 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisttack: Graph Adversarial Attacks Toward Distributed GNN Training
Paper and Code
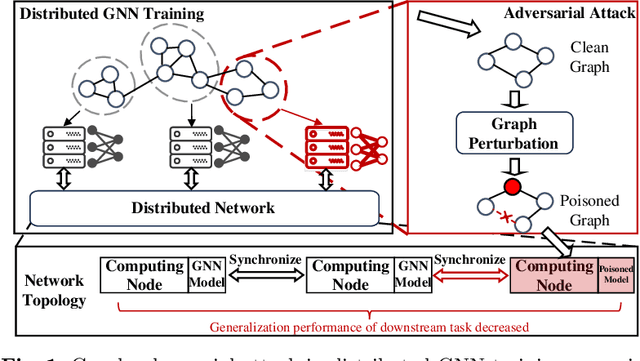
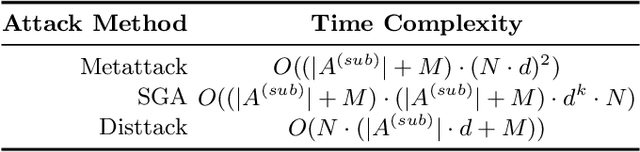
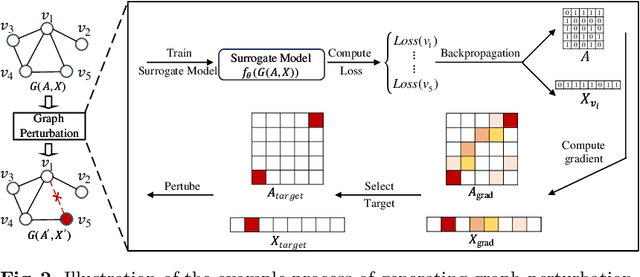
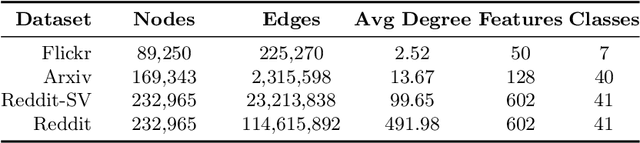
Graph Neural Networks (GNNs) have emerged as potent models for graph learning. Distributing the training process across multiple computing nodes is the most promising solution to address the challenges of ever-growing real-world graphs. However, current adversarial attack methods on GNNs neglect the characteristics and applications of the distributed scenario, leading to suboptimal performance and inefficiency in attacking distributed GNN training. In this study, we introduce Disttack, the first framework of adversarial attacks for distributed GNN training that leverages the characteristics of frequent gradient updates in a distributed system. Specifically, Disttack corrupts distributed GNN training by injecting adversarial attacks into one single computing node. The attacked subgraphs are precisely perturbed to induce an abnormal gradient ascent in backpropagation, disrupting gradient synchronization between computing nodes and thus leading to a significant performance decline of the trained GNN. We evaluate Disttack on four large real-world graphs by attacking five widely adopted GNNs. Compared with the state-of-the-art attack method, experimental results demonstrate that Disttack amplifies the model accuracy degradation by 2.75$\times$ and achieves speedup by 17.33$\times$ on average while maintaining unnoticeability.