 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Paper and Code
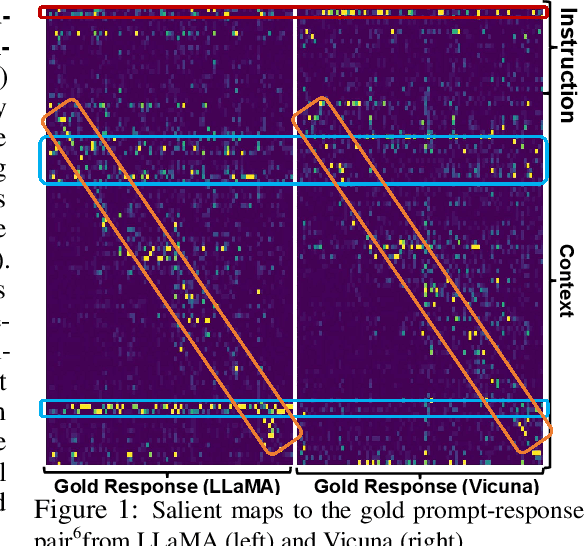

Large Language Models (LLMs) have achieved remarkable success, demonstrating powerful instruction-following capabilities across diverse tasks. Instruction fine-tuning is critical in enabling LLMs to align with user intentions and effectively follow instructions. In this work, we investigate how instruction fine-tuning modifies pre-trained models, focusing on two perspectives: instruction recognition and knowledge evolution. To study the behavior shift of LLMs, we employ a suite of local and global explanation methods, including a gradient-based approach for input-output attribution and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. Our findings reveal three significant impacts of instruction fine-tuning: 1) It empowers LLMs to better recognize the instruction parts from user prompts, thereby facilitating high-quality response generation and addressing the ``lost-in-the-middle'' issue observed in pre-trained models; 2) It aligns the knowledge stored in feed-forward layers with user-oriented tasks, exhibiting minimal shifts across linguistic levels. 3) It facilitates the learning of word-word relations with instruction verbs through the self-attention mechanism, particularly in the lower and middle layers, indicating enhanced recognition of instruction words. These insights contribute to a deeper understanding of the behavior shifts in LLMs after instruction fine-tuning and lay the groundwork for future research aimed at interpreting and optimizing LLMs for various applications. We will release our code and data soon.