 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$I^2G$: Generating Instructional Illustrations via Text-Conditioned Diffusion
May 22, 2025
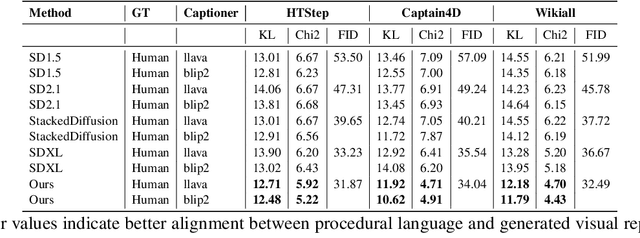
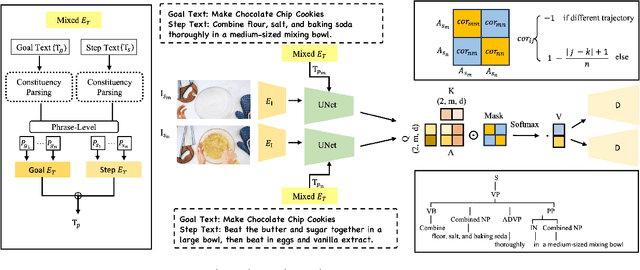
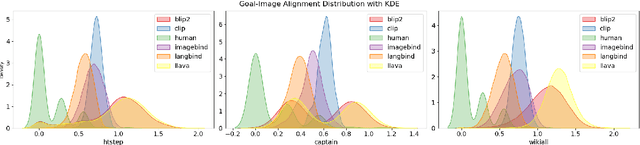
The effective communication of procedural knowledge remains a significant challenge in natural language processing (NLP), as purely textual instructions often fail to convey complex physical actions and spatial relationships. We address this limitation by proposing a language-driven framework that translates procedural text into coherent visual instructions. Our approach models the linguistic structure of instructional content by decomposing it into goal statements and sequential steps, then conditioning visual generation on these linguistic elements. We introduce three key innovations: (1) a constituency parser-based text encoding mechanism that preserves semantic completeness even with lengthy instructions, (2) a pairwise discourse coherence model that maintains consistency across instruction sequences, and (3) a novel evaluation protocol specifically designed for procedural language-to-image alignment. Our experiments across three instructional datasets (HTStep, CaptainCook4D, and WikiAll) demonstrate that our method significantly outperforms existing baselines in generating visuals that accurately reflect the linguistic content and sequential nature of instructions. This work contributes to the growing body of research on grounding procedural language in visual content, with applications spanning education, task guidance, and multimodal language understanding.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
Apr 04, 2025
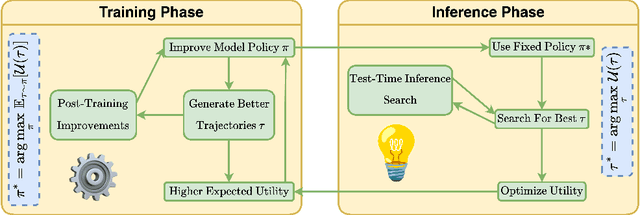
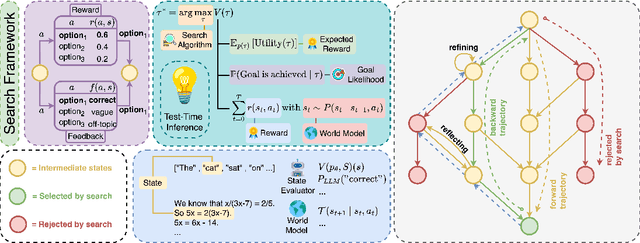
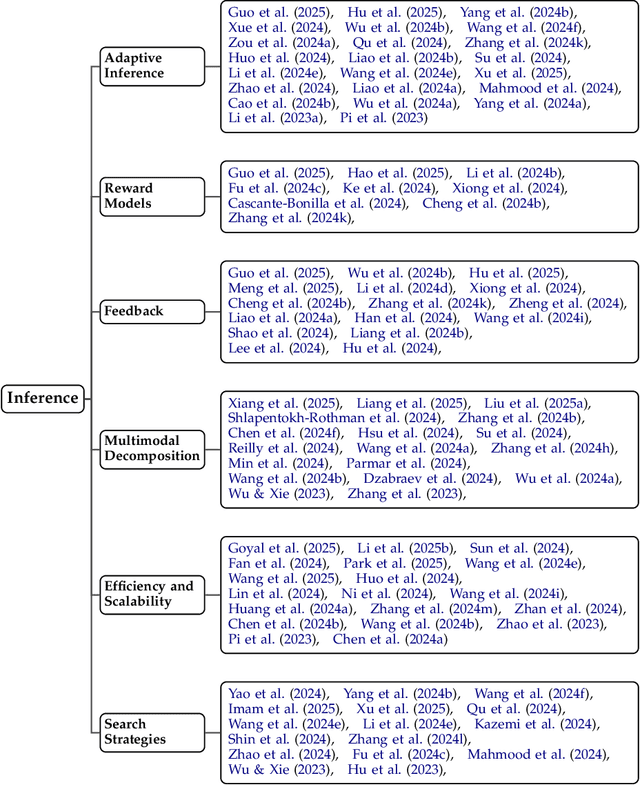
Reasoning is central to human intelligence, enabling structured problem-solving across diverse tasks. Recent advances in large language models (LLMs) have greatly enhanced their reasoning abilities in arithmetic, commonsense, and symbolic domains. However, effectively extending these capabilities into multimodal contexts-where models must integrate both visual and textual inputs-continues to be a significant challenge. Multimodal reasoning introduces complexities, such as handling conflicting information across modalities, which require models to adopt advanced interpretative strategies. Addressing these challenges involves not only sophisticated algorithms but also robust methodologies for evaluating reasoning accuracy and coherence. This paper offers a concise yet insightful overview of reasoning techniques in both textual and multimodal LLMs. Through a thorough and up-to-date comparison, we clearly formulate core reasoning challenges and opportunities, highlighting practical methods for post-training optimization and test-time inference. Our work provides valuable insights and guidance, bridging theoretical frameworks and practical implementations, and sets clear directions for future research.
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Mar 14, 2025Visual reasoning is central to human cognition, enabling individuals to interpret and abstractly understand their environment. Although recent Multimodal Large Language Models (MLLMs) have demonstrated impressive performance across language and vision-language tasks, existing benchmarks primarily measure recognition-based skills and inadequately assess true visual reasoning capabilities. To bridge this critical gap, we introduce VERIFY, a benchmark explicitly designed to isolate and rigorously evaluate the visual reasoning capabilities of state-of-the-art MLLMs. VERIFY compels models to reason primarily from visual information, providing minimal textual context to reduce reliance on domain-specific knowledge and linguistic biases. Each problem is accompanied by a human-annotated reasoning path, making it the first to provide in-depth evaluation of model decision-making processes. Additionally, we propose novel metrics that assess visual reasoning fidelity beyond mere accuracy, highlighting critical imbalances in current model reasoning patterns. Our comprehensive benchmarking of leading MLLMs uncovers significant limitations, underscoring the need for a balanced and holistic approach to both perception and reasoning. For more teaser and testing, visit our project page (https://verify-eqh.pages.dev/).