 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA topological solution to object segmentation and tracking
Jul 05, 2021The world is composed of objects, the ground, and the sky. Visual perception of objects requires solving two fundamental challenges: segmenting visual input into discrete units, and tracking identities of these units despite appearance changes due to object deformation, changing perspective, and dynamic occlusion. Current computer vision approaches to segmentation and tracking that approach human performance all require learning, raising the question: can objects be segmented and tracked without learning? Here, we show that the mathematical structure of light rays reflected from environment surfaces yields a natural representation of persistent surfaces, and this surface representation provides a solution to both the segmentation and tracking problems. We describe how to generate this surface representation from continuous visual input, and demonstrate that our approach can segment and invariantly track objects in cluttered synthetic video despite severe appearance changes, without requiring learning.
Neural Networks with Recurrent Generative Feedback
Jul 17, 2020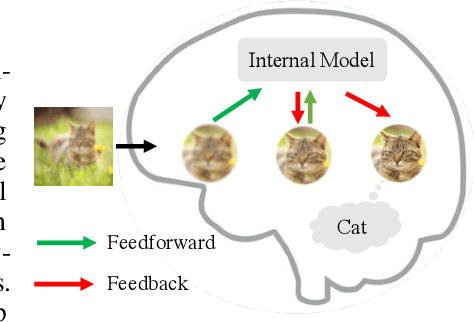

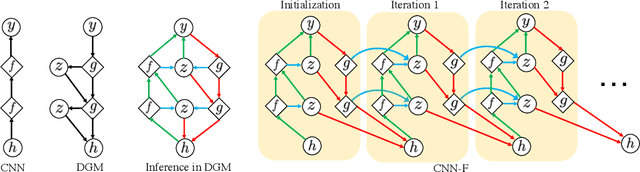
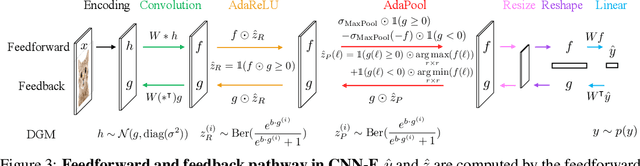
Neural networks are vulnerable to input perturbations such as additive noise and adversarial attacks. In contrast, human perception is much more robust to such perturbations. The Bayesian brain hypothesis states that human brains use an internal generative model to update the posterior beliefs of the sensory input. This mechanism can be interpreted as a form of self-consistency between the maximum a posteriori (MAP) estimation of the internal generative model and the external environmental. Inspired by this, we enforce consistency in neural networks by incorporating generative recurrent feedback. We instantiate it on convolutional neural networks (CNNs). The proposed framework, termed Convolutional Neural Networks with Feedback (CNN-F), introduces a generative feedback with latent variables into existing CNN architectures, making consistent predictions via alternating MAP inference under a Bayesian framework. CNN-F shows considerably better adversarial robustness over regular feedforward CNNs on standard benchmarks. In addition, With higher V4 and IT neural predictivity, CNN-F produces object representations closer to primate vision than conventional CNNs.