 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Privacy in Hierarchical Federated Learning: A Formal Analysis and Evaluation
Paper and Code
Jan 21, 2024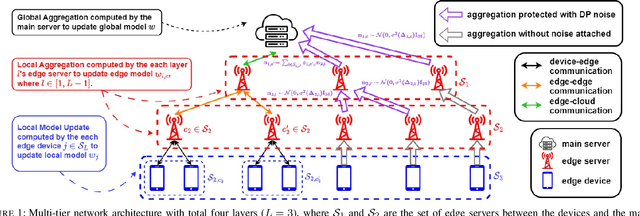
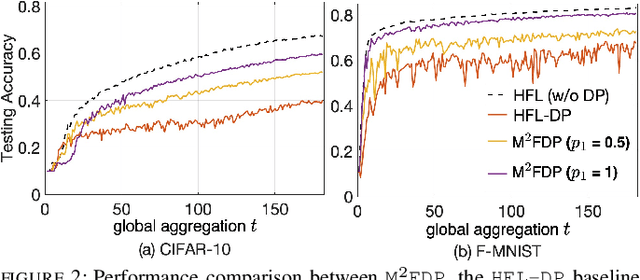
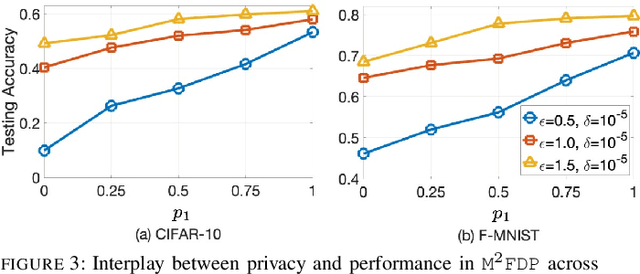
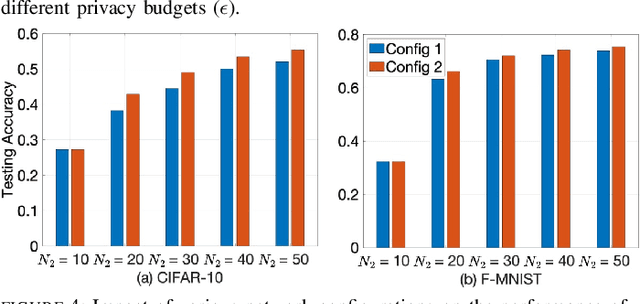
While federated learning (FL) eliminates the transmission of raw data over a network, it is still vulnerable to privacy breaches from the communicated model parameters. In this work, we formalize Differentially Private Hierarchical Federated Learning (DP-HFL), a DP-enhanced FL methodology that seeks to improve the privacy-utility tradeoff inherent in FL. Building upon recent proposals for Hierarchical Differential Privacy (HDP), one of the key concepts of DP-HFL is adapting DP noise injection at different layers of an established FL hierarchy -- edge devices, edge servers, and cloud servers -- according to the trust models within particular subnetworks. We conduct a comprehensive analysis of the convergence behavior of DP-HFL, revealing conditions on parameter tuning under which the model training process converges sublinearly to a stationarity gap, with this gap depending on the network hierarchy, trust model, and target privacy level. Subsequent numerical evaluations demonstrate that DP-HFL obtains substantial improvements in convergence speed over baselines for different privacy budgets, and validate the impact of network configuration on training.