 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASTER: Multi-Aspect Non-local Network for Scene Text Recognition
Paper and Code

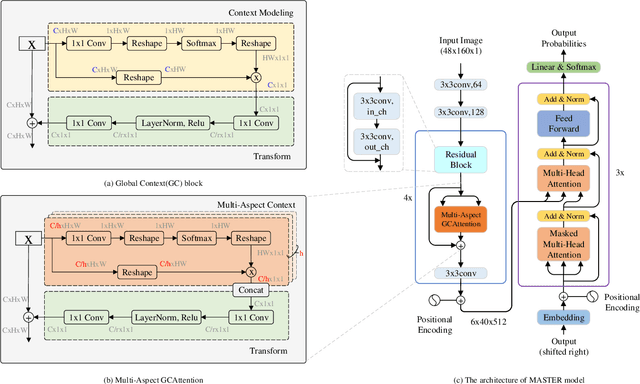


Attention based scene text recognizers have gained huge success, which leverage a more compact intermediate representations to learn 1d- or 2d- attention by a RNN-based encoder-decoder architecture. However, such methods suffer from attention-drift problem because high similarity among encoded features lead to attention confusion under the RNN-based local attention mechanism. Moreover RNN-based methods have low efficiency due to poor parallelization. To overcome these problems, we propose the MASTER, a self-attention based scene text recognizer that (1) not only encodes the input-output attention, but also learns self-attention which encodes feature-feature and target-target relationships inside the encoder and decoder and (2) learns a more powerful and robust intermediate representation to spatial distortion and (3) owns a better training and evaluation efficiency. Extensive experiments on various benchmarks demonstrate the superior performance of our MASTER on both regular and irregular scene text.