 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePianoBART: Symbolic Piano Music Generation and Understanding with Large-Scale Pre-Training
Jun 26, 2024



Learning musical structures and composition patterns is necessary for both music generation and understanding, but current methods do not make uniform use of learned features to generate and comprehend music simultaneously. In this paper, we propose PianoBART, a pre-trained model that uses BART for both symbolic piano music generation and understanding. We devise a multi-level object selection strategy for different pre-training tasks of PianoBART, which can prevent information leakage or loss and enhance learning ability. The musical semantics captured in pre-training are fine-tuned for music generation and understanding tasks. Experiments demonstrate that PianoBART efficiently learns musical patterns and achieves outstanding performance in generating high-quality coherent pieces and comprehending music. Our code and supplementary material are available at https://github.com/RS2002/PianoBart.
CAP-VSTNet: Content Affinity Preserved Versatile Style Transfer
Mar 31, 2023Content affinity loss including feature and pixel affinity is a main problem which leads to artifacts in photorealistic and video style transfer. This paper proposes a new framework named CAP-VSTNet, which consists of a new reversible residual network and an unbiased linear transform module, for versatile style transfer. This reversible residual network can not only preserve content affinity but not introduce redundant information as traditional reversible networks, and hence facilitate better stylization. Empowered by Matting Laplacian training loss which can address the pixel affinity loss problem led by the linear transform, the proposed framework is applicable and effective on versatile style transfer. Extensive experiments show that CAP-VSTNet can produce better qualitative and quantitative results in comparison with the state-of-the-art methods.
SketchyCOCO: Image Generation from Freehand Scene Sketches
Apr 07, 2020
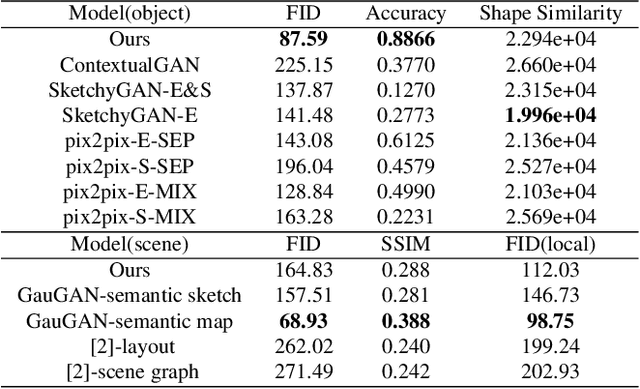
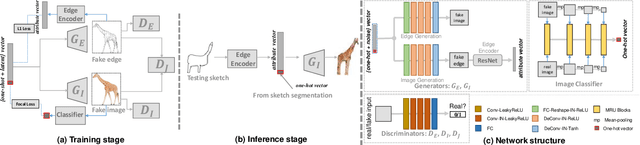
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged Generative Adversarial Network called EdgeGAN, which supports high visual-quality object-level image content generation without using freehand sketches as training data. We have built a large-scale composite dataset called SketchyCOCO to support and evaluate the solution. We validate our approach on the tasks of both object-level and scene-level image generation on SketchyCOCO. Through quantitative, qualitative results, human evaluation and ablation studies, we demonstrate the method's capacity to generate realistic complex scene-level images from various freehand sketches.
UPC: Learning Universal Physical Camouflage Attacks on Object Detectors
Sep 10, 2019

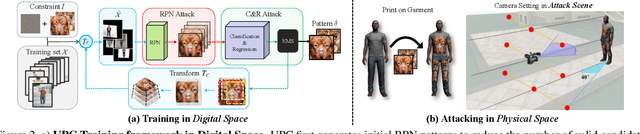
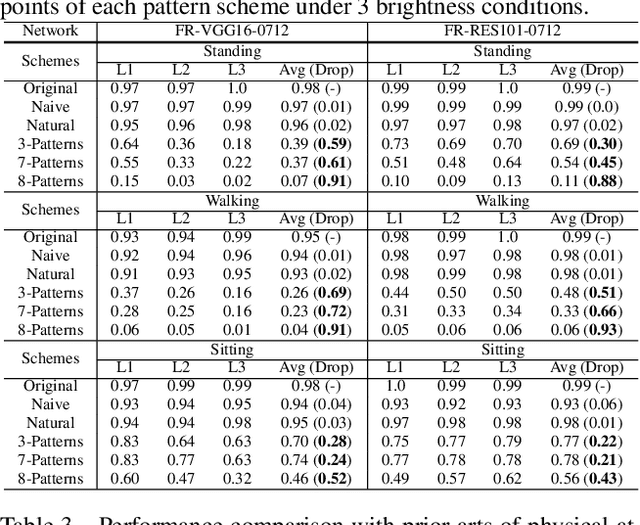
In this paper, we study physical adversarial attacks on object detectors in the wild. Prior arts on this matter mostly craft instance-dependent perturbations only for rigid and planar objects. To this end, we propose to learn an adversarial pattern to effectively attack all instances belonging to the same object category (e.g., person, car), referred to as Universal Physical Camouflage Attack (UPC). Concretely, UPC crafts camouflage by jointly fooling the region proposal network, as well as misleading the classifier and the regressor to output errors. In order to make UPC effective for articulated non-rigid or non-planar objects, we introduce a set of transformations for the generated camouflage patterns to mimic their deformable properties. We additionally impose optimization constraint to make generated patterns look natural for human observers. To fairly evaluate the effectiveness of different physical-world attacks on object detectors, we present the first standardized virtual database, AttackScenes, which simulates the real 3D world in a controllable and reproducible environment. Extensive experiments suggest the superiority of our proposed UPC compared with existing physical adversarial attackers not only in virtual environments (AttackScenes), but also in real-world physical environments. Codes, models, and demos are publicly available at https://mesunhlf.github.io/index_physical.html.
LUCSS: Language-based User-customized Colourization of Scene Sketches
Aug 30, 2018
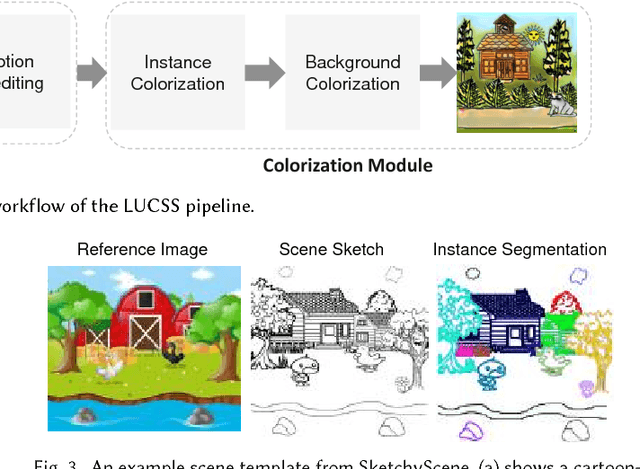
We introduce LUCSS, a language-based system for interactive col- orization of scene sketches, based on their semantic understanding. LUCSS is built upon deep neural networks trained via a large-scale repository of scene sketches and cartoon-style color images with text descriptions. It con- sists of three sequential modules. First, given a scene sketch, the segmenta- tion module automatically partitions an input sketch into individual object instances. Next, the captioning module generates the text description with spatial relationships based on the instance-level segmentation results. Fi- nally, the interactive colorization module allows users to edit the caption and produce colored images based on the altered caption. Our experiments show the effectiveness of our approach and the desirability of its compo- nents to alternative choices.
SketchyScene: Richly-Annotated Scene Sketches
Aug 07, 2018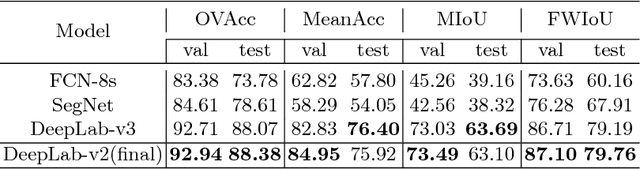

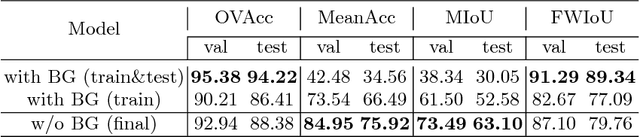
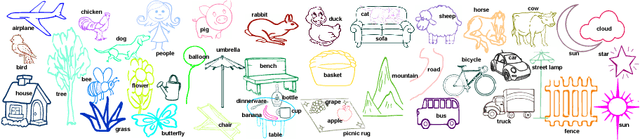
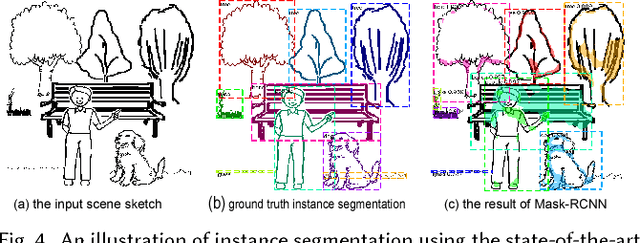
We contribute the first large-scale dataset of scene sketches, SketchyScene, with the goal of advancing research on sketch understanding at both the object and scene level. The dataset is created through a novel and carefully designed crowdsourcing pipeline, enabling users to efficiently generate large quantities of realistic and diverse scene sketches. SketchyScene contains more than 29,000 scene-level sketches, 7,000+ pairs of scene templates and photos, and 11,000+ object sketches. All objects in the scene sketches have ground-truth semantic and instance masks. The dataset is also highly scalable and extensible, easily allowing augmenting and/or changing scene composition. We demonstrate the potential impact of SketchyScene by training new computational models for semantic segmentation of scene sketches and showing how the new dataset enables several applications including image retrieval, sketch colorization, editing, and captioning, etc. The dataset and code can be found at https://github.com/SketchyScene/SketchyScene.