 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
Jun 30, 2022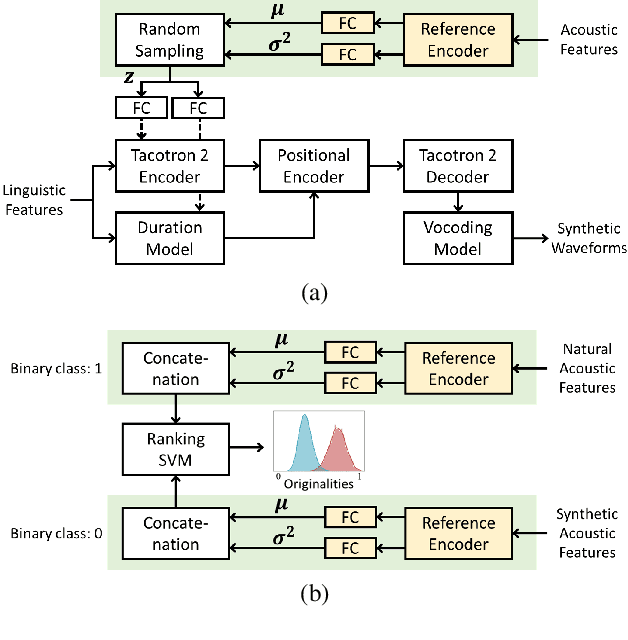

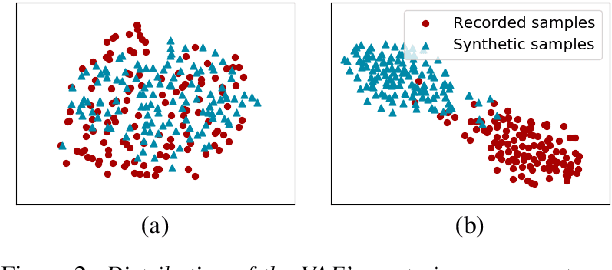
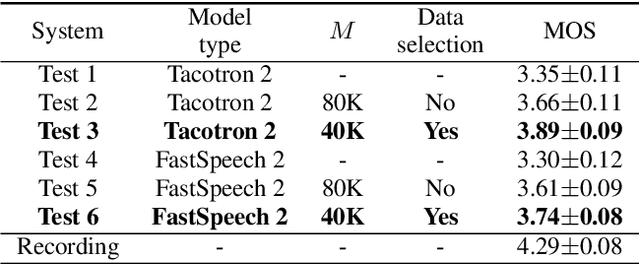
Recent advances in synthetic speech quality have enabled us to train text-to-speech (TTS) systems by using synthetic corpora. However, merely increasing the amount of synthetic data is not always advantageous for improving training efficiency. Our aim in this study is to selectively choose synthetic data that are beneficial to the training process. In the proposed method, we first adopt a variational autoencoder whose posterior distribution is utilized to extract latent features representing acoustic similarity between the recorded and synthetic corpora. By using those learned features, we then train a ranking support vector machine (RankSVM) that is well known for effectively ranking relative attributes among binary classes. By setting the recorded and synthetic ones as two opposite classes, RankSVM is used to determine how the synthesized speech is acoustically similar to the recorded data. Then, synthetic TTS data, whose distribution is close to the recorded data, are selected from large-scale synthetic corpora. By using these data for retraining the TTS model, the synthetic quality can be significantly improved. Objective and subjective evaluation results show the superiority of the proposed method over the conventional methods.
Improved parallel WaveGAN vocoder with perceptually weighted spectrogram loss
Jan 19, 2021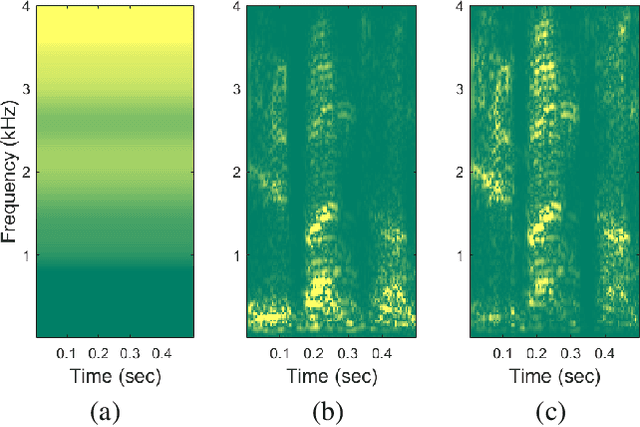

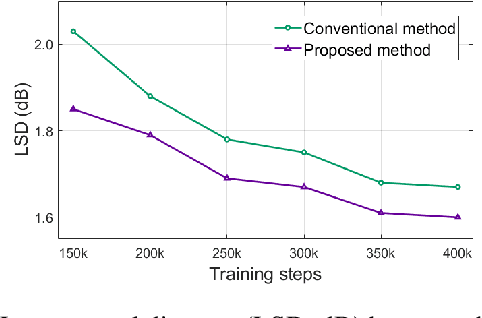

This paper proposes a spectral-domain perceptual weighting technique for Parallel WaveGAN-based text-to-speech (TTS) systems. The recently proposed Parallel WaveGAN vocoder successfully generates waveform sequences using a fast non-autoregressive WaveNet model. By employing multi-resolution short-time Fourier transform (MR-STFT) criteria with a generative adversarial network, the light-weight convolutional networks can be effectively trained without any distillation process. To further improve the vocoding performance, we propose the application of frequency-dependent weighting to the MR-STFT loss function. The proposed method penalizes perceptually-sensitive errors in the frequency domain; thus, the model is optimized toward reducing auditory noise in the synthesized speech. Subjective listening test results demonstrate that our proposed method achieves 4.21 and 4.26 TTS mean opinion scores for female and male Korean speakers, respectively.