 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrence-Free Survival Prediction for Anal Squamous Cell Carcinoma Chemoradiotherapy using Planning CT-based Radiomics Model
Sep 05, 2023



Objectives: Approximately 30% of non-metastatic anal squamous cell carcinoma (ASCC) patients will experience recurrence after chemoradiotherapy (CRT), and currently available clinical variables are poor predictors of treatment response. We aimed to develop a model leveraging information extracted from radiation pretreatment planning CT to predict recurrence-free survival (RFS) in ASCC patients after CRT. Methods: Radiomics features were extracted from planning CT images of 96 ASCC patients. Following pre-feature selection, the optimal feature set was selected via step-forward feature selection with a multivariate Cox proportional hazard model. The RFS prediction was generated from a radiomics-clinical combined model based on an optimal feature set with five repeats of five-fold cross validation. The risk stratification ability of the proposed model was evaluated with Kaplan-Meier analysis. Results: Shape- and texture-based radiomics features significantly predicted RFS. Compared to a clinical-only model, radiomics-clinical combined model achieves better performance in the testing cohort with higher C-index (0.80 vs 0.73) and AUC (0.84 vs 0.79 for 1-year RFS, 0.84 vs 0.78 for 2-year RFS, and 0.86 vs 0.83 for 3-year RFS), leading to distinctive high- and low-risk of recurrence groups (p<0.001). Conclusions: A treatment planning CT based radiomics and clinical combined model had improved prognostic performance in predicting RFS for ASCC patients treated with CRT as compared to a model using clinical features only.
Joint localization and classification of breast tumors on ultrasound images using a novel auxiliary attention-based framework
Oct 11, 2022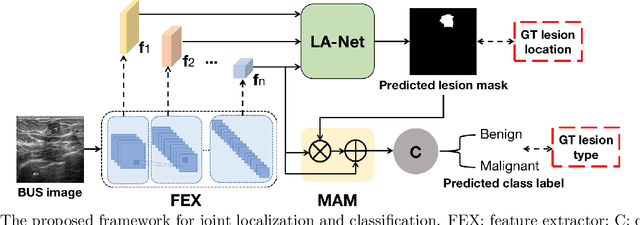
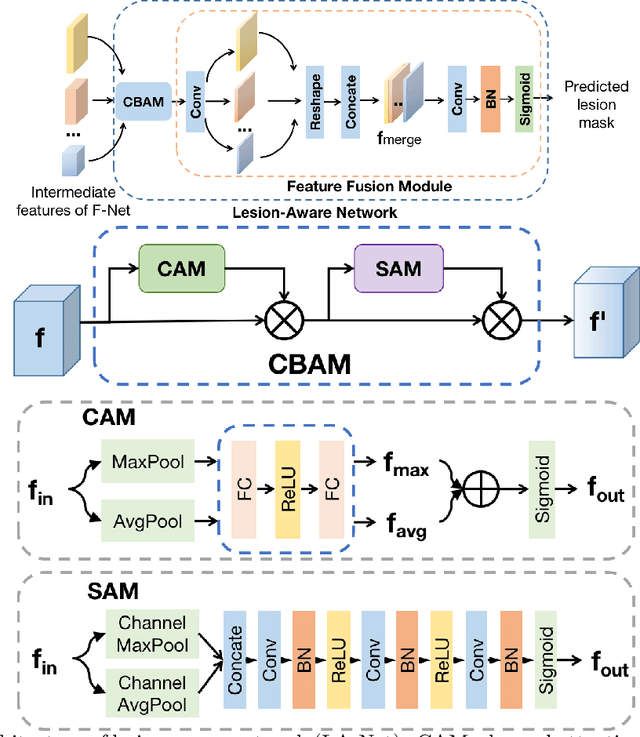
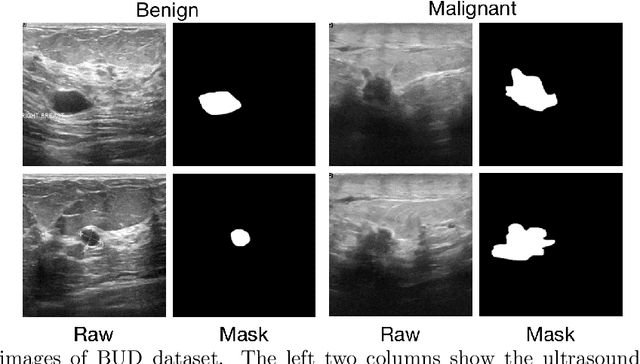
Automatic breast lesion detection and classification is an important task in computer-aided diagnosis, in which breast ultrasound (BUS) imaging is a common and frequently used screening tool. Recently, a number of deep learning-based methods have been proposed for joint localization and classification of breast lesions using BUS images. In these methods, features extracted by a shared network trunk are appended by two independent network branches to achieve classification and localization. Improper information sharing might cause conflicts in feature optimization in the two branches and leads to performance degradation. Also, these methods generally require large amounts of pixel-level annotated data for model training. To overcome these limitations, we proposed a novel joint localization and classification model based on the attention mechanism and disentangled semi-supervised learning strategy. The model used in this study is composed of a classification network and an auxiliary lesion-aware network. By use of the attention mechanism, the auxiliary lesion-aware network can optimize multi-scale intermediate feature maps and extract rich semantic information to improve classification and localization performance. The disentangled semi-supervised learning strategy only requires incomplete training datasets for model training. The proposed modularized framework allows flexible network replacement to be generalized for various applications. Experimental results on two different breast ultrasound image datasets demonstrate the effectiveness of the proposed method. The impacts of various network factors on model performance are also investigated to gain deep insights into the designed framework.
ChebNet: Efficient and Stable Constructions of Deep Neural Networks with Rectified Power Units using Chebyshev Approximations
Dec 20, 2019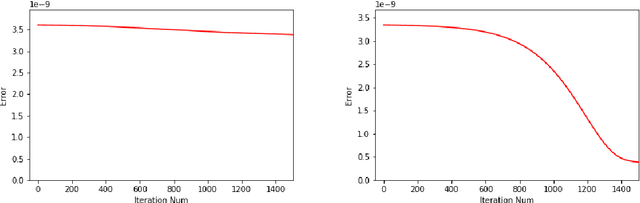

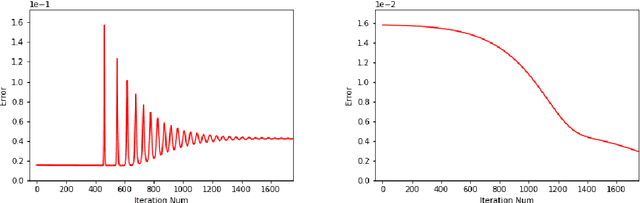
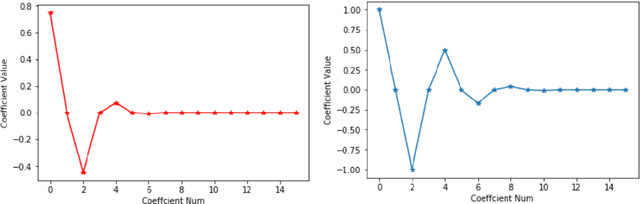
In a recent paper [B. Li, S. Tang and H. Yu, arXiv:1903.05858], it was shown that deep neural networks built with rectified power units (RePU) can give better approximation for sufficient smooth functions than those with rectified linear units, by converting polynomial approximation given in power series into deep neural networks with optimal complexity and no approximation error. However, in practice, power series are not easy to compute. In this paper, we propose a new and more stable way to construct deep RePU neural networks based on Chebyshev polynomial approximations. By using a hierarchical structure of Chebyshev polynomial approximation in frequency domain, we build efficient and stable deep neural network constructions. In theory, ChebNets and the deep RePU nets based on Power series have the same upper error bounds for general function approximations. But numerically, ChebNets are much more stable. Numerical results show that the constructed ChebNets can be further trained and obtain much better results than those obtained by training deep RePU nets constructed basing on power series.
PowerNet: Efficient Representations of Polynomials and Smooth Functions by Deep Neural Networks with Rectified Power Units
Sep 09, 2019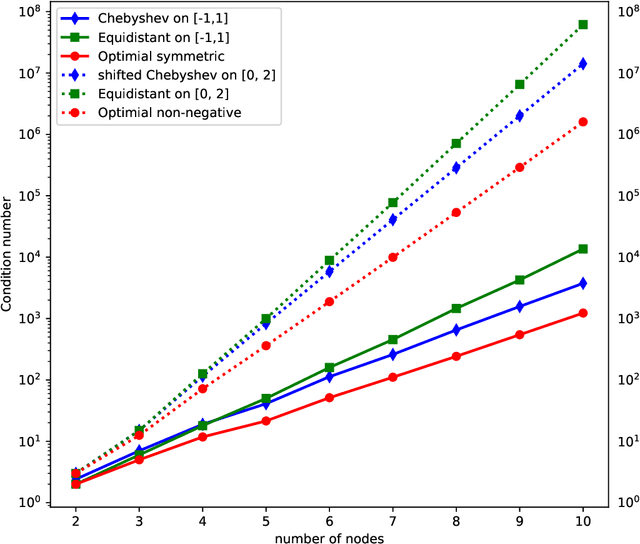
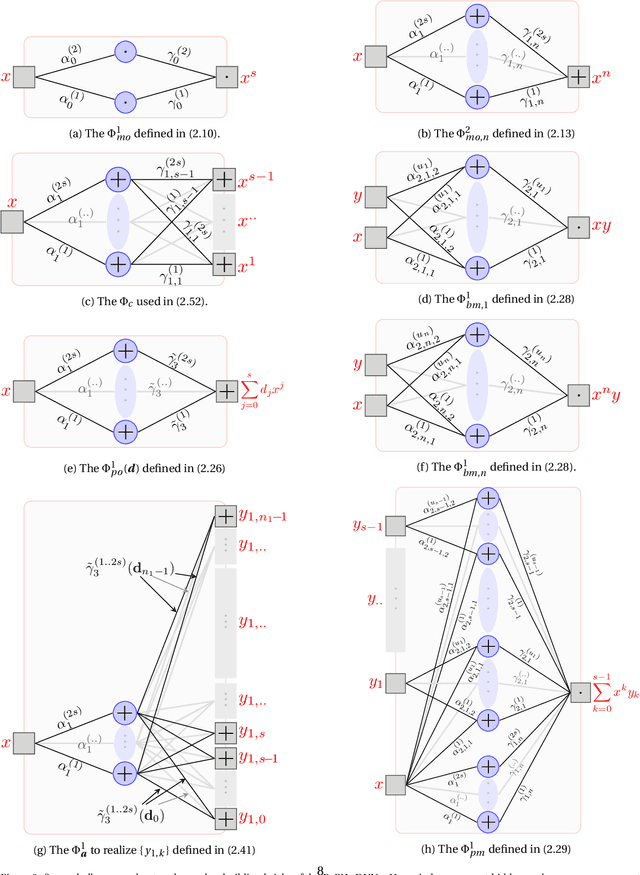
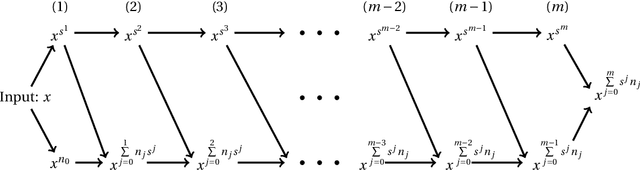
Deep neural network with rectified linear units (ReLU) is getting more and more popular recently. However, the derivatives of the function represented by a ReLU network are not continuous, which limit the usage of ReLU network to situations only when smoothness is not required. In this paper, we construct deep neural networks with rectified power units (RePU), which can give better approximations for smooth functions. Optimal algorithms are proposed to explicitly build neural networks with sparsely connected RePUs, which we call PowerNets, to represent polynomials with no approximation error. For general smooth functions, we first project the function to their polynomial approximations, then use the proposed algorithms to construct corresponding PowerNets. Thus, the error of best polynomial approximation provides an upper bound of the best RePU network approximation error. For smooth functions in higher dimensional Sobolev spaces, we use fast spectral transforms for tensor-product grid and sparse grid discretization to get polynomial approximations. Our constructive algorithms show clearly a close connection between spectral methods and deep neural networks: a PowerNet with $n$ layers can exactly represent polynomials up to degree $s^n$, where $s$ is the power of RePUs. The proposed PowerNets have potential applications in the situations where high-accuracy is desired or smoothness is required.
Application of Bounded Total Variation Denoising in Urban Traffic Analysis
Aug 04, 2018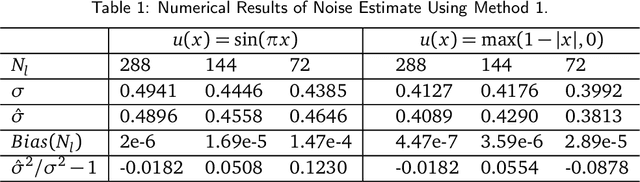
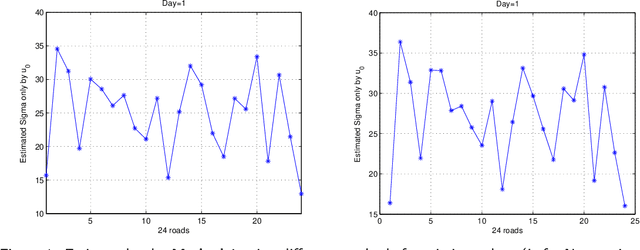
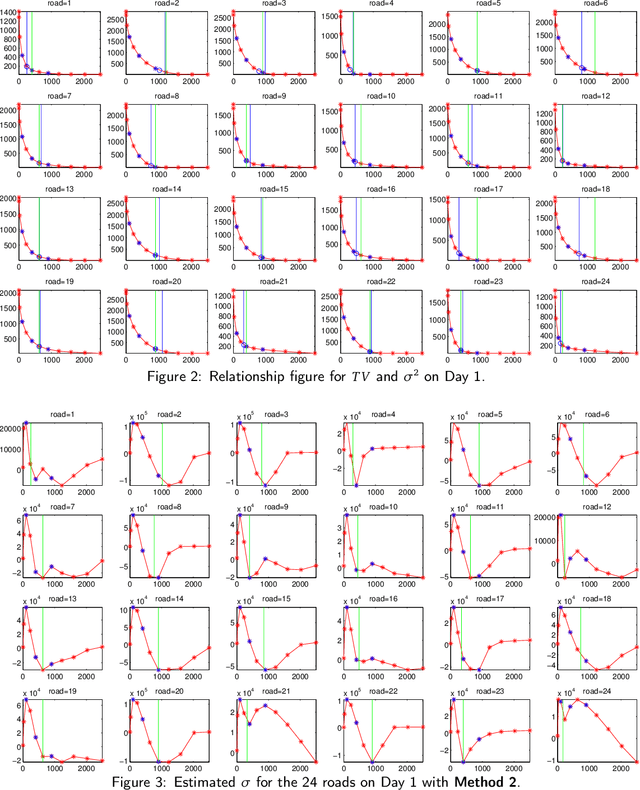
While it is believed that denoising is not always necessary in many big data applications, we show in this paper that denoising is helpful in urban traffic analysis by applying the method of bounded total variation denoising to the urban road traffic prediction and clustering problem. We propose two easy-to-implement methods to estimate the noise strength parameter in the denoising algorithm, and apply the denoising algorithm to GPS-based traffic data from Beijing taxi system. For the traffic prediction problem, we combine neural network and history matching method for roads randomly chosen from an urban area of Beijing. Numerical experiments show that the predicting accuracy is improved significantly by applying the proposed bounded total variation denoising algorithm. We also test the algorithm on clustering problem, where a recently developed clustering analysis method is applied to more than one hundred urban road segments in Beijing based on their velocity profiles. Better clustering result is obtained after denoising.