the recorded data. Then, synthetic TTS data, whose distribution is close to the recorded data, are selected from large-scale synthetic corpora. By using these data for retraining the TTS model, the synthetic quality can be significantly improved. Objective and subjective evaluation results show the superiority of the proposed method over the conventional methods.
Cross-Speaker Emotion Transfer for Low-Resource Text-to-Speech Using Non-Parallel Voice Conversion with Pitch-Shift Data Augmentation
Apr 21, 2022
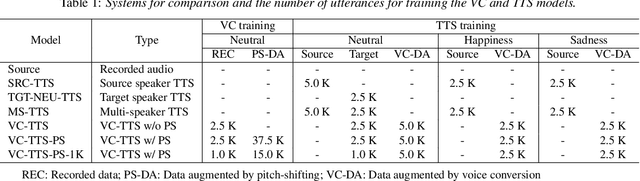
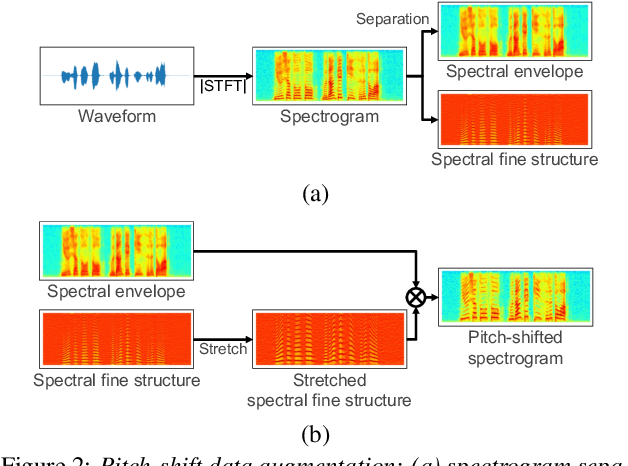
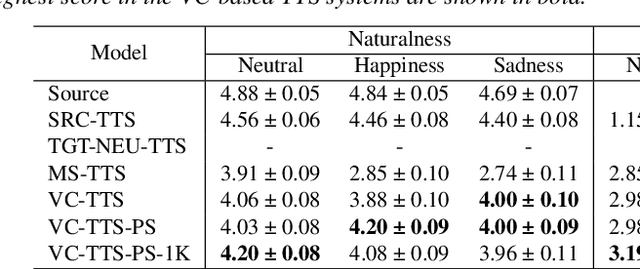
Data augmentation via voice conversion (VC) has been successfully applied to low-resource expressive text-to-speech (TTS) when only neutral data for the target speaker are available. Although the quality of VC is crucial for this approach, it is challenging to learn a stable VC model because the amount of data is limited in low-resource scenarios, and highly expressive speech has large acoustic variety. To address this issue, we propose a novel data augmentation method that combines pitch-shifting and VC techniques. Because pitch-shift data augmentation enables the coverage of a variety of pitch dynamics, it greatly stabilizes training for both VC and TTS models, even when only 1,000 utterances of the target speaker's neutral data are available. Subjective test results showed that a FastSpeech 2-based emotional TTS system with the proposed method improved naturalness and emotional similarity compared with conventional methods.
Improved parallel WaveGAN vocoder with perceptually weighted spectrogram loss
Jan 19, 2021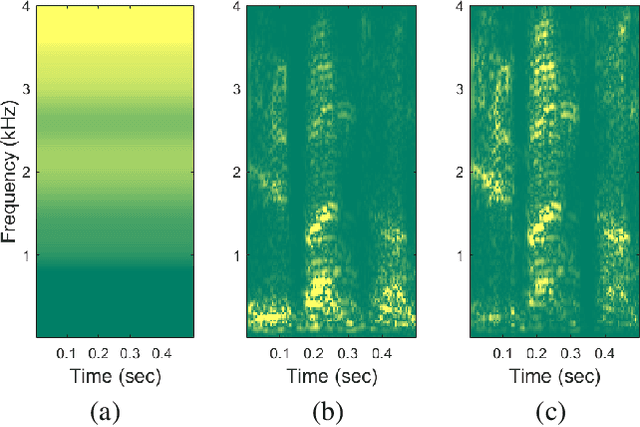

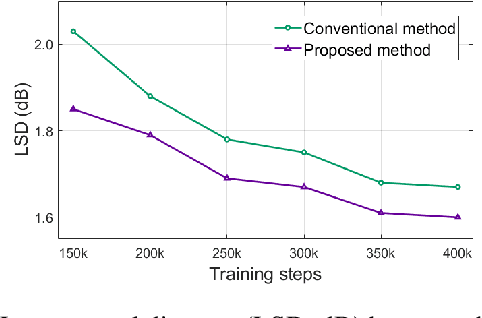

This paper proposes a spectral-domain perceptual weighting technique for Parallel WaveGAN-based text-to-speech (TTS) systems. The recently proposed Parallel WaveGAN vocoder successfully generates waveform sequences using a fast non-autoregressive WaveNet model. By employing multi-resolution short-time Fourier transform (MR-STFT) criteria with a generative adversarial network, the light-weight convolutional networks can be effectively trained without any distillation process. To further improve the vocoding performance, we propose the application of frequency-dependent weighting to the MR-STFT loss function. The proposed method penalizes perceptually-sensitive errors in the frequency domain; thus, the model is optimized toward reducing auditory noise in the synthesized speech. Subjective listening test results demonstrate that our proposed method achieves 4.21 and 4.26 TTS mean opinion scores for female and male Korean speakers, respectively.
Parallel waveform synthesis based on generative adversarial networks with voicing-aware conditional discriminators
Oct 27, 2020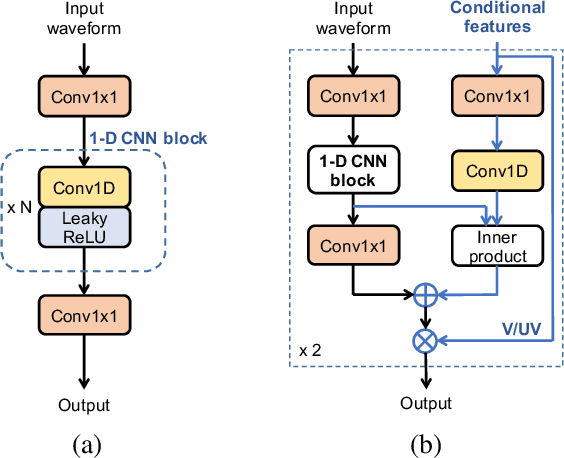

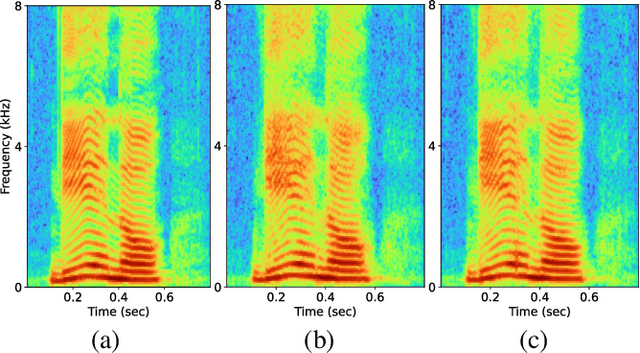

This paper proposes voicing-aware conditional discriminators for Parallel WaveGAN-based waveform synthesis systems. In this framework, we adopt a projection-based conditioning method that can significantly improve the discriminator's performance. Furthermore, the conventional discriminator is separated into two waveform discriminators for modeling voiced and unvoiced speech. As each discriminator learns the distinctive characteristics of the harmonic and noise components, respectively, the adversarial training process becomes more efficient, allowing the generator to produce more realistic speech waveforms. Subjective test results demonstrate the superiority of the proposed method over the conventional Parallel WaveGAN and WaveNet systems. In particular, our speaker-independently trained model within a FastSpeech 2 based text-to-speech framework achieves the mean opinion scores of 4.20, 4.18, 4.21, and 4.31 for four Japanese speakers, respectively.
Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram
Oct 25, 2019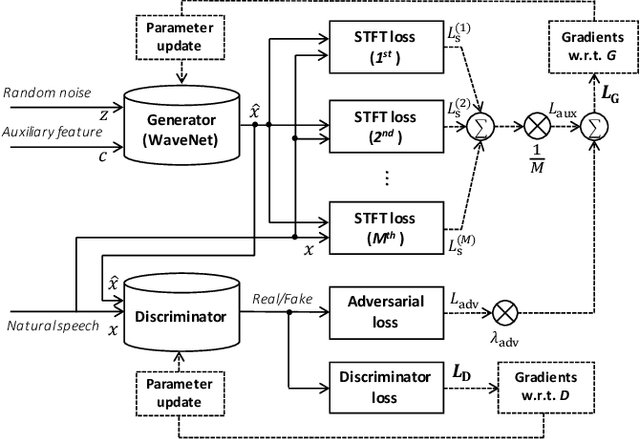



We propose Parallel WaveGAN, a distillation-free, fast, and small-footprint waveform generation method using a generative adversarial network. In the proposed method, a non-autoregressive WaveNet is trained by jointly optimizing multi-resolution spectrogram and adversarial loss functions, which can effectively capture the time-frequency distribution of the realistic speech waveform. As our method does not require density distillation used in the conventional teacher-student framework, the entire model can be easily trained even with a small number of parameters. In particular, the proposed Parallel WaveGAN has only 1.44 M parameters and can generate 24 kHz speech waveform 28.68 times faster than real-time on a single GPU environment. Perceptual listening test results verify that our proposed method achieves 4.16 mean opinion score within a Transformer-based text-to-speech framework, which is comparative to the best distillation-based Parallel WaveNet system.