Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity of Generative VLMs to Semantically and Lexically Altered Prompts
Paper and Code
Oct 16, 2024

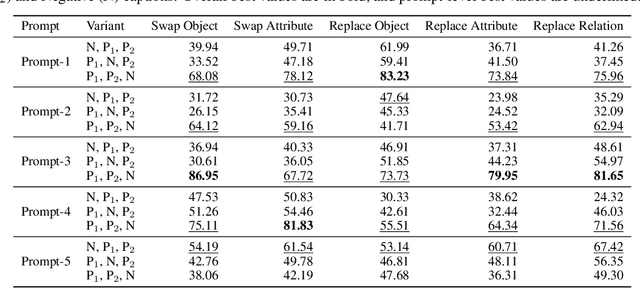
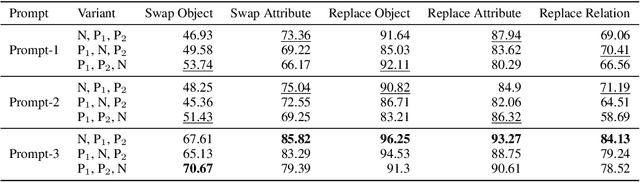
Despite the significant influx of prompt-tuning techniques for generative vision-language models (VLMs), it remains unclear how sensitive these models are to lexical and semantic alterations in prompts. In this paper, we evaluate the ability of generative VLMs to understand lexical and semantic changes in text using the SugarCrepe++ dataset. We analyze the sensitivity of VLMs to lexical alterations in prompts without corresponding semantic changes. Our findings demonstrate that generative VLMs are highly sensitive to such alterations. Additionally, we show that this vulnerability affects the performance of techniques aimed at achieving consistency in their outputs.
View paper on