 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks
Paper and Code

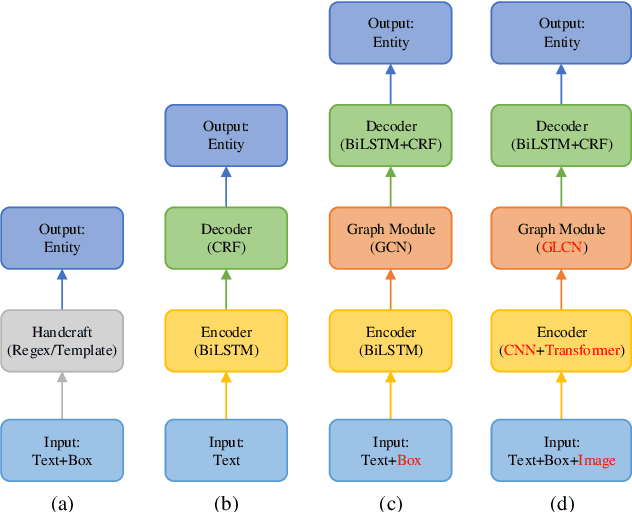
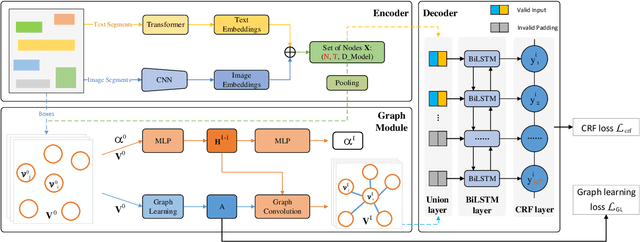
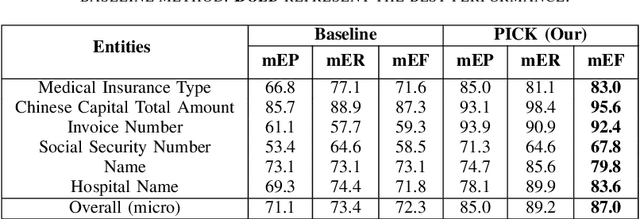
Computer vision with state-of-the-art deep learning models has achieved huge success in the field of Optical Character Recognition (OCR) including text detection and recognition tasks recently. However, Key Information Extraction (KIE) from documents as the downstream task of OCR, having a large number of use scenarios in real-world, remains a challenge because documents not only have textual features extracting from OCR systems but also have semantic visual features that are not fully exploited and play a critical role in KIE. Too little work has been devoted to efficiently make full use of both textual and visual features of the documents. In this paper, we introduce PICK, a framework that is effective and robust in handling complex documents layout for KIE by combining graph learning with graph convolution operation, yielding a richer semantic representation containing the textual and visual features and global layout without ambiguity. Extensive experiments on real-world datasets have been conducted to show that our method outperforms baselines methods by significant margins.